[CL]《Artificial Hippocampus Networks for Efficient Long-Context Modeling》Y Fang, W Yu, S Zhong, Q Ye... [ByteDance Seed] (2025)
人工海马网络(AHNs):高效处理超长上下文的新范式
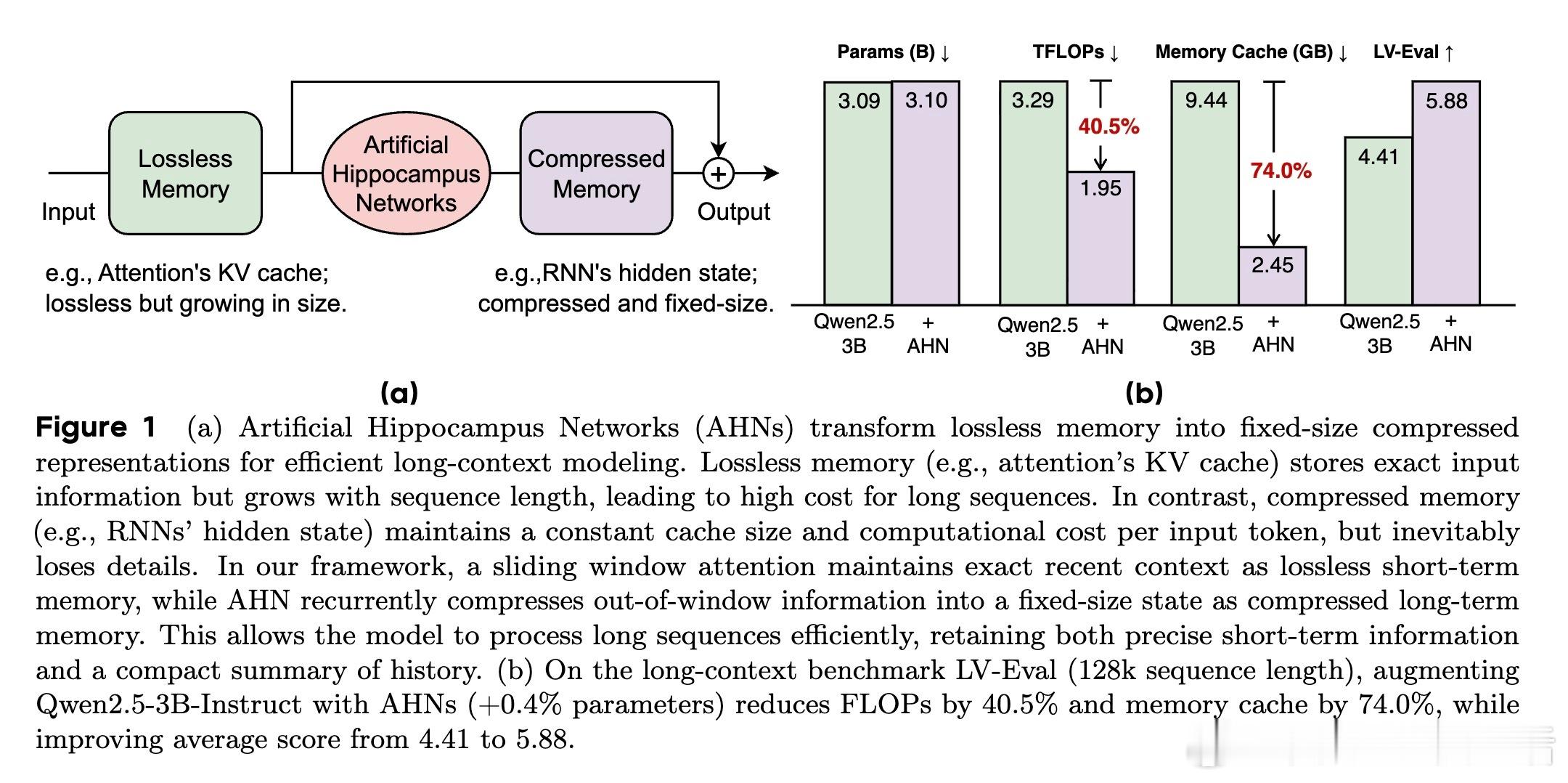
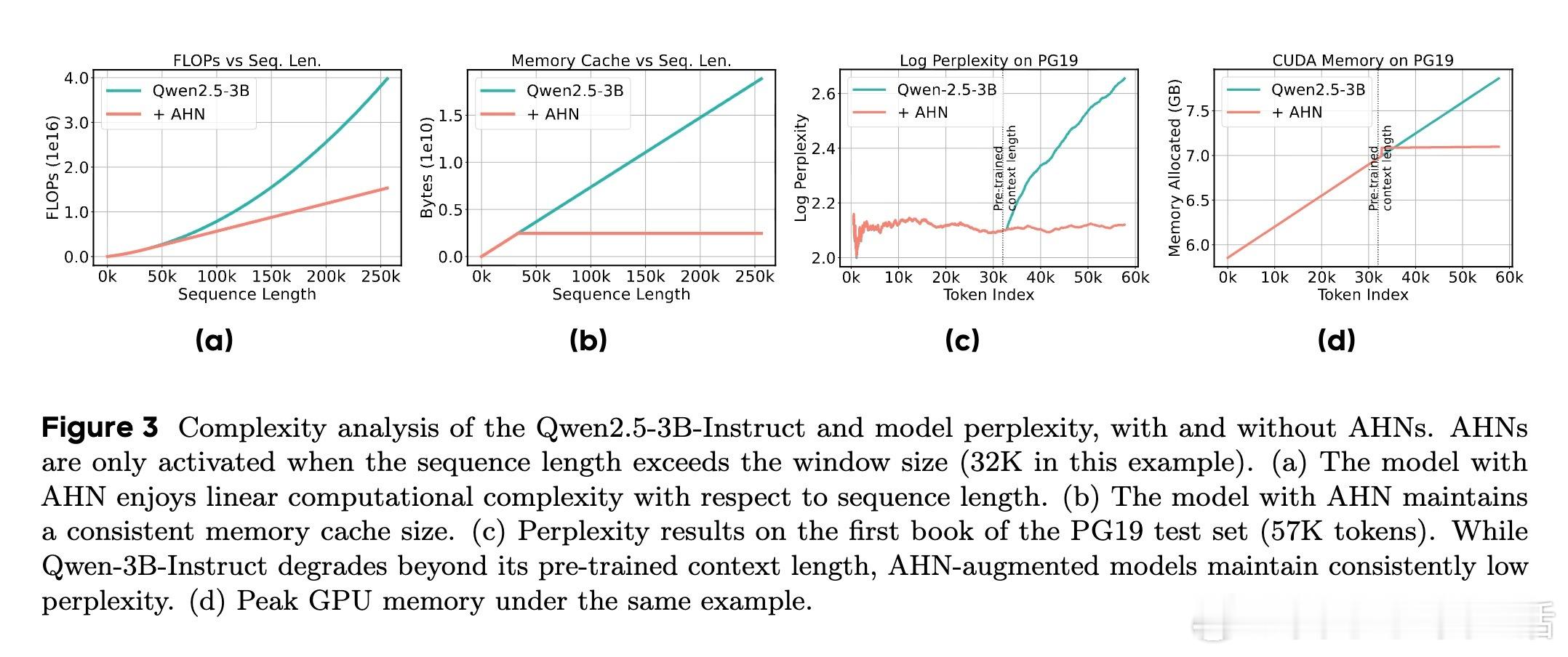
