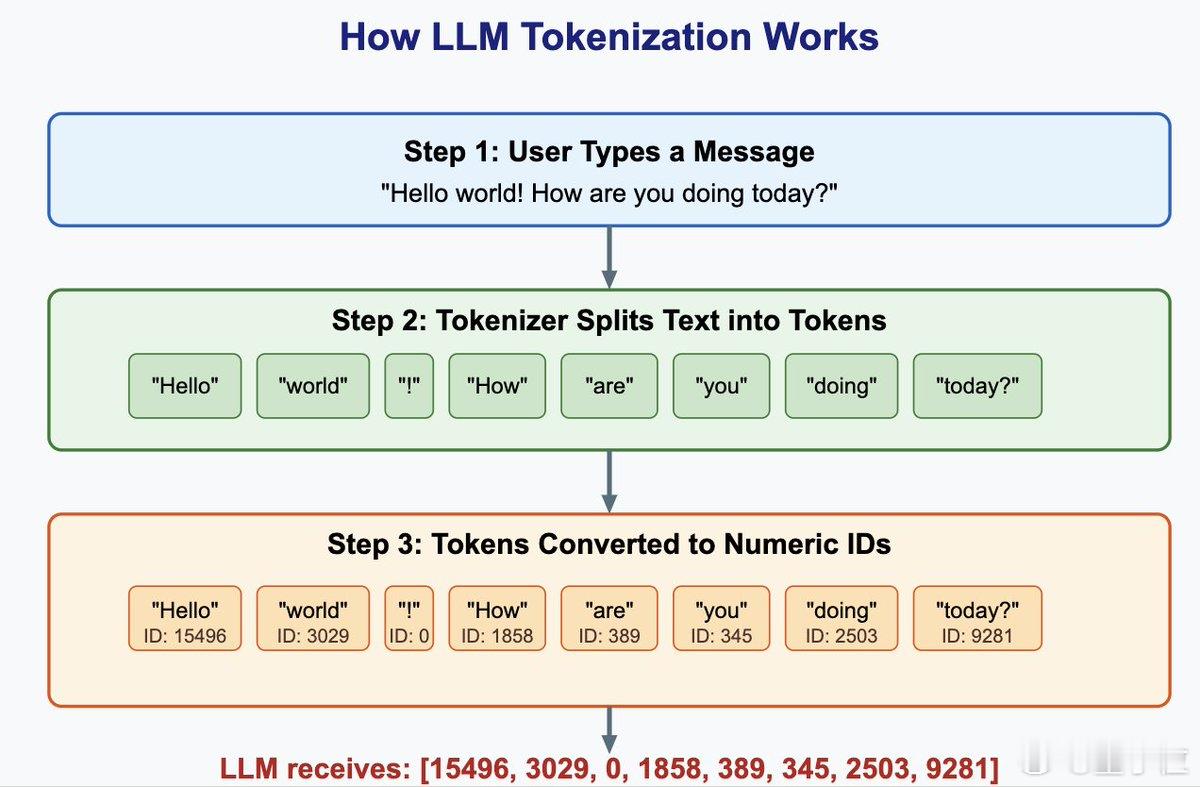
详解LLM分词策略什么是大模型分词
一篇内容帮你弄懂:什么是LLM分词(Tokenization)?
大语言模型(LLM)第一步便是从分词开始。这个环节负责把自然语言切分成模型能理解的最小单位“Token”,是LLM完成理解、计算和生成的前提。
分词绝非小事,不同的分词策略会直接影响模型的性能、泛化能力、推理速度。以下是几种主流分词策略的拆解、背后逻辑,以及它们各自适用的场景:
1.字符级分词(Character-level):
切法:每个字母、汉字或符号都视为一个Token
优点:语言通用性强,不存在未登录词(OOV)问题
缺点:序列过长,计算效率低,上下文建模难度大
适用场景:数据量小或输入内容极其多样(如包含大量符号、拼写错误)
2.单词级分词(Word-level):
切法:以空格或标点为界切分成完整单词
优点:直观、符合人类语言习惯
缺点:词表庞大,新词或造词无法处理
适用场景:语言结构清晰、任务简单(如今已基本被淘汰)
3.子词级分词(Subword-level):当前主流选择
核心思路是将词语拆分为介于字符和单词之间的“子词”,通过组合子词实现对新词的泛化能力与计算效率的平衡。主要算法包括:
- BPE(Byte Pair Encoding):从字符对开始,迭代合并频率最高的字符对,是GPT系列所采用的方式 优点:词表较小,能处理新词,算法简单 缺点:合并逻辑仅基于频率,不考虑语言结构或语义
- WordPiece(用于BERT):通过条件概率判断子词是否合并,强调语义合理性 优点:较BPE稳定,生成子词更贴近语言规律
- Unigram(SentencePiece使用):从大词表出发,训练出概率最优的子词集合 优点:支持多种分词方案并行评估,灵活性更高 适用场景:跨语言、多领域任务(如T5、ALBERT使用该策略)
4.字节级分词(Byte-level):
切法:先将文本转换为字节(0~255),再执行子词级处理,GPT-2即采用“字节级BPE”
优点:语言中立,支持emoji、代码等非语言符号
缺点:初始Token不具可读性,词表构造复杂
适用场景:支持多语言和符号输入的通用大模型
5.混合策略(Hybrid Approaches):
许多现代大模型结合多种分词方案,以兼顾泛化能力与语言表达精度:
- GPT系列:采用字节级BPE,兼容多语言、符号,处理能力强
- Google系模型(如BERT、T5):使用WordPiece或Unigram,更注重语言建模能力
- 多语种模型:采用语言标记、多语言词表、形态学感知(如MorphBPE)提升跨语言表达
为什么分词策略如此关键?因为它影响着LLM这些方面——
1.效率:切得越细,序列越长,计算越慢
2.理解力:切词太碎会导致语义割裂,太整又难处理新词
3.泛化能力:子词分词支持新词构造,提升模型对陌生输入的应对能力
4.公平性与语言覆盖:研究发现,分词策略不当可能让小语种或中性表达在训练中受限
5.训练与推理成本:词表规模影响参数量,Token数影响训练和推理开销
下面说些值得关注的分词趋势:
- 新算法如MorphBPE、LBPE正尝试将形态学与语义信息融合,提升切词质量
- 越来越多研究指出,分词策略不仅决定训练效率,甚至影响最终模型的表现和所需资源
- 有团队探索“无分词”方法,如纯字符输入或端到端建模,但目前仍受限于序列长度问题
总而言之,分词不是简单的“拆字”操作,而是LLM认知世界的第一步。分词策略决定了模型看世界的“颗粒度”,进而影响它能理解什么、学到什么。
想判断一个模型“聪不聪明”?先看看它是怎么分词的。