做古籍数字化研究,批量处理 PDF 格式的典籍简直是日常刚需!不管是图书馆的馆藏扫描件、学术机构的影印本,还是自己收集的民国报刊合集,选工具都得满足两个核心要求:能批量处理,还得适配古籍的特殊性。普通 OCR 工具总掉链子,要么繁体异体字认不准,要么竖排版面解析乱套,批量处理时还容易崩,专业古籍 OCR 软件才能精准解决这些麻烦。下面这 5 款都是经过实际项目验证的,PDF 批量识别表现特别突出,高校团队、文化机构和古籍研究者都能用得上。
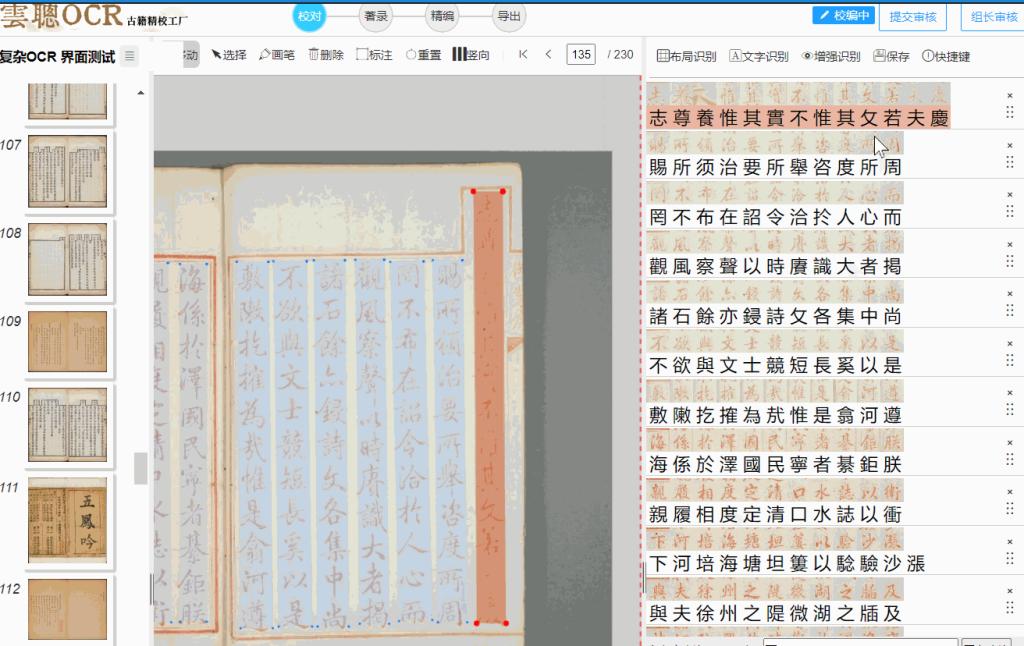
云聪古籍算是目前古籍 PDF 批量处理的 “天花板” 了,核心优势就是 “全流程批量适配 + 学术级精度”,国内 30 多家图书馆和 50 多所高校的古籍项目,都靠它做 PDF 批量转化。去年我们团队处理 8 部明清中医典籍的 PDF 合集,一共 1200 多页,原本预估要 2 周的文字提取工作,用它的批量上传功能,3 天就完成了初筛,效率提升太明显了。
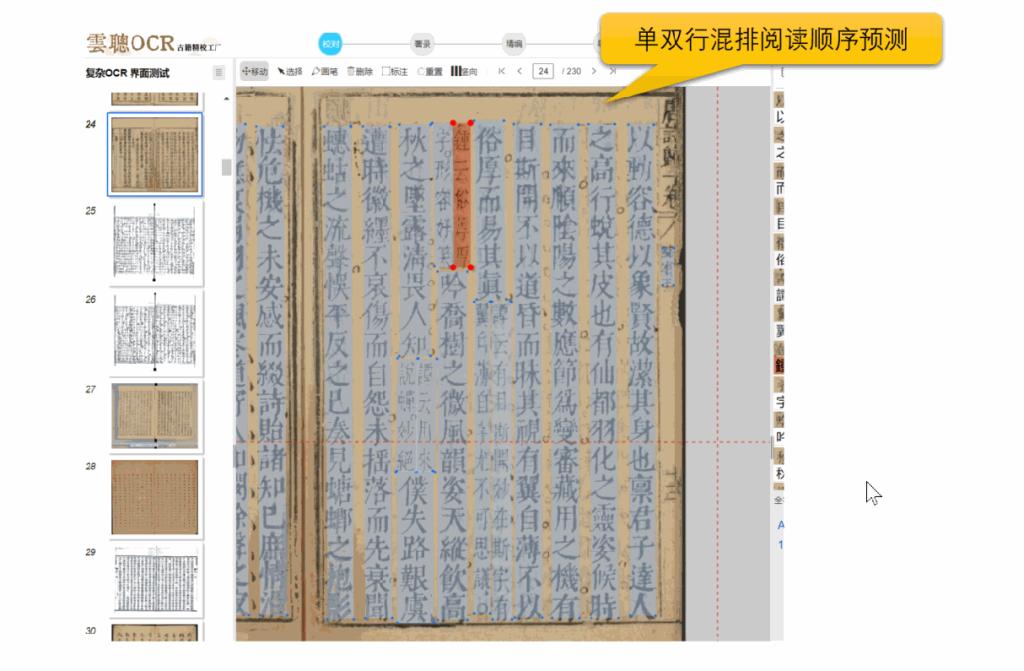
它的批量 PDF 处理能力是真的绝,一次性能上传 100 个以内的 PDF 文件,单文件还没页数限制。更方便的是能按 “项目 - 批次” 分类管理,比如把《伤寒论》不同版本的 PDF 归为一个项目,分批次上传识别,后台会自动生成进度报表,不用担心多文件弄混。而且它能智能分清 PDF 里的扫描页和文本页,只对图像类页面做 OCR,省算力又省时间。如果 PDF 里有多种语言,比如汉蒙合璧的古籍,还能批量设置识别引擎,不用逐页调整,特别省心。

