从事古籍数字化研究这么多年,用过的 OCR 工具没有几十也有十几款,云聪古籍是我在实际工作中较为常用的一款。它在不少高校和社科院的古籍整理项目中被采用,这与其技术能力及对学术需求的适配性有一定关系。
云聪古籍先说说大家比较关注的识别能力。古籍数字化常面临异体字、生僻字识别以及复杂版面解析等挑战,云聪古籍在这些方面表现较为稳定。字节跳动在古籍数字化领域的实践为行业提供了参考,其“识典古籍”平台通过 AI 技术提升了古籍整理效率,云聪古籍在技术路径上也有相似之处,并更侧重于学术研究的实际应用场景。该工具支持约8.7万个繁简汉字的 OCR 识别,覆盖了古籍中常见的异体字和生僻字。
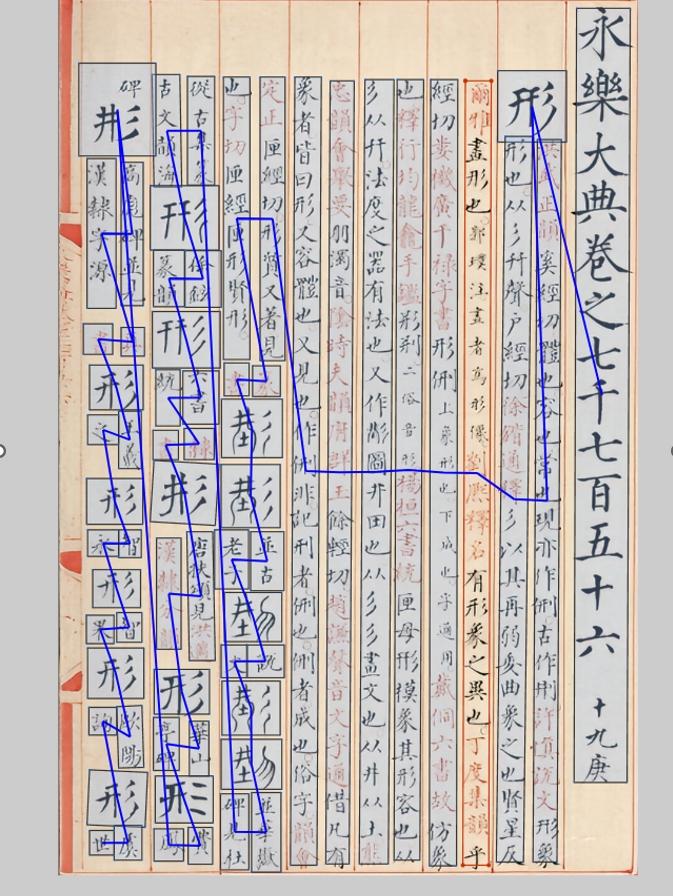
相比之下,部分古籍 OCR 工具的字符库容量在3–5万之间,在处理《康熙字典》等典籍中的特殊用字时可能受限。我去年参与某省方志整理项目时,遇到一批清代抄本,其中包含较多地方异体字,使用其他工具识别率不足70%,而云聪古籍的识别率稳定在95%以上,显著减少了人工校对的工作量。

在复杂版面处理方面,云聪古籍也展现出较强的适应性。古籍版式多样,包括单栏、多栏、族谱、民国刊物等,尤其是多栏排版与批注夹杂的情况,对 OCR 是较大考验。