[CL]《Shoot First, Ask Questions Later? Building Rational Agents that Explore and Act Like People》G Grand, V Pepe, J Andreas, J B. Tenenbaum [MIT CSAIL & Harvard SEAS] (2025)
打造理性探索智能体:从人类行为中学习提问与行动策略
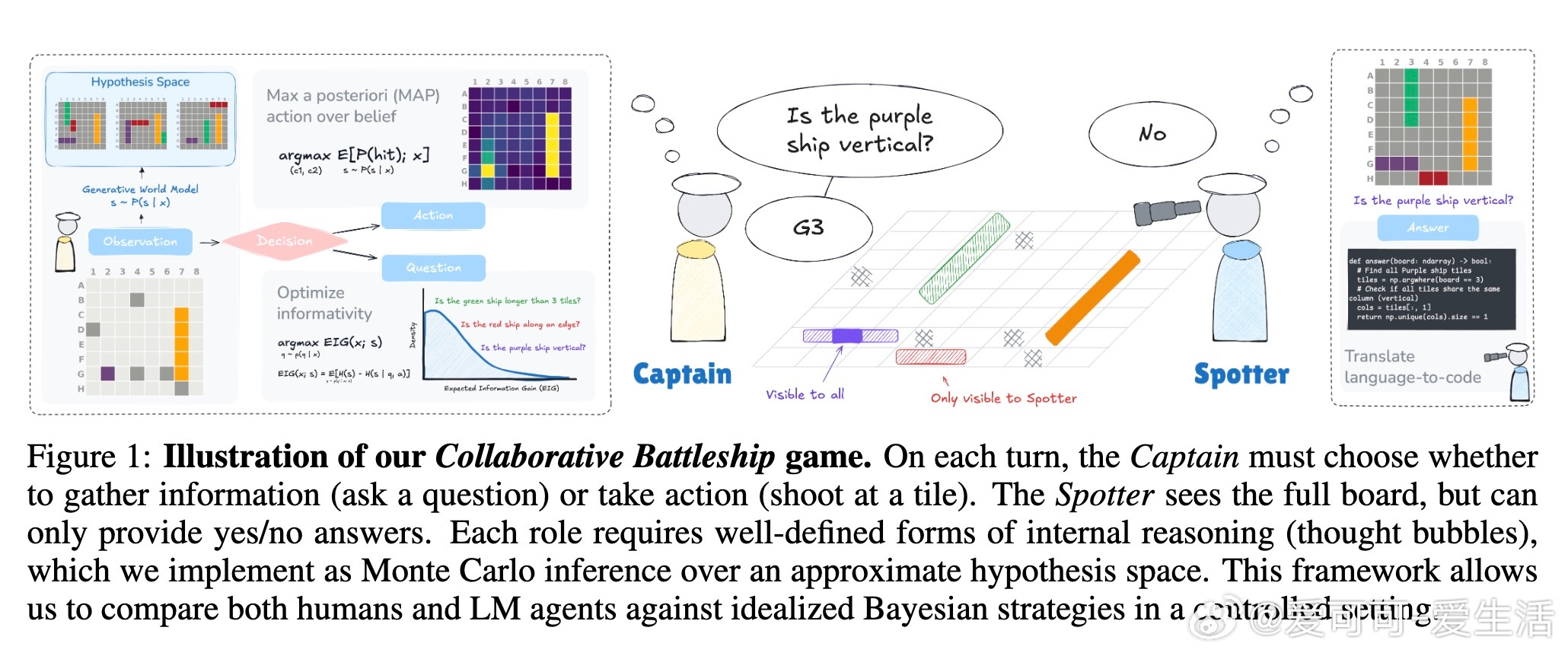
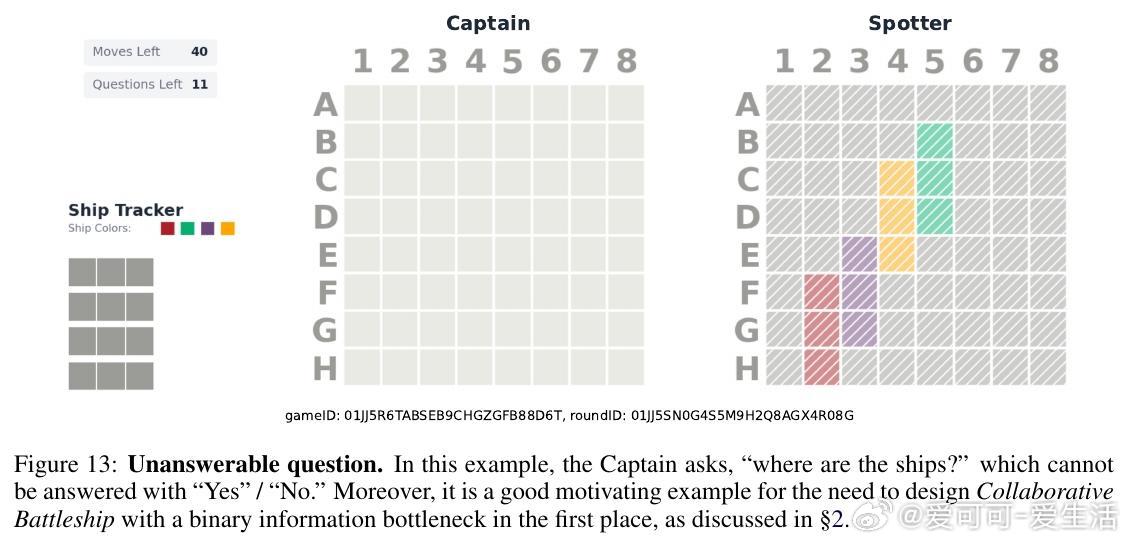
