[LG]《Less is More: Recursive Reasoning with Tiny Networks》A Jolicoeur-Martineau [Samsung SAIL Montreal] (2025)
🔍 研究背景:
大规模语言模型(LLMs)虽强大,但在难题如数独、迷宫和ARC-AGI等推理任务上仍表现有限,且依赖昂贵的链式思维(CoT)和测试时计算(TTC)。近期,Wang等人提出的层次推理模型(HRM)通过两个小型网络不同频率递归推理,显著提升了小样本学习表现,但结构复杂且依赖固定点理论,且参数量较大(27M)。
💡 核心贡献:
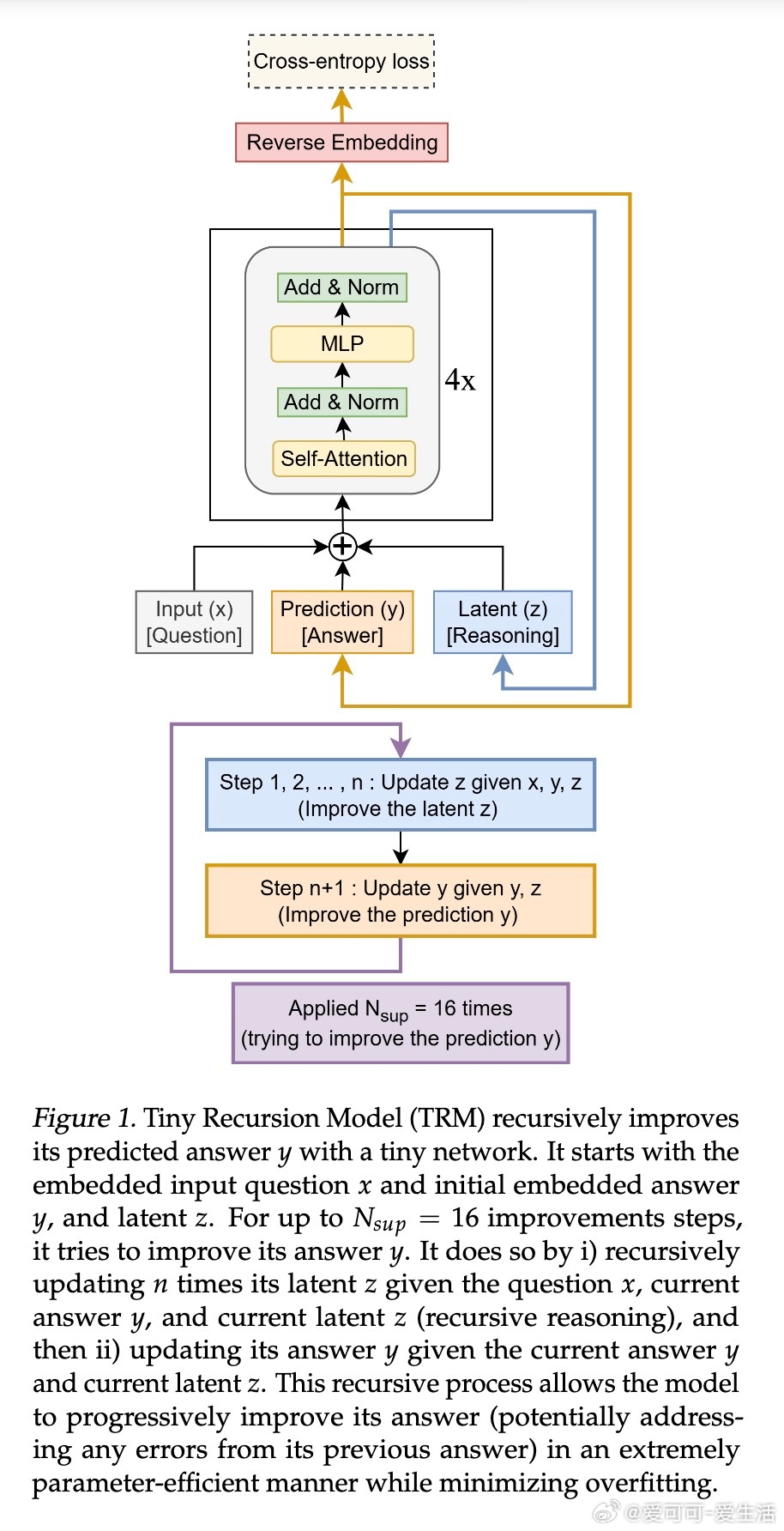
本文提出了更简洁有效的Tiny Recursive Model(TRM),仅用单一2层小型网络(7M参数)实现递归推理,跳过复杂的固定点假设和生物学解释,且训练时无需额外前向传播。TRM在ARC-AGI等任务上超越多数LLMs,且参数仅为它们的0.01%。
📈 关键创新点:
1. 简化递归流程:用单网络递归更新latent reasoning特征z和当前答案y,逐步优化答案,摒弃HRM中两个网络的分层递归。
2. 无固定点假设:取消HRM对固定点和一阶梯度近似的依赖,完整反向传播所有递归步骤,显著增强泛化能力。
3. 参数更少层数更少,更易泛化:2层网络优于4层,减少过拟合风险,参数量减半,模型更轻量。