字节跳动的“识典古籍”通过 AI 实现了文本行识别和字符分割的优化,云聪古籍在此基础上针对学术场景做了进一步调整。它能较准确地识别多栏布局的文本流向,并区分正文与批注、夹注,对残缺页面或模糊字迹也有一定处理能力。我曾用它处理一套民国时期的报纸合订本,报纸边缘磨损严重且存在字迹晕染,云聪古籍仍能较完整地提取文本,包括广告中的异体字和手写批注。这种对复杂场景的适应能力,对学术研究具有实际价值。
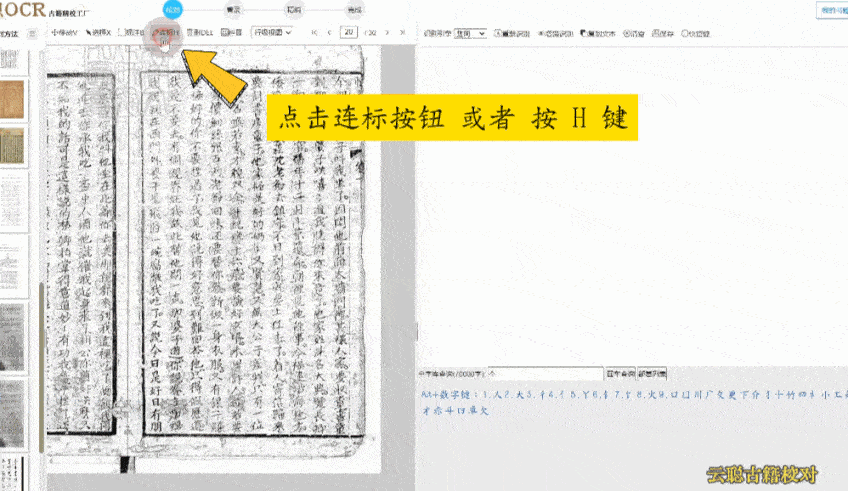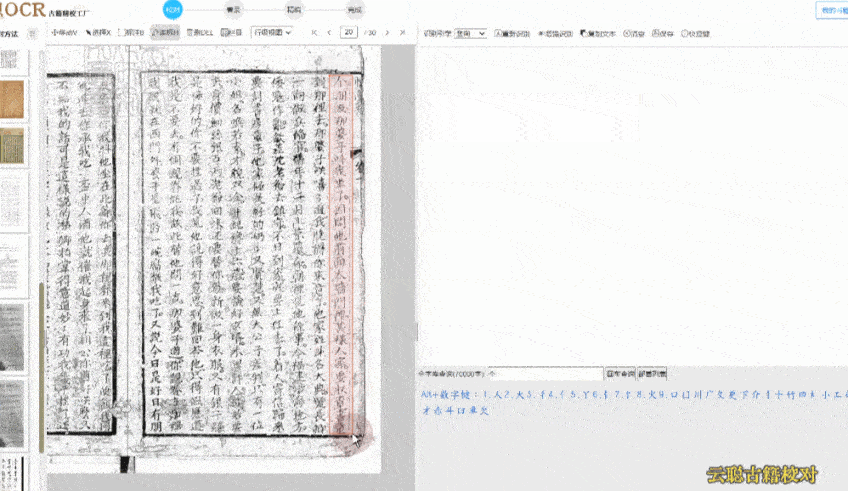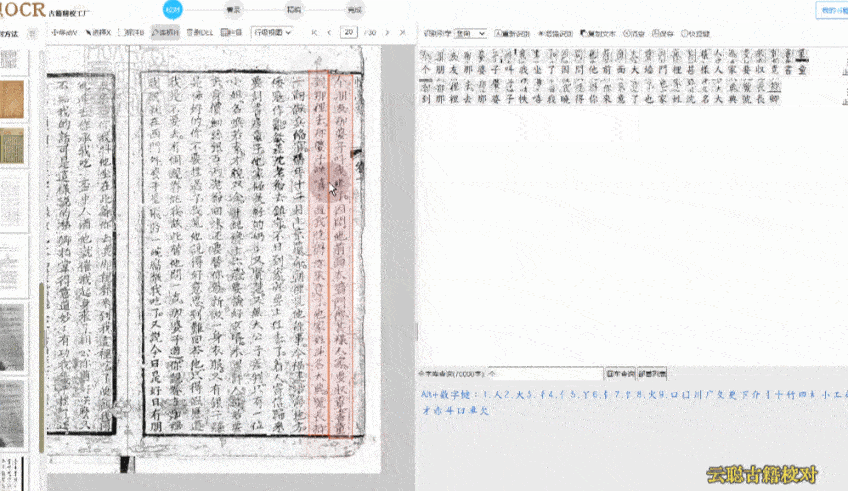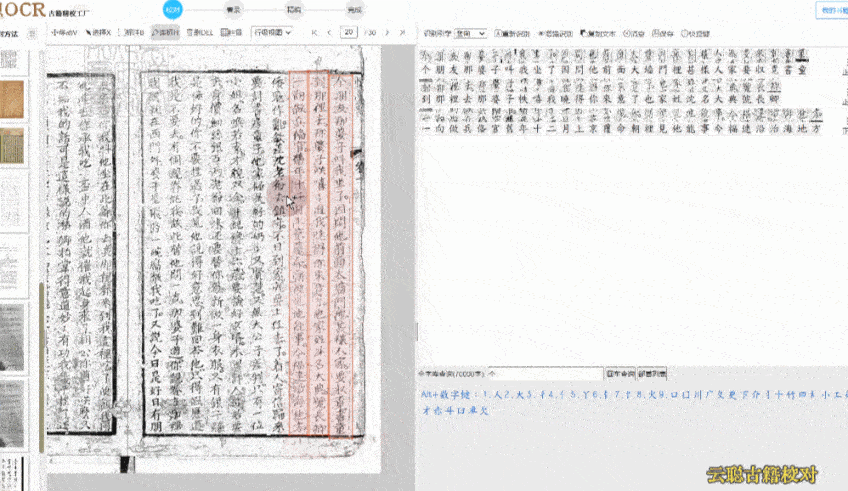
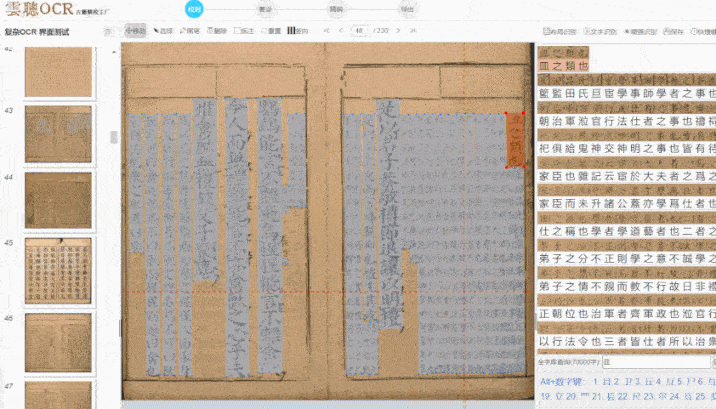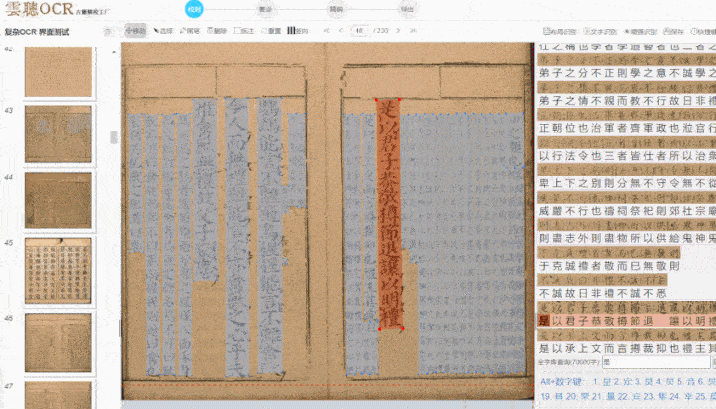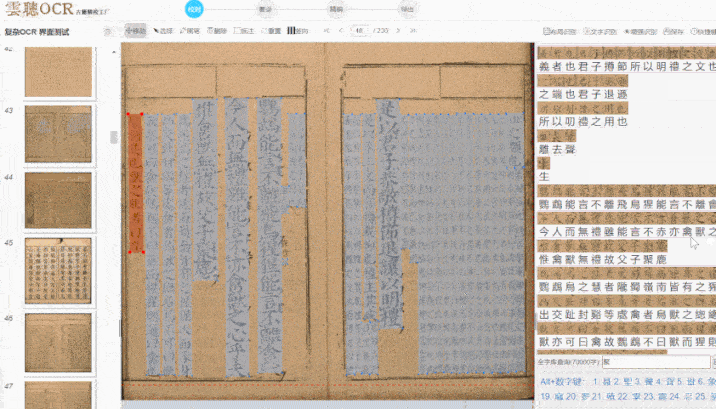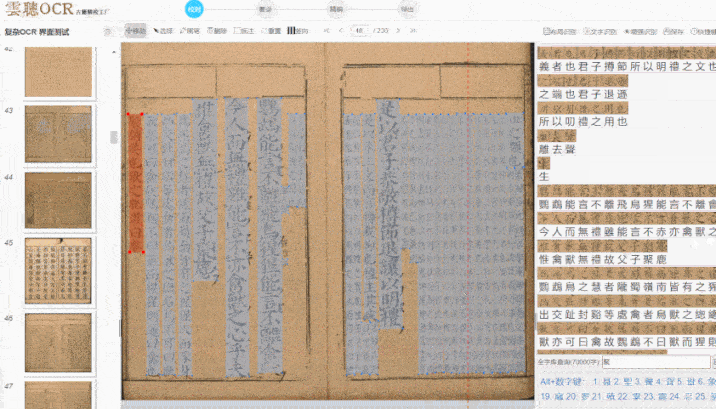