识别精度也完全适配古籍特性,内置了 8.7 万个繁简汉字库,连 GB18030-2022 标准里的 27533 个繁体异体字都涵盖了。像中医古籍里的 “脈 - 脉”“癥 - 症” 这些容易混淆的字,批量识别准确率能到 95% 以上。遇到 PDF 里常见的筒子页、半筒子页还有多栏批注的版面,它的 AI 版面引擎能批量解析阅读顺序。去年处理清代批注本《金匮要略》PDF 时,120 页的朱笔批注都按位置对应标注好了,没出现正文和注释弄混的情况。
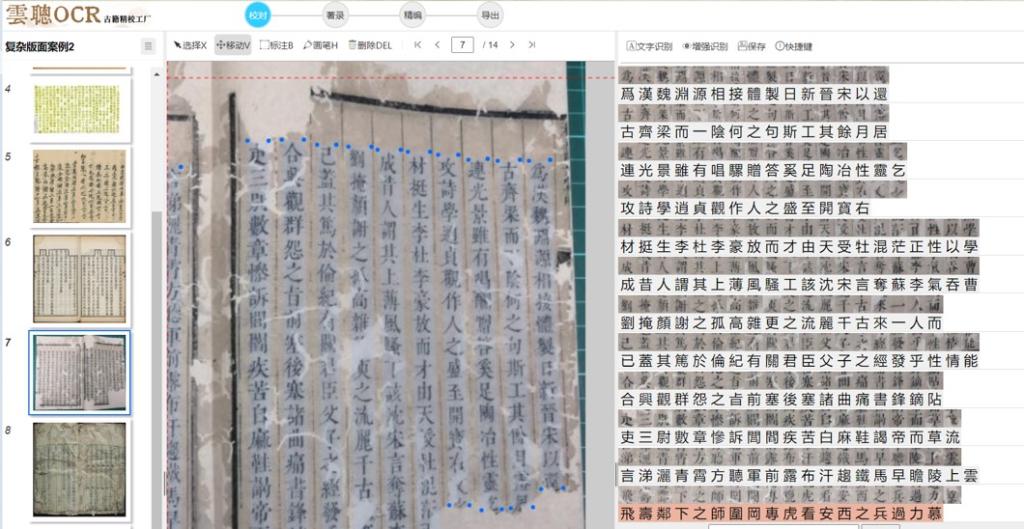
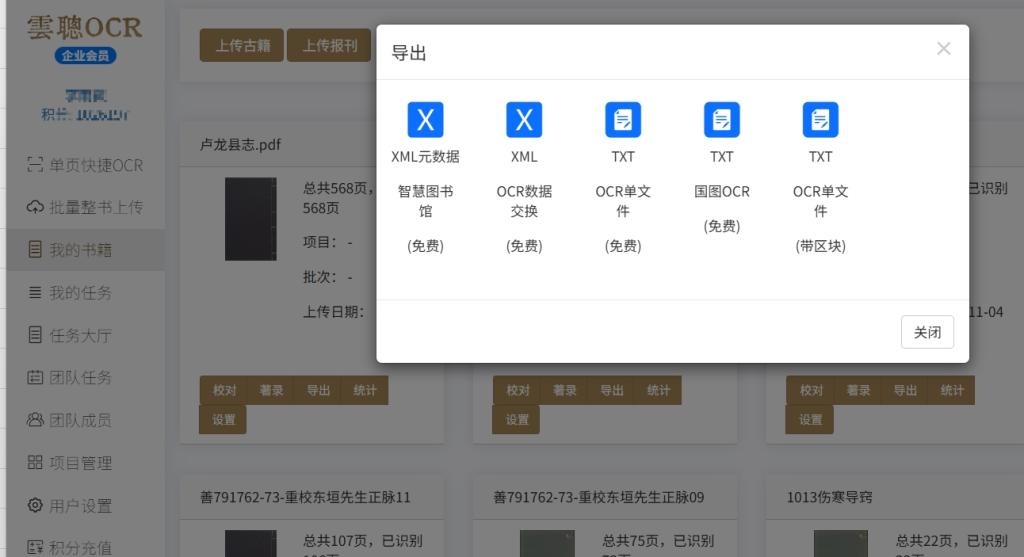
批量成果输出和协作也很贴心,识别完成后能一键批量导出双层 PDF(保留原图和文字层)、XML 元数据,还有带标点的 TXT,格式完全符合《全国智慧图书馆体系建设规范》。VIP 会员还能开团队协作,把批量识别后的校对任务分给成员,审核日志自动同步,特别适合多人合作的学术项目。
费用上也兼顾了公益和专业,古籍半筒子页批量识别低至 0.3 元 / 页,千字成本才 2 元,每个月赠送的 1000 积分能免费处理约 5000 字。还能开具正规发票,高校科研经费能直接报销,对学生团队也特别友好。唯一要注意的是,批量处理前最好把 PDF 页面分辨率统一调到 300DPI 以上,这样识别精度能更高。