4. 改进的自适应计算时间(ACT):仅学习停止概率,去除额外前向传播,提升训练效率。
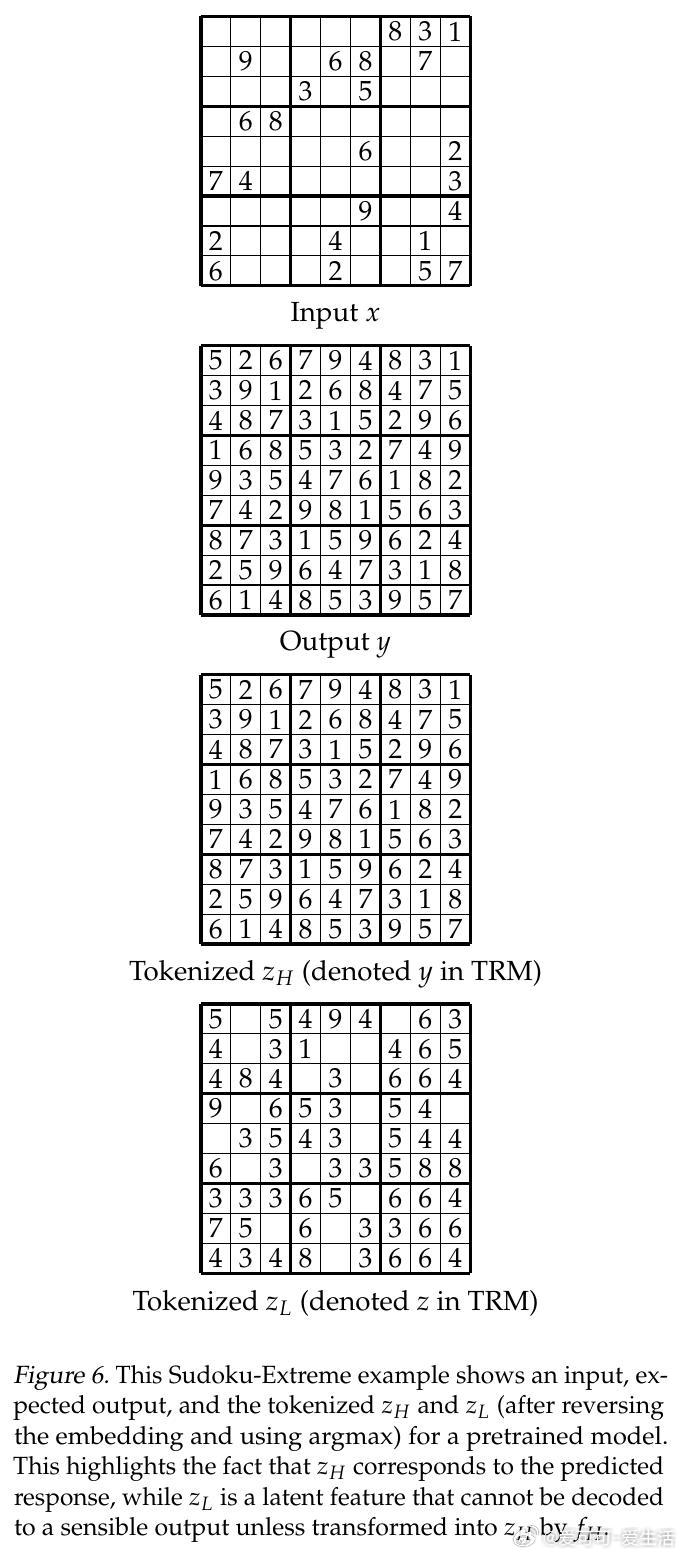
5. 去生物学复杂解释:重构latent特征意义,zH即当前答案嵌入,zL为辅助推理状态,解释更直观自然。
🎯 性能表现:
- Sudoku-Extreme(仅1K训练样本,423K测试):TRM准确率87.4%,显著超越HRM的55.0%和大型LLMs近乎0%。
- Maze-Hard:TRM 85.3%(self-attention版本),高于HRM 74.5%。
- ARC-AGI-1和ARC-AGI-2:TRM分别达44.6%和7.8%,超越HRM和多款LLMs。
📊 参数与资源:
TRM参数仅7M(Sudoku)至19M(Maze),训练耗时低,硬件需求较小(单卡40GB GPU数小时级训练)。
🔍 深度剖析:
- 递归次数与层数权衡,T=3, n=6为最佳选择,递归次数提升虽有潜力但受限内存。
- 取消多特征latent设计,双特征(y和z)最优。
- MLP替代自注意力在小上下文任务(数独)表现更佳。
📝 总结:
TRM展示“小网络+递归+深度监督”策略在复杂推理任务上的巨大潜力。其简洁高效的设计理念,为未来小样本、低资源环境下的智能推理提供了新路径。
阅读全文:
机器学习 深度学习 递归推理 小样本学习 AI推理 神经网络 ARC_AGI Sudoku Maze TinyRecursiveModel