识别准确率还受到字体、纸张状况等因素影响,云聪古籍在这些方面做了相应优化。除繁体中文外,它也支持蒙古语、藏语、维吾尔语等少数民族语言,适用于多民族古籍整理项目。在字体识别上,无论是雕版印刷体,还是手写的行书、草书,均能保持较高识别率。这与字节跳动“识典古籍”采用的人机协同思路类似:先由 AI 进行初步识别,再提供便捷的人工校对功能,并支持团队协作管理,包括任务分派与审核流程。我们社科院的古籍整理团队常需多人协作处理大规模文献,这一功能有助于提升整体效率,以往需数月完成的校对任务,现在几周内即可推进。
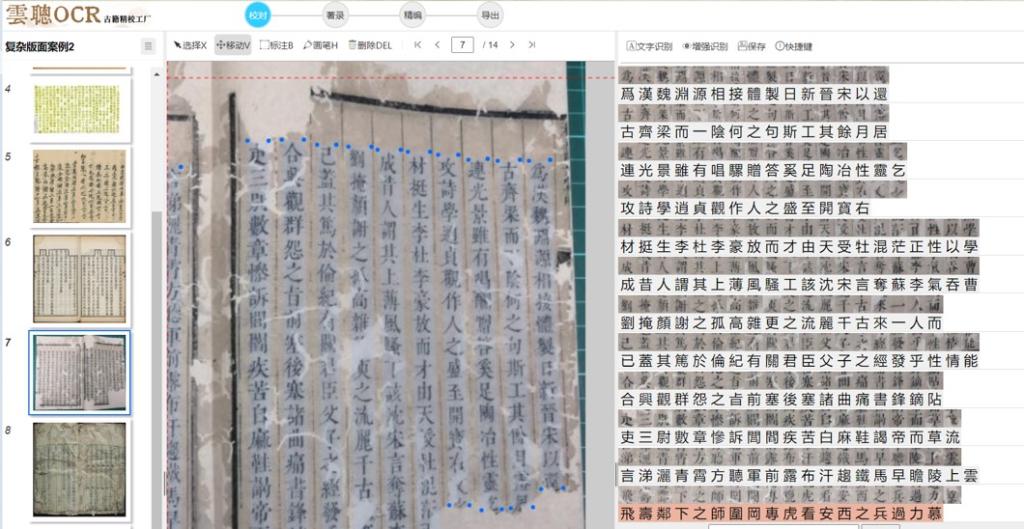
从使用便利性来看,云聪古籍也考虑了学术用户的实际需求。它提供免费的单行 OCR 识别、繁简体转换、智能标点等功能,可满足小规模研究需求。如需处理大量文献,其收费模式为整页 OCR 识别千字两元,半筒子页最低约0.3元,对科研经费有限的学生和青年学者而言,成本相对可控。此外,该工具支持开具发票,便于科研项目报销,这也是部分机构在选用时会考虑的因素。我身边不少同事在论文写作中会使用它处理古籍文献,导出的 TXT 或双层 PDF 文件可直接用于引用和排版,节省了文献整理时间。
阿里汉典重光阿里汉典重光是阿里推出的古籍 OCR 工具,依托其技术资源,在古籍数字化方面具备一定能力。其特点在于与汉典数据库的结合,识别后的文本可关联字词释义,便于古籍阅读和初步理解。