本文围绕“Collaborative Battleship”(协作版战舰游戏)展开,探讨如何构建能像人类一样合理探索并采取行动的智能体。该游戏中,“Captain”仅部分知晓局面,通过提问与行动寻找隐藏舰船;“Spotter”完全知晓局势,但只能给出有限的“是/否”回答。研究旨在评估与提升基于语言模型(LM)的智能体在信息获取与决策中的理性表现。
核心贡献:
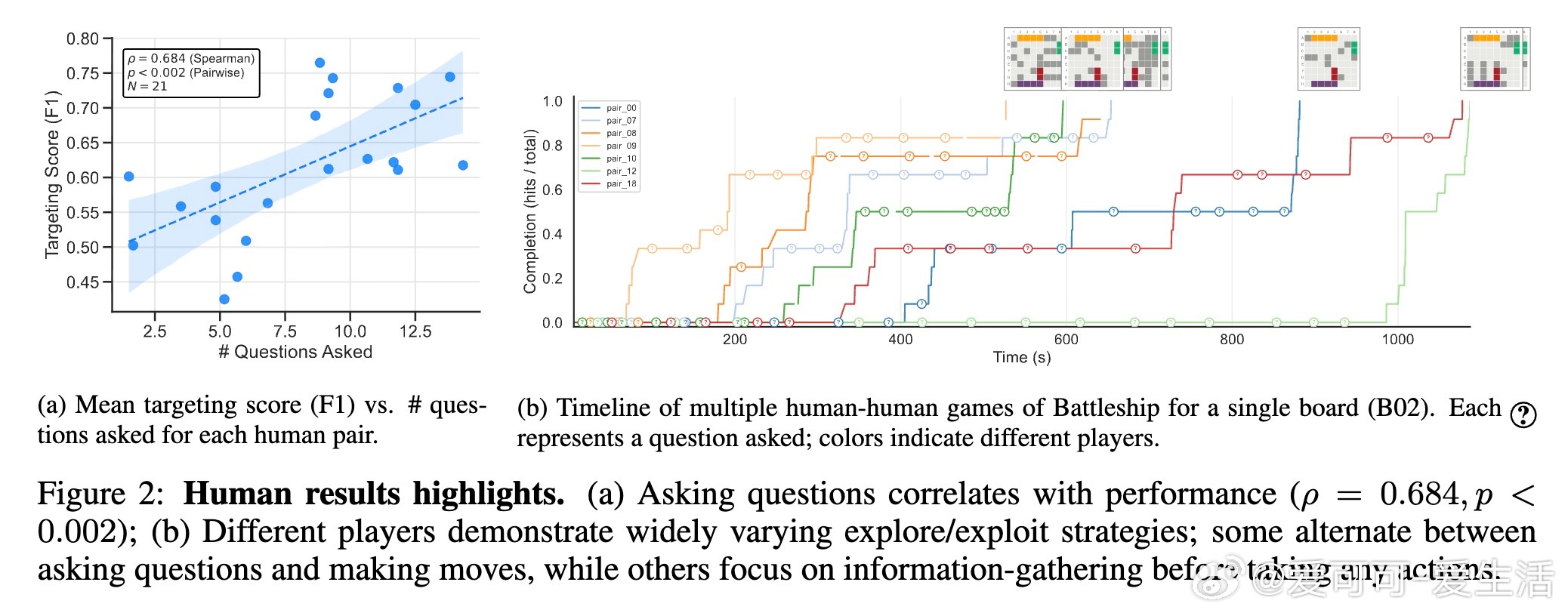
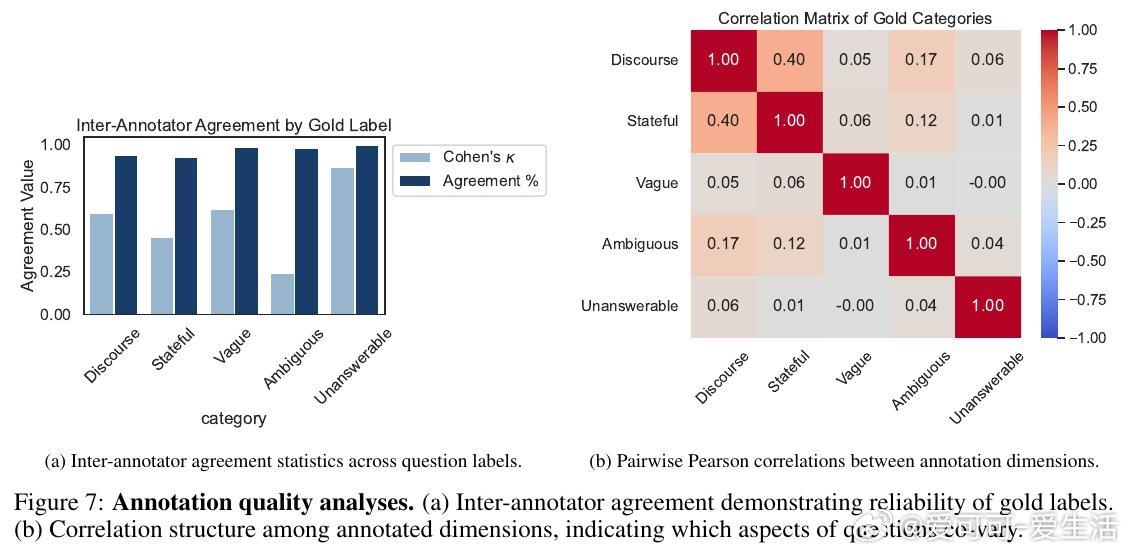
1. 数据集与人类行为研究:收集42名参与者的126局完整对局,建立包含931条高质量提问与回答的“BattleshipQA”数据集,细致标注问题类型(简单、语境依赖、歧义等)及人类提问策略。
