[CL]《RLBFF: Binary Flexible Feedback to bridge between Human Feedback & Verifiable Rewards》Z Wang, J Zeng, O Delalleau, E Evans... [NVIDIA] (2025)
融合人类反馈与可验证奖励的优点,RLBFF开创二元灵活反馈新范式:
• 解决RLHF依赖模糊人类判断导致的可解释性差与奖励作弊问题,同时克服RLVR局限于正误判定的单一维度。
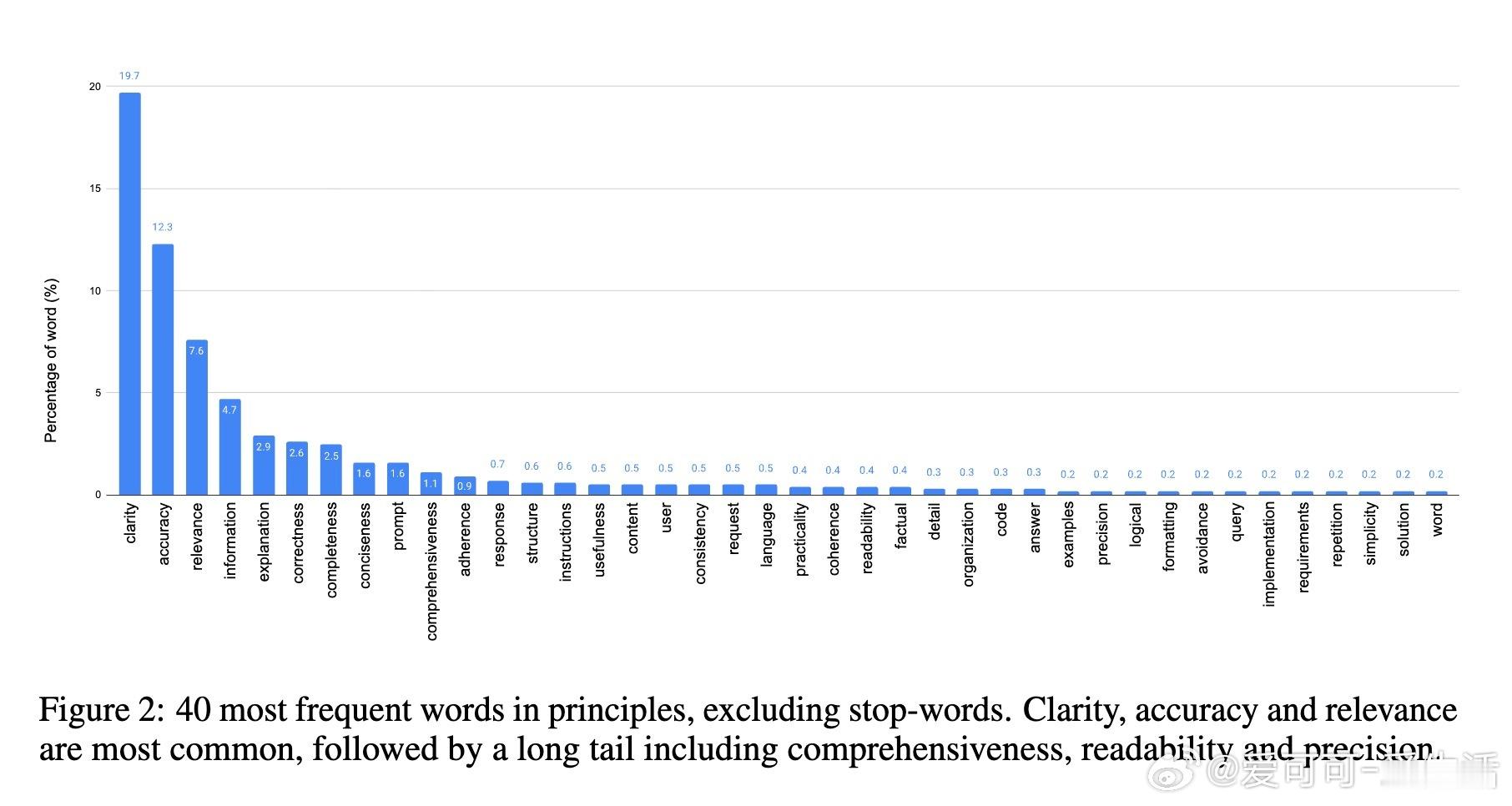
• 通过从自然语言反馈中提取可二元判断的“原则”(如信息准确性“是/否”、代码可读性“否”),将奖励建模转化为判定响应是否满足特定原则的蕴含任务。
• 支持用户在推断时自由指定关注原则,实现奖励模型定制化,超越传统Bradley-Terry模型的固定评价标准。
• 基于HelpSteer3数据集,训练出的奖励模型在RM-Bench(86.2%)与JudgeBench(81.4%,2025年9月24日冠军)表现领先,且在PrincipleBench新增基准中验证了对细粒度原则的遵循能力。
• 利用RLBFF技术对Qwen3-32B进行对齐训练,开源方案可匹敌甚至超越o3-mini和DeepSeek R1,在MT-Bench、WildBench及Arena Hard v2上表现优异,推理成本低于5%。
• 结合灵活原则标注与严格证据引用,显著减少模型幻觉与歧义,提升训练数据质量及奖励模型的稳定性和泛化能力。
• Scalar Reward Model高效推理仅需生成1个token,适合低延时场景;Generative Reward Model虽计算开销大,但因推理过程具备推理能力,适合复杂任务。
• PrincipleBench首次公开评测奖励模型对多元原则(如清晰度、无重复、语言对齐等)的遵守性,促进从仅关注正确性向全面质量评价转变。
心得:
1. 明确反馈背后的评价原则是提升奖励模型准确性的关键,避免了单一“好坏”标签的主观混淆。
2. 二元判断简化了标注难度,减少了评分尺度不一致带来的噪声,提高了模型的可解释性与稳定性。
3. 用户自定义原则使奖励模型更灵活,适应不同应用场景和需求,有助于实现更细致的人机协同。
更多详情🔗arxiv.org/abs/2509.21319
人工智能强化学习大语言模型人类反馈奖励建模模型对齐