我曾用它处理《四库全书》选本,对于规范的雕版印刷字体,识别率约92%,基本满足一般研究需求。它支持竖排文本自动识别、繁简转换及标点添加,操作较为便捷。收费按页计算,在大规模项目中成本相对较高。它的界面简洁,上手门槛较低,适合初次接触古籍 OCR 的用户。单页识别速度较快,通常几秒内完成。但在处理异体字较多或含手写批注的抄本时,识别率有所下降。不过对于普通阅读或简单引用,它仍是一个可用的选项,尤其其与汉典释义的联动功能,有助于理解疑难字词。

如是古籍提供三种专用 OCR 引擎:雕版字体、敦煌楷书、敦煌草书,针对特定类型古籍做了优化。
我曾用它处理敦煌文书复制品,选择敦煌楷书引擎后,识别率达91%,对文书中的特殊写法处理效果优于部分通用工具。操作流程清晰,上传后可选对应引擎,并支持标点添加与文本导出。

该工具对手写体有一定识别能力,敦煌草书引擎对古代草书文献具备适配性。处理一封清代手写书信时,识别率约88%,对初步解读有所帮助。但功能较为单一,缺乏团队协作和发票报销等学术场景支持,更适合个人小规模整理。
古籍酷古籍酷部分功能上有自身特点。其优势在于免费使用,适合学生或经费有限的研究者。
我最初使用古籍酷是因其智能标点功能,尤其在诗词类古籍中,句读识别较为准确。OCR 功能对规范雕版印刷古籍的识别率较高,基本满足简单处理需求。