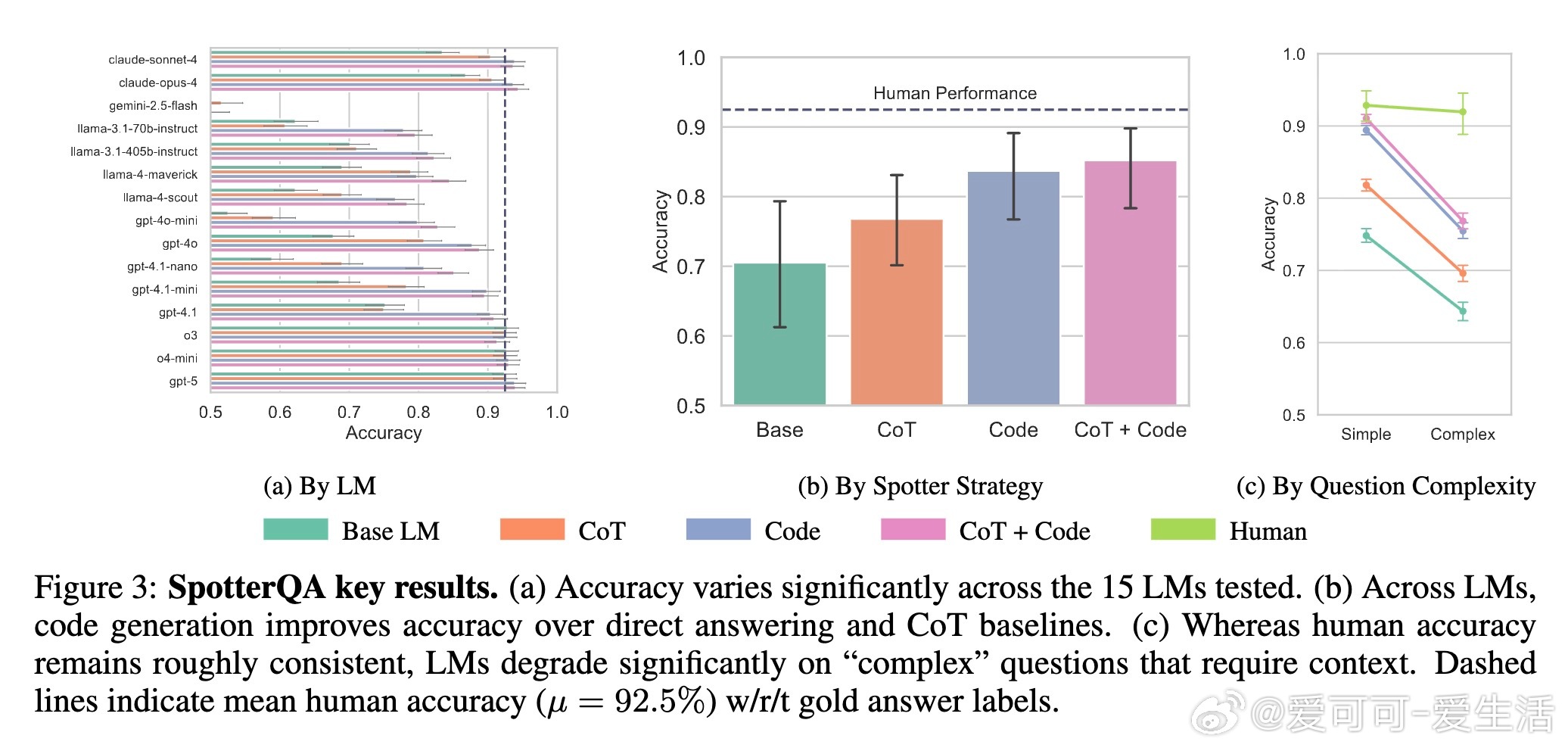
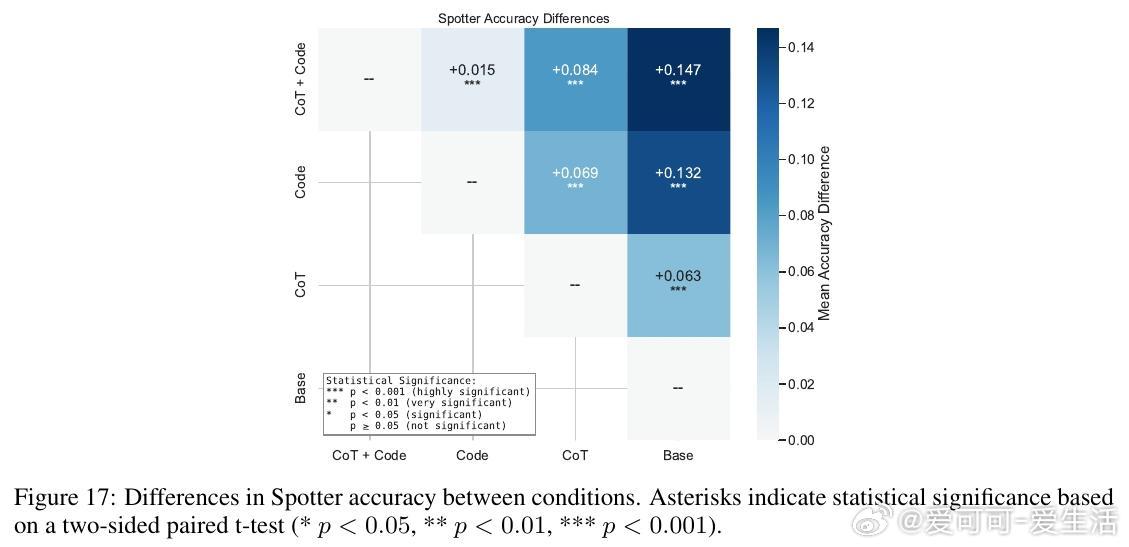
2. 语言模型能力评估:不同LM在回答问题表现差异显著,代码生成辅助(将自然语言问题转为Python程序执行)显著提升准确率(最高提升14.7%),但在复杂语境问题上仍落后于人类。
3. 贝叶斯实验设计框架(BED):借助贝叶斯推理与蒙特卡洛采样,智能体能估算提问的期望信息增益(EIG),合理选择提问与射击目标,平衡探索与利用。
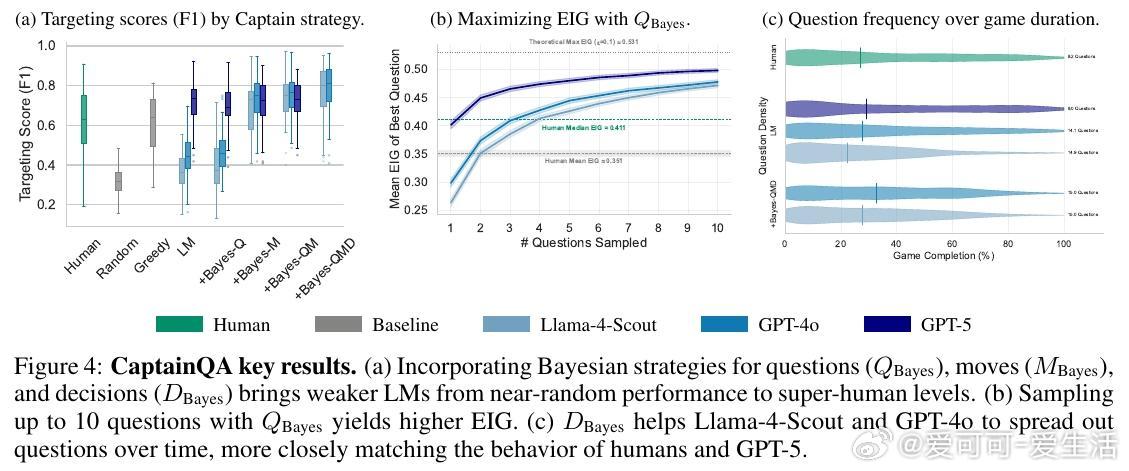
