[LG]《On the Role of Temperature Sampling in Test-Time Scaling》Y Wu, A Mirhoseini, T Tambe [Stanford University] (2025)
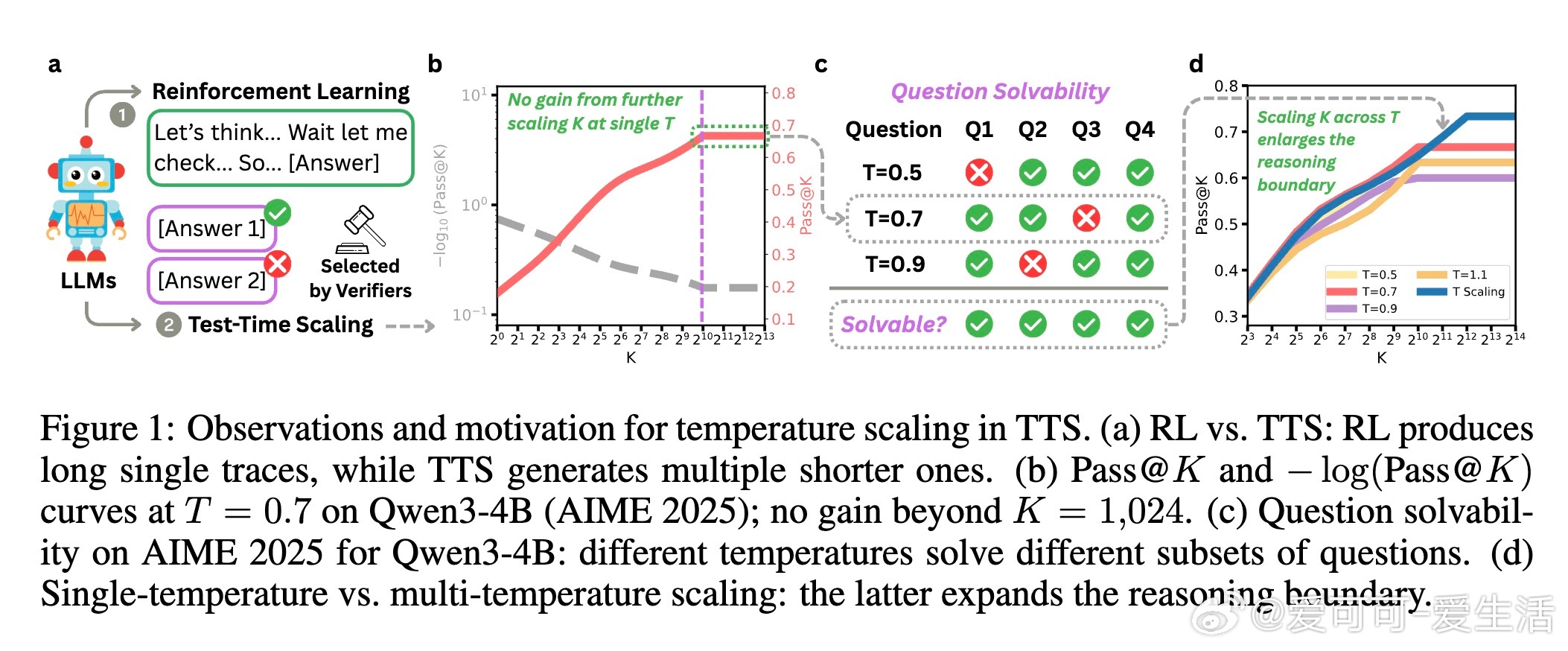
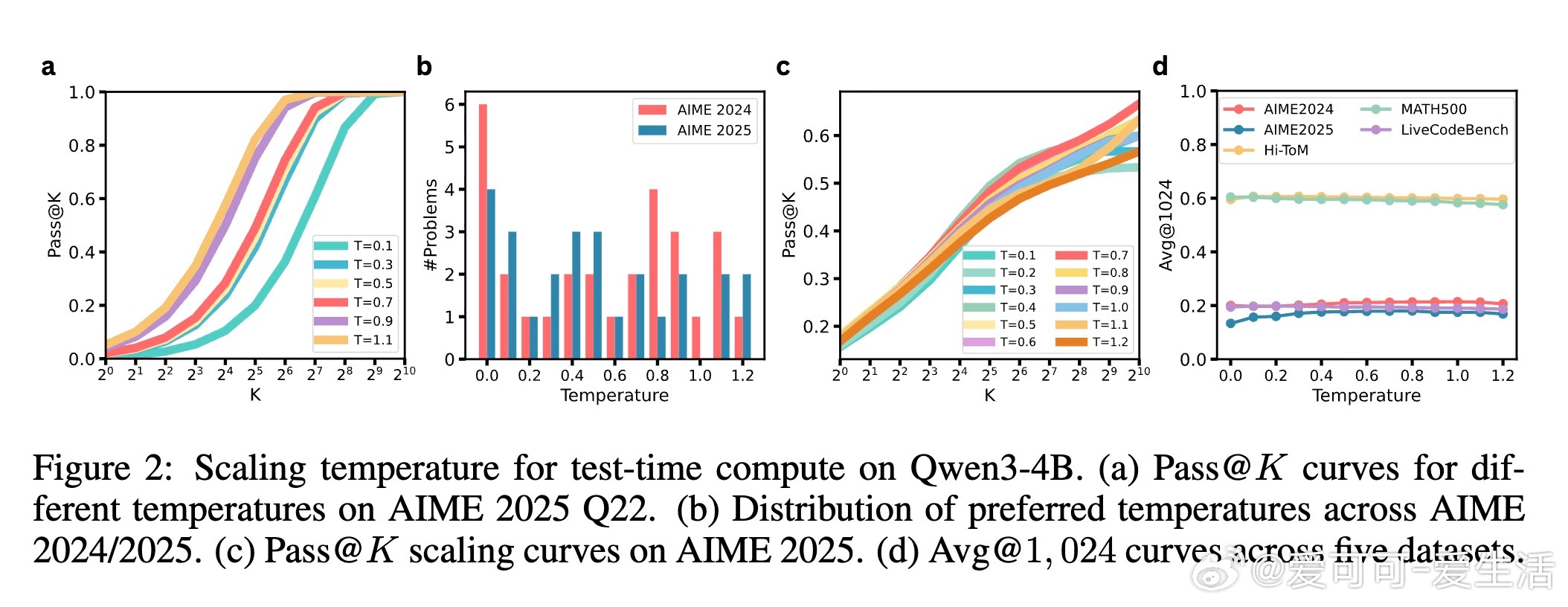
大语言模型(LLMs)推理能力提升,传统的测试时扩展(TTS)通过增加采样数量K来生成多条推理轨迹再择优,但当K极大时,性能饱和且仍有难题无法解决。本文发现:不同采样温度T能解答不同难题,单一温度限制了模型潜力。
