如何训练大语言模型omkaark.com/posts/llm-1b-1.html这篇博文记录了作者构建一个领域特定模型的过程,重点是设置基础的预训练基础设施并训练一个类似Llama 3风格的1B模型。训练用的8×H100的GPU。作者计划逐步改进训练基础设施,包括培养自己的token集合,并进行架构优化以支持推理能力。
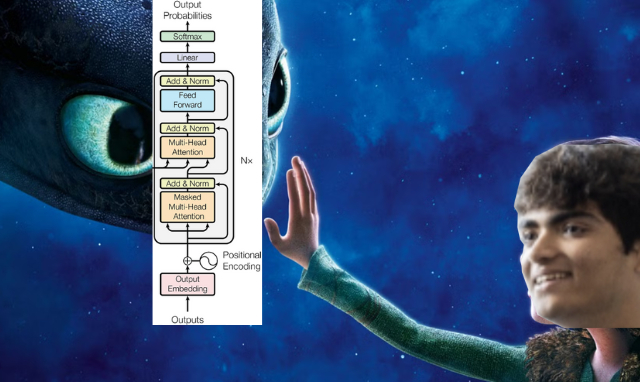
如何训练大语言模型omkaark.com/posts/llm-1b-1.html这篇博文记录了作者构建一个领域特定模型的过程,重点是设置基础的预训练基础设施并训练一个类似Llama 3风格的1B模型。训练用的8×H100的GPU。作者计划逐步改进训练基础设施,包括培养自己的token集合,并进行架构优化以支持推理能力。
猜你喜欢

【1评论】【1点赞】

【28评论】【12点赞】


【26评论】【18点赞】

【40评论】【17点赞】

【6评论】【3点赞】

【2评论】【2点赞】

作者最新文章
热门分类
科技TOP
科技最新文章