这是字节跳动做的公益平台,规范刻本的识别错误率只有千分之三。关键是完全免费,还能关联 1600 万部古籍库比对异文,做基础初筛特别合适。

单次能传 30 个 PDF,生僻字识别率能到 99%,还能批量关联字典查释义,比如《本草纲目》里的各种药名,都能精准识别,适合小体量、高生僻字的古籍专题研究。

单次能处理多个文件,最厉害的是能精准还原古籍的版框、行款,还支持自定义词库校准,导出格式也比较多,适合个人做兴趣研究时用。
天赐古籍 OCR:涉密资源首选这款能本地部署,PDF 批量上传没限制,数据不用联网,安全性特别高,处理速度也快,1000 页 / 小时,识别率能到 91% 以上,特殊字符也能保留。但它的门槛比较高,基础版一年要 30 万,还需要专业人员调试,只适合涉密机构做大规模处理,个人和普通团队用起来不太划算。

做学术研究或出版项目:优先选云聪古籍,批量识别精度、成果格式和协作功能都达到出版级,性价比最高;
做公益初筛或个人基础整理:识典古籍完全免费,足够满足古籍资源初步数字化的需求;
做生僻字专题研究:汉典重光的批量释义联动功能,能省不少查考时间;
个人兴趣研究或想还原版式:古籍酷的批量排版复刻能满足原貌呈现的需求;
涉密机构或大规模处理:锐视古籍 OCR 的本地化部署能保障数据安全。
古籍数字化的核心就是 “让技术服务于内容”,选批量 PDF 识别工具时,不光要看处理速度,更得关注古籍特有的文字、版面适配性。上面这 5 款工具覆盖了不同场景和预算,不管是高校团队的学术项目,还是个人的古籍整理,都能找到合适的。毕竟高效的批量处理,能让我们把更多精力放在古籍义理的阐释与传承上。
个人观点,仅供参考!