🌟 核心创新:引入“温度维度”的扩展——多温度采样,将样本均分到多个温度,显著扩大模型推理边界。
【实验亮点】
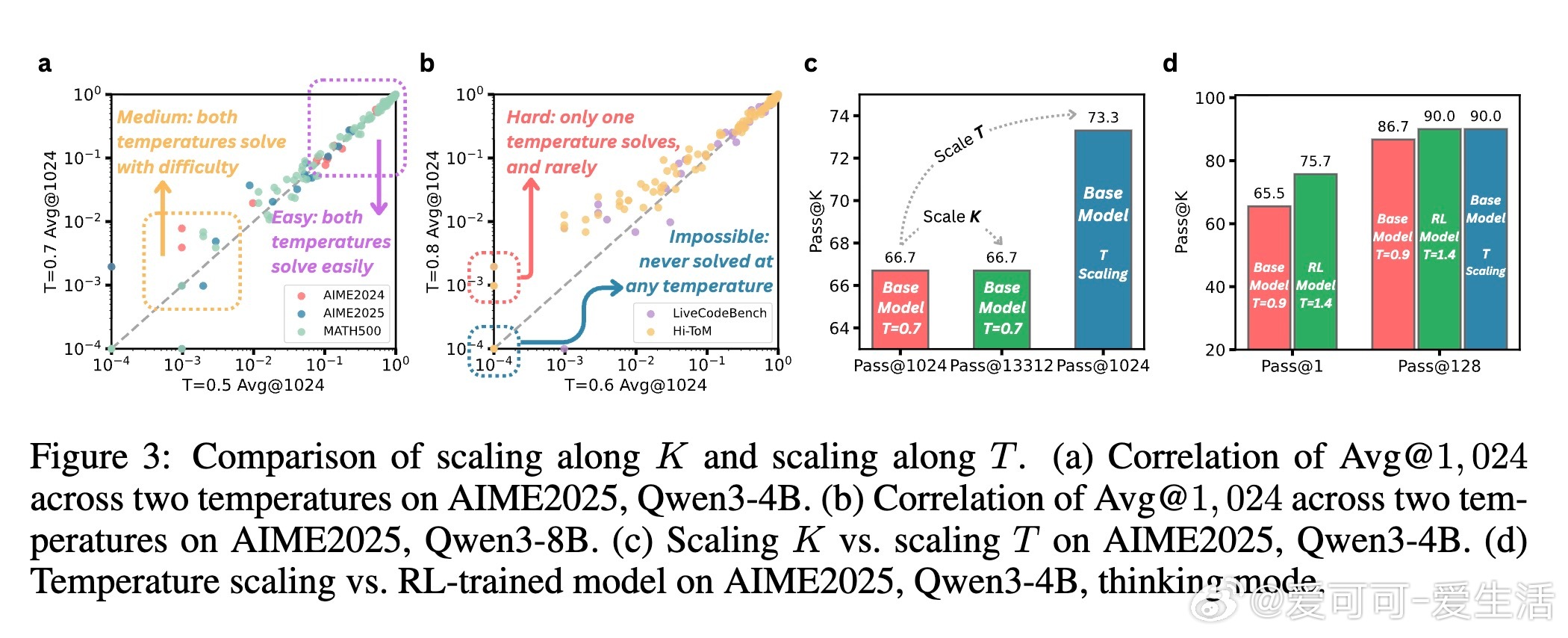
- 在Qwen3系列(0.6B~8B)和五大推理基准(AIME 2024/2025、MATH500、LiveCodeBench、Hi-ToM)上,多温度采样相比单温度TTS平均提升7.3个百分点。
- 多温度采样使无额外训练的基础模型表现可比强化学习(RL)训练模型,突破了推理性能瓶颈。
