[LG]《Learning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training》J Han, S Tong, D Fan, Y Ren... [Meta Superintelligence Labs] (2025)
大语言模型(LLMs)仅凭语言预训练就能“学会看”,具备惊人的视觉先验能力,这一发现彻底颠覆了传统认知。
• 视觉先验由两大独立组成部分构成:感知先验(perception prior)与推理先验(reasoning prior),二者来源及规模扩展规律迥异。
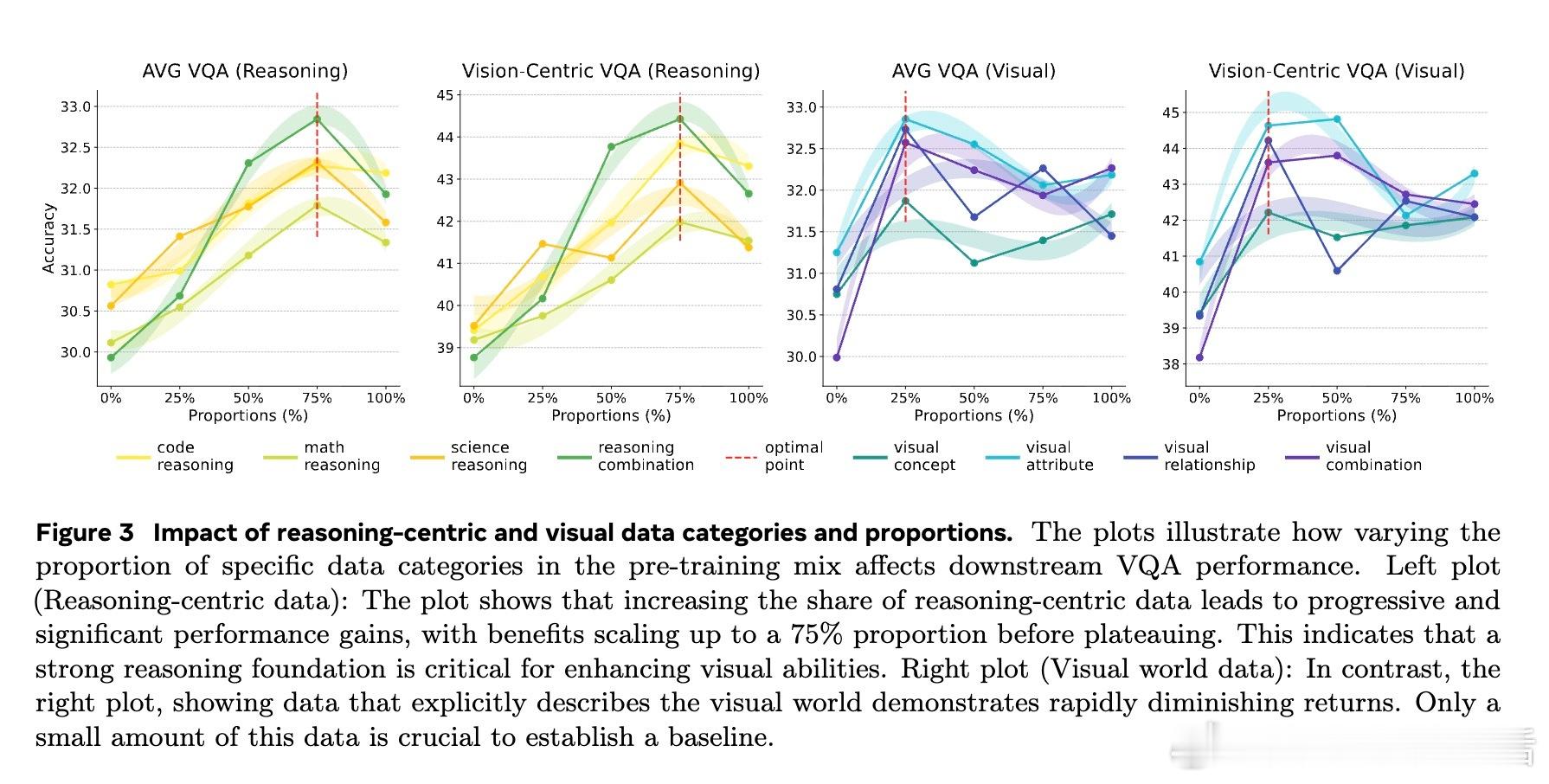
• 推理先验主要由推理类数据(如代码、数学、学术文献)驱动,且与模型规模和推理数据比例呈持续正相关,推理能力跨模态通用,可直接迁移至视觉推理任务。
