英伟达GTC关于自动驾驶部分,老黄惜字如金,我估计跟时长相关,所以英伟达的Alpamayo-R1模型简单一笔带过。官网有这个模型的详细介绍,这也是吴新宙加盟英伟达之后,团队的重要成果之一。
Alpamayo-R1 (AR1) 的核心目标:解决长尾场景的推理难题
传统的端到端 (E2E) 自动驾驶模型虽然在不断发展,但在安全关键的长尾场景中表现依然脆弱。这主要是因为在这些场景中,监督数据稀疏,且模型缺乏对因果关系的深刻理解。
Alpamayo-R1 作为一个VLA模型被提出,其核心论点是,有效的自动驾驶推理必须是“有因果基础且在结构上与驾驶任务保持一致的” (causally grounded and structurally aligned),而不是生成冗长、非结构化的自由文本。
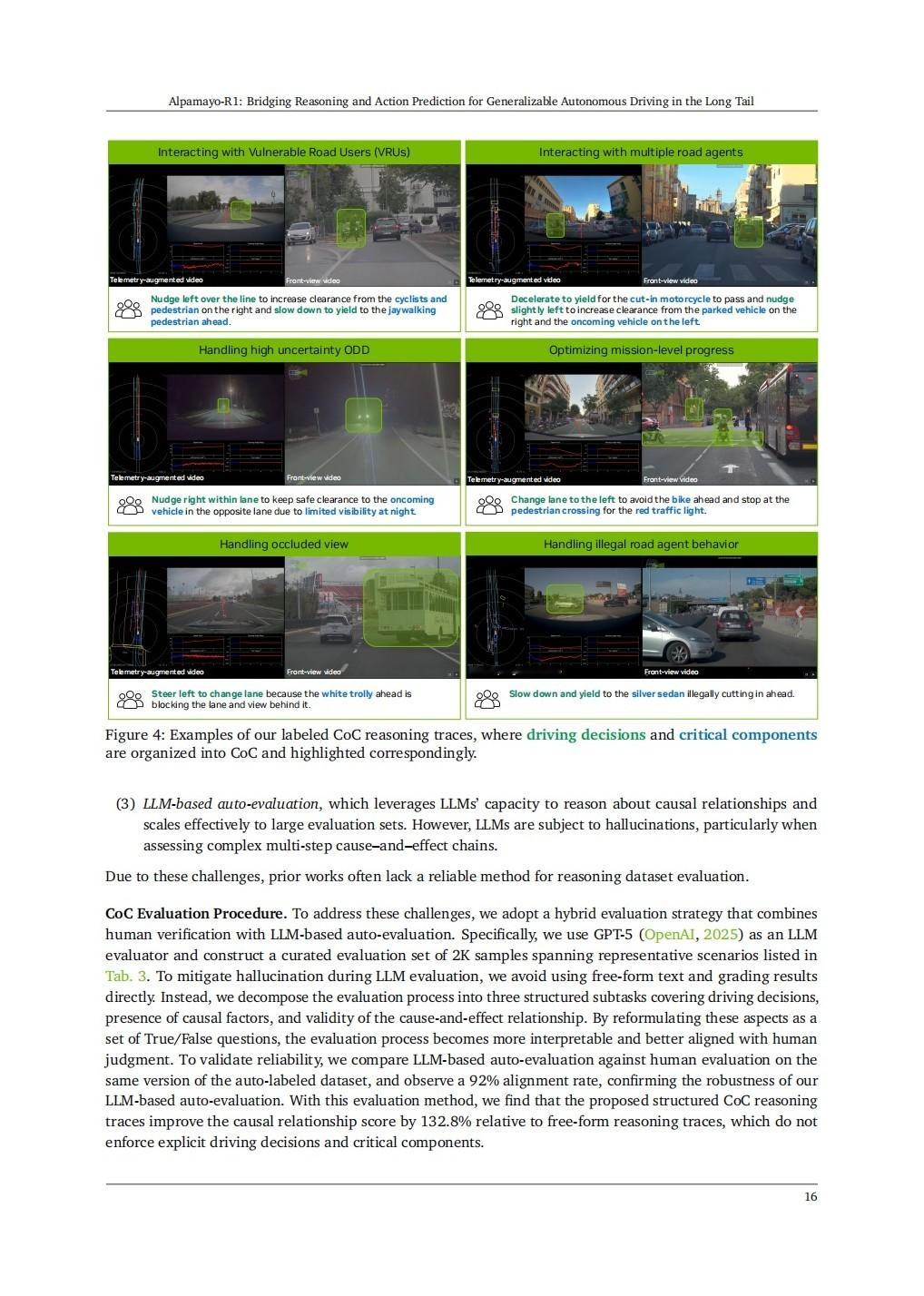
1. 因果链 (CoC) 数据集 (Chain of Causation (CoC) dataset)
为了训练模型进行有意义的推理,NVIDIA 构建了一个新的数据集。
目标是改进现有的推理数据集存在严重缺陷,例如:
* 模糊的行为描述: 标注文本(如“请小心”)与车辆轨迹的相关性很弱。
* 表面的推理: 包含许多与驾驶决策无直接因果关系的上下文信息(如“天气晴朗”、“道路宽阔”)。
* 因果混淆: 推理中引用了在决策时刻之后才发生的未来事件,这是因为标注者通常能看到完整的视频片段。
为了解决这些问题,CoC 数据集采用了一种结构化的标注框架:
* 驾驶决策 (Driving Decision): 标注员必须从一个“封闭集合”中选择一个明确的驾驶意图(例如“保持车道并居中”、“为行人让行”、“停止以遵守静态约束”)。
* 关键组件 (Critical Components): 标注员从一个“开放集合”中识别出直接导致该决策的因果因素(例如“关键物体”、“交通信号灯状态”、“车道线类型”)。
* 组合的 CoC 追踪 (Composed CoC Traces): 最后,将决策和原因组合成一个简洁、有因果逻辑的自然语言推理轨迹。
* 标注流程: 数据集通过“自动标注”和“人机回圈” (human-in-the-loop) 的混合流程构建。该流程一个关键步骤是“关键帧标注” (Keyframe Labeling),即精确定位驾驶决策发生的瞬间(例如,在自我车辆开始减速前 0.5 秒),确保所有因果因素都源自可观察到的历史窗口,从而防止因果混淆。
2. 模块化的 VLA 架构
AR1 采用了一个模块化的架构,扩展自 Alpamayo-VA 。
* VLM 主干 (VLM Backbone): 采用 Cosmos-Reason (NVIDIA et al., 2025) 作为 VLM 主干。这是一个专门为物理 AI 应用(包括自动驾驶、机器人等)预训练的 VLM,使其具备物理常识和具身推理能力。
* 视觉编码 (Vision Encoding): 为了处理自动驾驶所需的多摄像头、多时间步输入,AR1 支持高效的视觉编码器。这包括使用基于三平面 (triplanes) 的多摄像头标记器,它可以将标记数量减少 3.9 倍,以及支持像 Flex (Yang et al., 2025) 这样的多摄像头视频标记器,最高可实现 20 倍的标记压缩率。