4. 贝叶斯策略效果显著:为较弱LM(如Llama-4-Scout)引入贝叶斯提问、行动与决策策略后,准确率从近似随机提升至超越人类水平(82%胜率),且成本仅为GPT-5的1%左右,体现高效性。
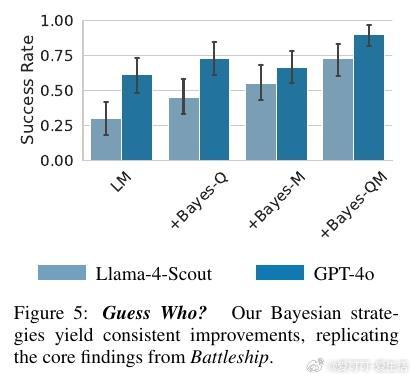
5. 泛化能力验证:在“Guess Who?”猜人游戏中复现方法,成功提升模型表现28.3-42.4个百分点,证明理论与方法具备广泛适用性。
研究亮点:
- 智能体不仅要“答对问题”,更需“问好问题”,即选择能最大限度减少不确定性的提问。
- 通过贝叶斯信念更新,智能体动态调整对局面假设的概率分布,支持理性决策。
- 人类玩家并非完美贝叶斯优化者,但展现出高效且多样化的探索策略,启发算法设计。
- 结合语言模型生成能力与概率推理机制,能显著弥补单纯语言模型在复杂推理与上下文理解上的不足。
未来方向:
- 加强对模糊、歧义及语境依赖问题的语用推理能力。
- 学习并适应不同信息源的可靠性(如估计Spotter回答的错误率)。
- 将贝叶斯策略推广至更复杂的现实世界任务,结合视觉、交互等多模态信息。
- 探索人机协作场景下的智能体设计,提升协同效率与自然交互体验。
结语:
本文首次系统地将贝叶斯实验设计融入语言模型智能体的提问与行动决策中,结合实证的人类行为数据,提出高效且理性的探索框架,为构建可在复杂环境中主动获取信息并合理行动的智能体奠定了坚实基础。
全文及数据代码详见:arxiv.org/abs/2510.20886
项目主页:gabegrand.github.io/battleship