⚡ 长序列建模中,Transformer的KV缓存虽保留细节完好,却随序列增长而线性膨胀,计算量爆炸;而RNN类模型则用固定大小的压缩记忆,效率高但信息丢失严重。
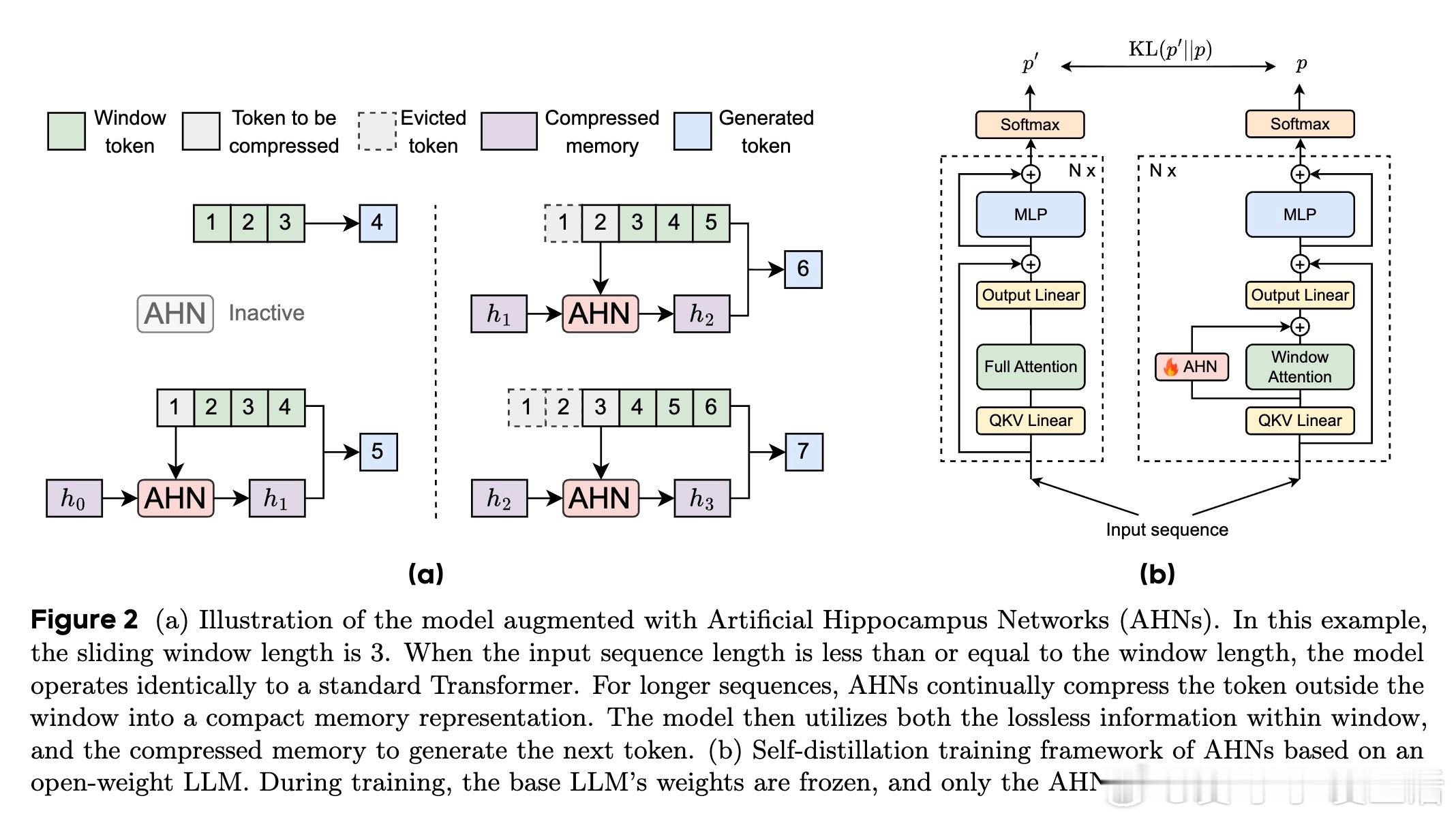
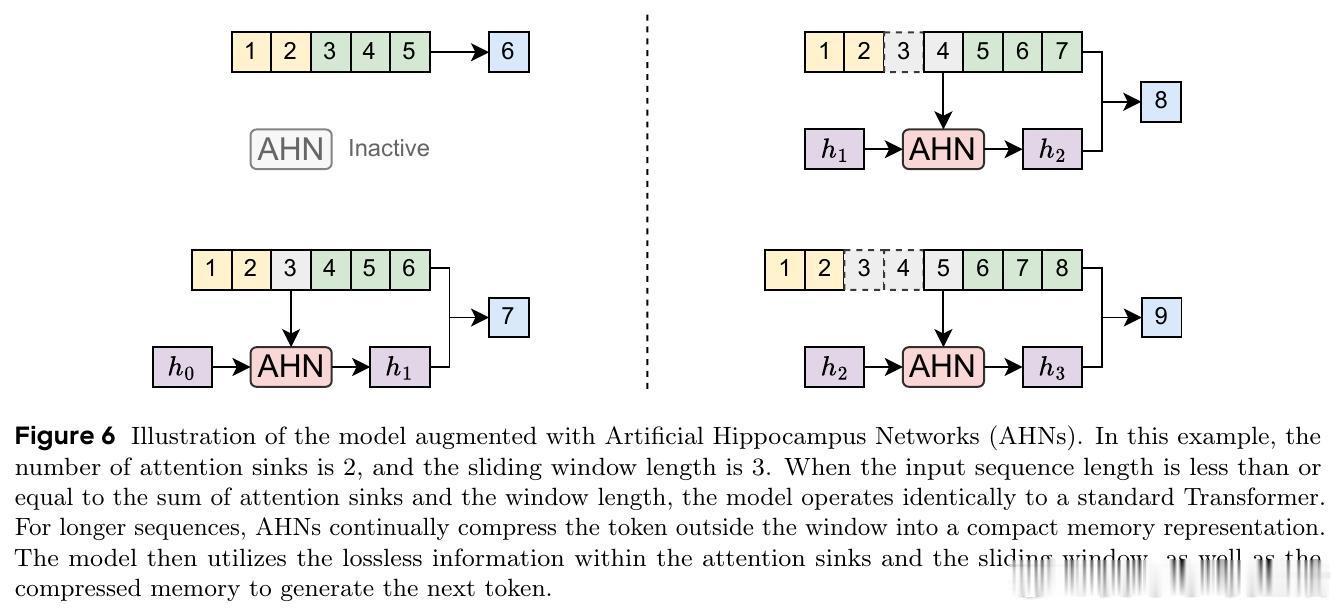
🧠 受认知科学多存储模型启发,AHNs框架巧妙结合两者优点:保持Transformer滑动窗口内的无损短期记忆,同时用人工海马网络(RNN变体)递归压缩窗口外信息,形成固定尺寸的长期压缩记忆。