* 轨迹解码 (Trajectory Decoding): AR1 不直接预测轨迹的 (x, y) 坐标点,而是采用基于 单车动力学 (unicycle dynamics) 的控制表示,即预测未来的加速度 (a^i) 和曲率 (\kappa^i)。它使用一个基于 流匹配 (flow matching) 的“行动专家” (action-expert) 解码器,以实时生成平滑且运动学上可行的轨迹。
3. 多阶段训练策略
AR1 的训练分为三个阶段,逐步增强模型能力:
* 阶段 1:行动模态注入 (Action Modality Injection): 首先,通过模仿学习(预训练)将行动能力(预测轨迹)注入到 VLM 中。
* 阶段 2:引发推理 (Eliciting Reasoning): 接着,使用新构建的 CoC 数据集 对模型进行监督微调 (SFT)。这一阶段教会模型生成与驾驶决策相符的、有因果基础的解释。
* 阶段 3:基于 RL 的后期训练 (RL-based Post-Training): SFT 本身并不完美,模型可能学会数据偏差、产生幻觉,或出现“推理-行动不一致”(即说的和做的不一样)。
* 算法: 为解决此问题,AR1 采用基于强化学习 (RL) 的后期训练,具体使用的是 GRPO 算法 (Shao et al., 2024)。
* 复合奖励: RL 阶段优化一个复合奖励函数,该函数包含三个互补的信号:
* 推理质量奖励 (r_{reason}): 使用一个大型推理模型 (LRM) 作为“批判者” (critic),根据结构化标准(行为一致性、因果推理质量)对 AR1 生成的推理进行评分 (0-5 分)。
* CoC-行动一致性奖励 (r_{consistency}): 检查模型生成的“推理文本”中隐含的意图是否与其预测的“轨迹”所对应的元动作(如加速、左转)相匹配。
* 轨迹质量奖励 (r_{traj}): 确保轨迹的物理可行性、安全性和舒适性,包含 L2 模仿损失(接近专家轨迹)、碰撞惩罚和加加速度 (jerk) 惩罚(避免突兀运动)。
关键实验结果
AR1 在开环测试(预测准确性)、闭环仿真(AlpaSim 模拟器)和真实车载测试中均表现出色。
* 性能提升:
* 开环: 在具有挑战性的场景中,AR1 (使用 CoC 推理) 的轨迹规划准确性 (minADE6) 比仅预测轨迹的基线模型提升了高达 12%。
* 闭环: 在 AlpaSim 仿真中,AR1 使偏离道路率降低了 35%,近距离接触率降低了 25%。
* RL 效果显著:
* RL 后期训练使模型的推理质量得分提高了 45%(从 3.1 提高到 4.5)。
* 同时,推理-行动一致性提高了 37%(从 0.62 提高到 0.85)。
* 模型扩展性:
* 模型规模的扩大带来了持续的性能提升。7B 参数的模型比 0.5B 模型的轨迹准确性高出 11%。
* AR1 选用的 Cosmos-Reason (7B) 主干在 LingoQA 驾驶场景理解基准测试中,性能(66.2%)优于 GPT-4V (59.6%) 和 Qwen2.5-VL-7B (62.2%) 等通用 VLM。
* 真实世界部署:
* AR1 成功部署到了测试车辆上,并在城市驾驶环境中进行了道路测试。
* 在 NVIDIA RTX 6000 Pro Blackwell 平台上,AR1 实现了 99ms 的端到端推理延迟,满足了自动驾驶的实时性要求(通常为 100ms)。
Alpamayo-R1 是英伟达通过整合结构化推理与精确控制,来实现更安全、更可解释的 L4 级别自动驾驶的实用路径。
NVIDIA 计划在未来发布 AR1 模型以及 CoC 数据集的一个子集,以推动该领域的研究。