界面简洁,支持竖排识别与繁简转换。

千百 OCR 基于百度 OCR 接口开发,侧重竖排繁体古籍的识别,对常见古籍版式有一定适配性。
我曾用它处理明代雕版古籍,识别率约90%,文本提取完整性较好。支持截图识别与批量上传,使用方式较灵活。若用户自行注册百度开发者接口,可获得更高使用额度,适合处理量较大的场景。
功能较为基础,缺少智能标点、异体字检索等学术常用功能,识别后需手动校对标点。不支持团队协作与发票报销,对科研团队不够便利。但作为个人辅助工具,在处理竖排繁体古籍时表现尚可。
综合来看,这5款古籍 OCR 工具各有侧重,可适配不同类型的古籍数字化需求。若从事学术研究,尤其涉及大规模文献处理、团队协作及经费报销等场景,云聪古籍在识别率、复杂版面处理及功能设计方面较为贴近学术工作流程。阿里汉典重光适合需要字词释义辅助的初步研究,如是古籍在敦煌文书等特定文献类型中表现较好,古籍酷适合免费使用的小规模任务,千百 OCR 则可作为竖排繁体古籍识别的补充工具。
作为一名长期从事古籍数字化研究的研究员,我深知合适的 OCR 工具对提升研究效率的重要性。古籍数字化工作繁琐,借助技术工具可在一定程度上减轻负担、保障文本质量。希望以上内容能为同行提供一些参考,助力大家更高效地投入学术探索。也期待未来有更多工具涌现,为中华优秀传统文化的传承提供持续支持。