✨ 实验亮点:
- 在128k长度的LV-Eval基准上,Qwen2.5-3B模型加入AHN后,仅增加0.4%参数,FLOPs降低40.5%,内存缓存缩减74%,综合表现从4.41提升至5.88。
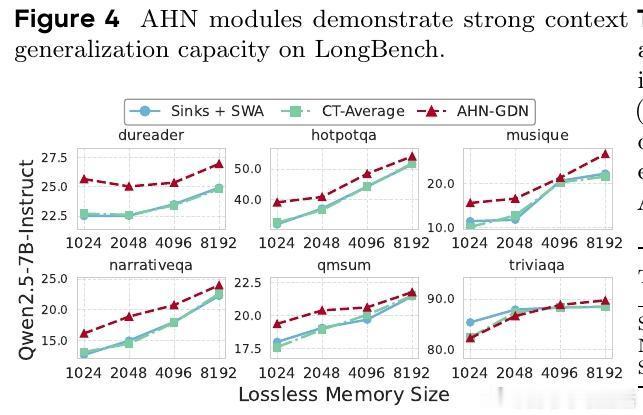
- AHN实例涵盖Mamba2、DeltaNet、GatedDeltaNet,均显著超越滑动窗口基线,性能媲美甚至超越全注意力模型。
- 训练采用自我蒸馏,冻结基础模型,仅训练AHN模块,提升训练效率与泛化能力。
- AHN在数学符号等关键内容上保留信息,优先压缩无关词汇,体现精准信息筛选。
🔍 该方法为大模型长上下文处理提供了兼顾效率与性能的优雅解决方案,适合资源受限场景及超长文本理解。
🚀 代码与模型开源:github.com/ByteDance-Seed/AHN 及 huggingface.co/ByteDance-Seed
---
全文阅读👉 arxiv.org/abs/2510.07318
自然语言处理 长文本理解 深度学习 Transformer 神经网络 认知科学 AI技术