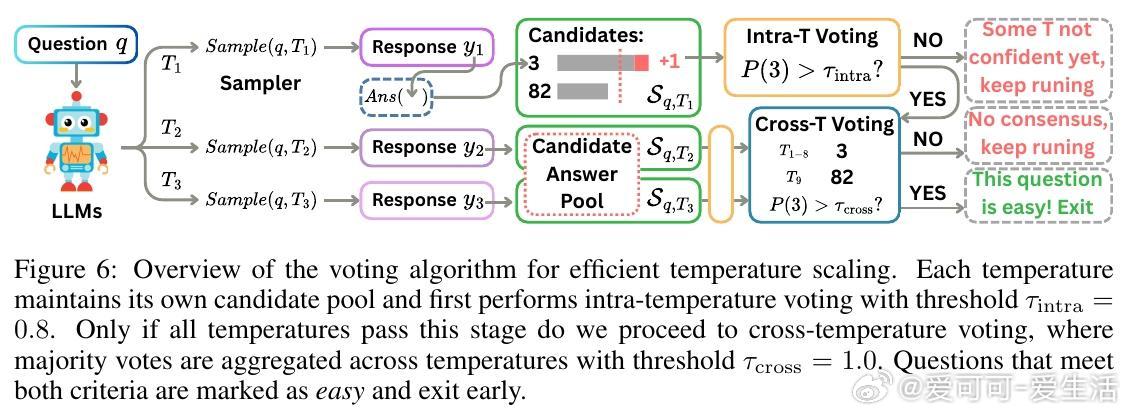
- 设计了多温度投票机制,实现对简单问题的早期退出,降低多温度带来的计算开销。
【深入分析】
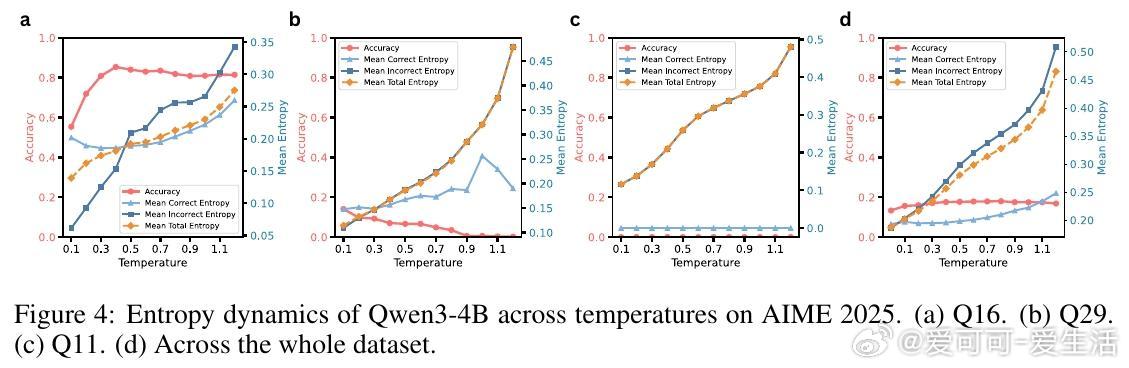
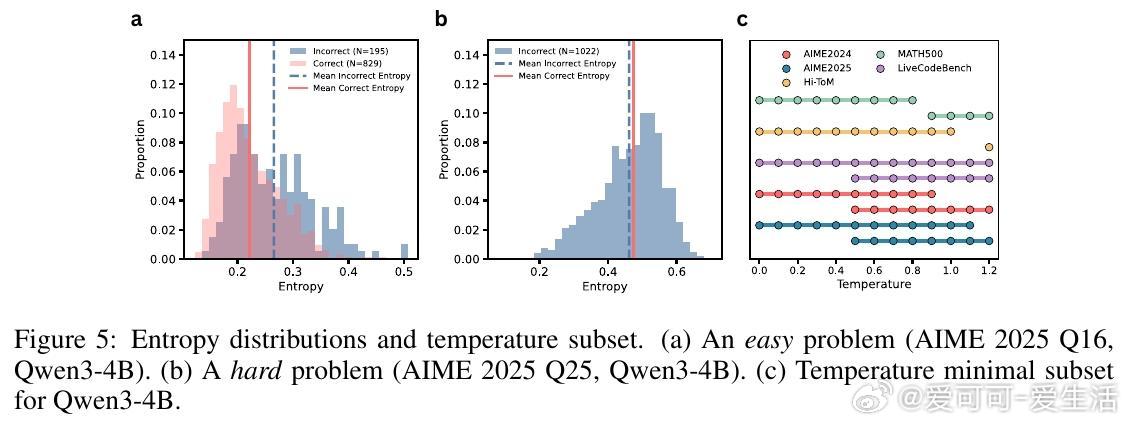
- 通过熵分析揭示,正确答案轨迹在不同温度下表现出不同的不确定度,难题往往只能在特定温度下被成功解决。
- 案例研究证明,某些数学问题仅在特定温度采样时模型能找到正确推理路径。
- 传统的单温度大样本采样(K扩展)存在性能天花板,而温度扩展提供了新的性能增长维度。
【实用意义】
- 温度采样为测试时推理性能扩展提供简单有效的新工具,无需额外训练成本。
- 多温度投票策略结合智能早退,兼顾性能与效率,适合实际部署。
- 研究提示未来探索单条生成中动态温度调整的潜力。
【总结】
本文系统证明了温度采样在测试时扩展中的关键作用,打破了仅靠提升采样数量的限制,开启了挖掘基础模型潜能的新路径。对提升LLM推理能力和部署效率具有重要启示。
🔗 论文链接:arxiv.org/abs/2510.02611
大语言模型 测试时扩展 温度采样 推理能力 人工智能 机器学习