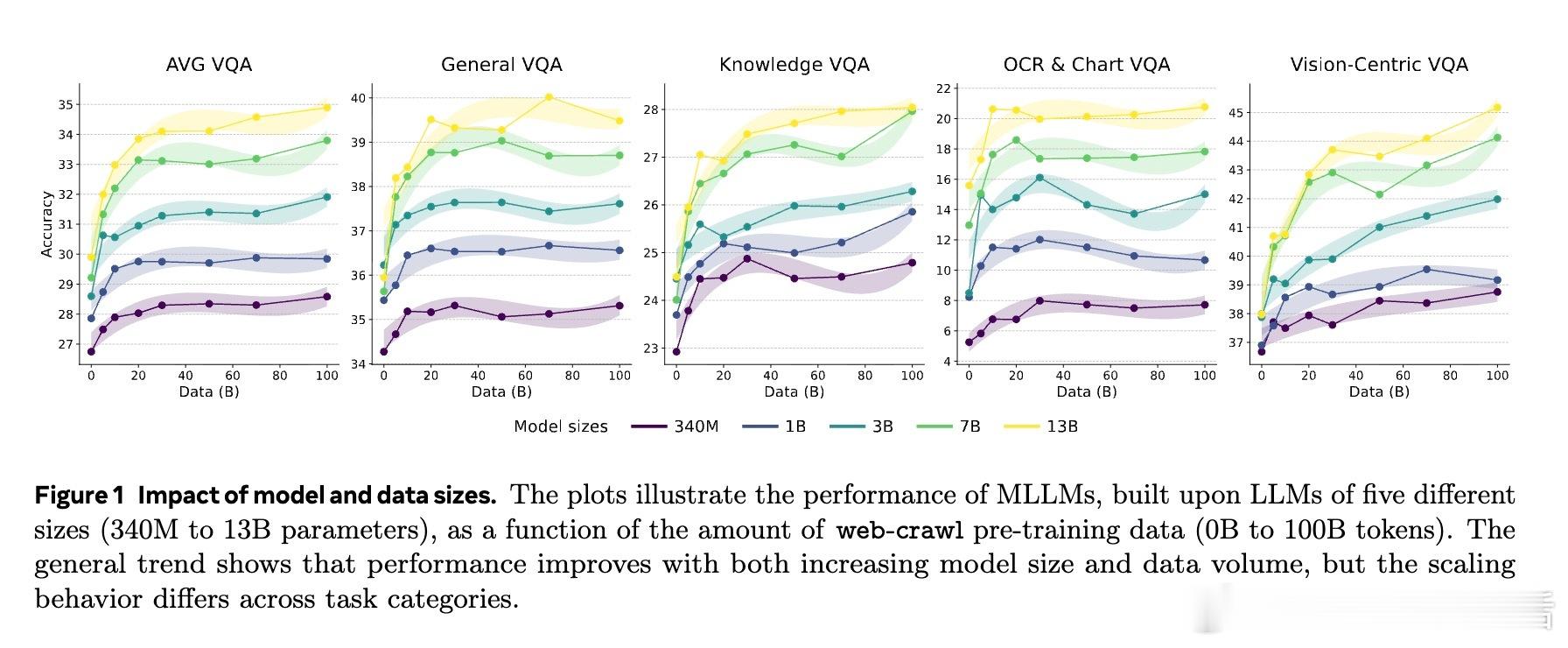
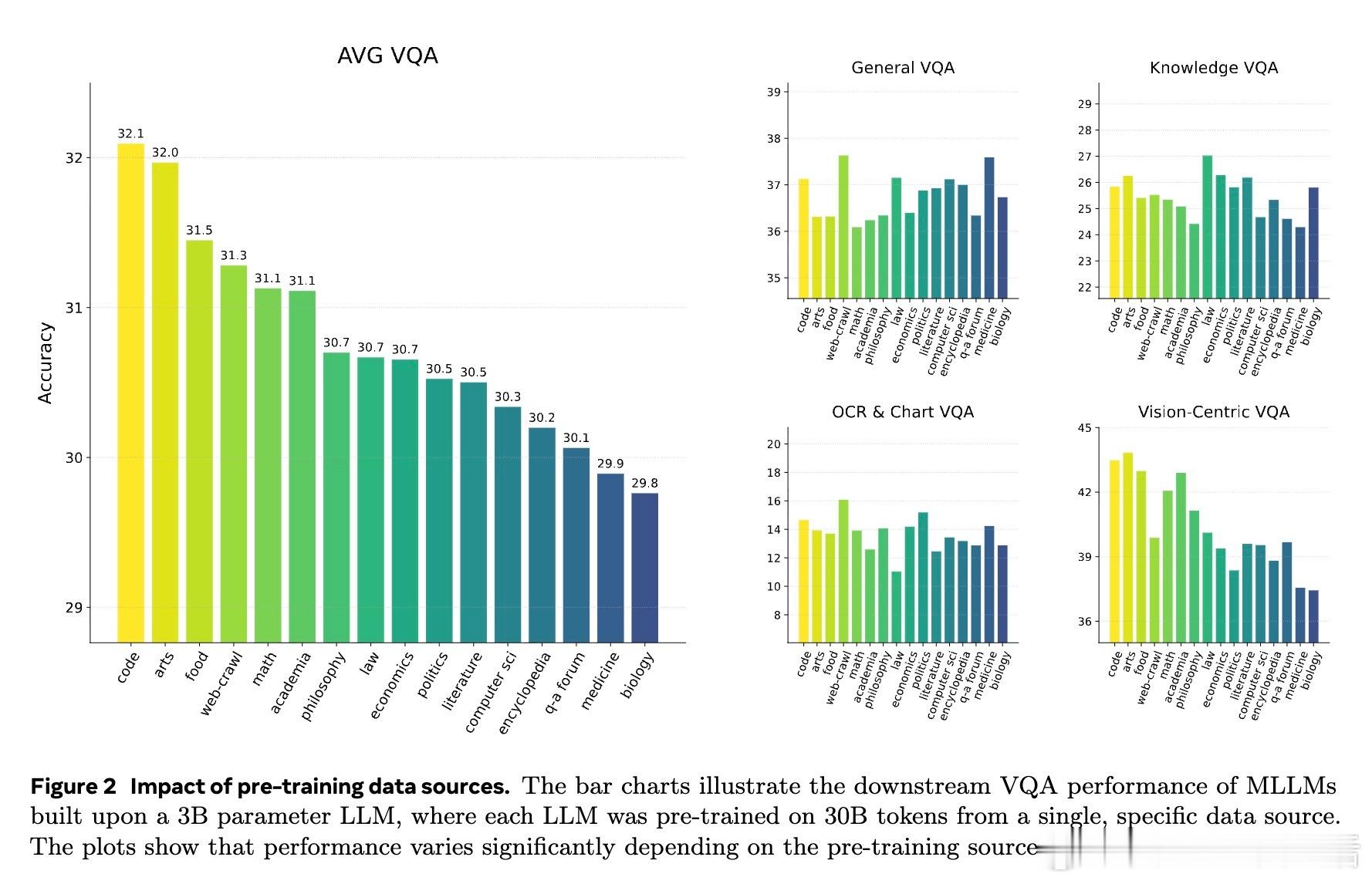
• 感知先验则更为分散,依赖多样化语言数据(尤其是大规模网络爬取文本),对视觉编码器及视觉指令微调数据敏感,且对小到中等尺寸视觉对象的感知提升尤为显著。
• 纯视觉编码器(如MetaCLIP、DINOv2)与LLM的结合中,推理能力表现出强普适性,而感知能力则依赖视觉编码器特性及后续视觉微调。
• 设计合理的数据混合策略(以约60%推理类数据+15%视觉描述类数据为最佳)可在不牺牲语言能力的同时,显著提升视觉问答(VQA)等多模态任务表现。
• 盲视觉指令调优(先无图像仅用文本指令预训练)是一种“捷径”,能强化模型利用语言先验解决视觉问题,但可能加剧幻觉风险。
• 本文开发的多层次存在基准(MLE-Bench)细致评估模型对不同尺寸视觉对象的感知能力,揭示了视觉先验的层级结构。
• 整体研究支持“柏拉图式表征假说”,即模型通过语言数据恢复了对现实世界的统一抽象表征,视觉与语言仅为该表征的不同投影。
心得:
1. 大模型视觉能力非偶然,而是语言预训练中隐含的结构化知识与推理能力的自然流露,提示多模态学习应从语言预训练阶段即开始有意识培养视觉先验。
2. 推理能力的跨模态迁移性极强,强调了推理核心结构的普适价值,未来多模态模型设计应强化结构性推理内容的预训练投入。
3. 感知能力提升依赖于多样且丰富的语言描述,尤其是细粒度视觉细节的语言表达,表明数据多样性和细节丰富性对于视觉感知模型训练至关重要。
🔗
详情🔗 junlinhan.github.io/projects/lsbs/
大语言模型多模态学习视觉先验推理能力机器学习人工智能


![完了我也成文盲了[捂脸哭]](http://image.uczzd.cn/13174481363879932073.jpg?id=0)
