[CL]《Code-enabled language models can outperform reasoning models on diverse tasks》C E. Zhang, C Colas, G Poesia, J B. Tenenbaum... [MIT & Inria] (2025)
传统的推理模型(Reasoning Models,RMs)通过大规模强化学习训练,虽提升了语言模型(Language Models,LMs)在复杂推理任务上的表现,却训练成本高昂、推理耗时且资源消耗大。本文提出了一种经济高效的替代方案——CodeAdapt,结合了CodeAct框架(允许LM多轮交替使用自然语言与可执行代码进行推理)和一种轻量级的少样本自适应学习策略(Generalization-guided Few-shot Learning,GFL),仅需5个训练样例即可实现显著性能提升。
【核心贡献】
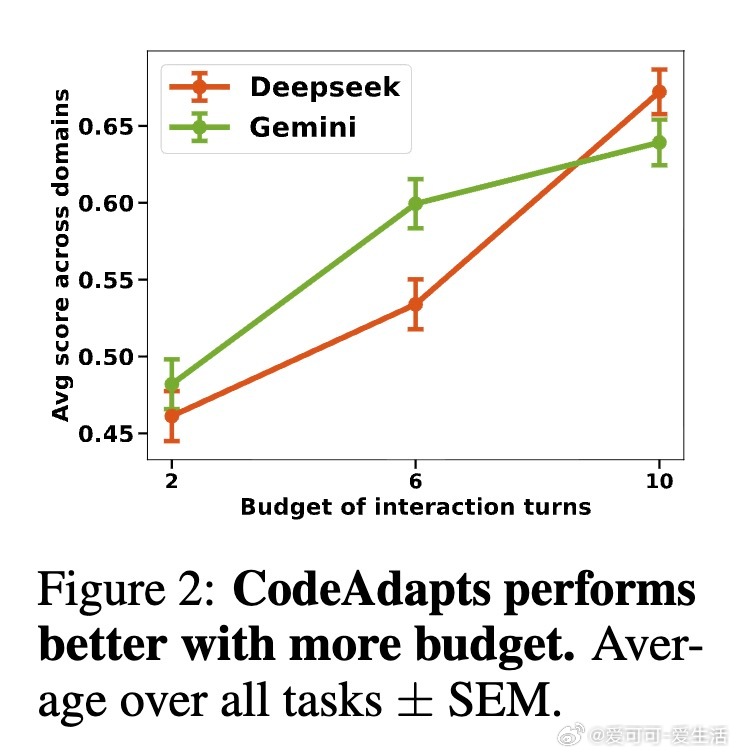
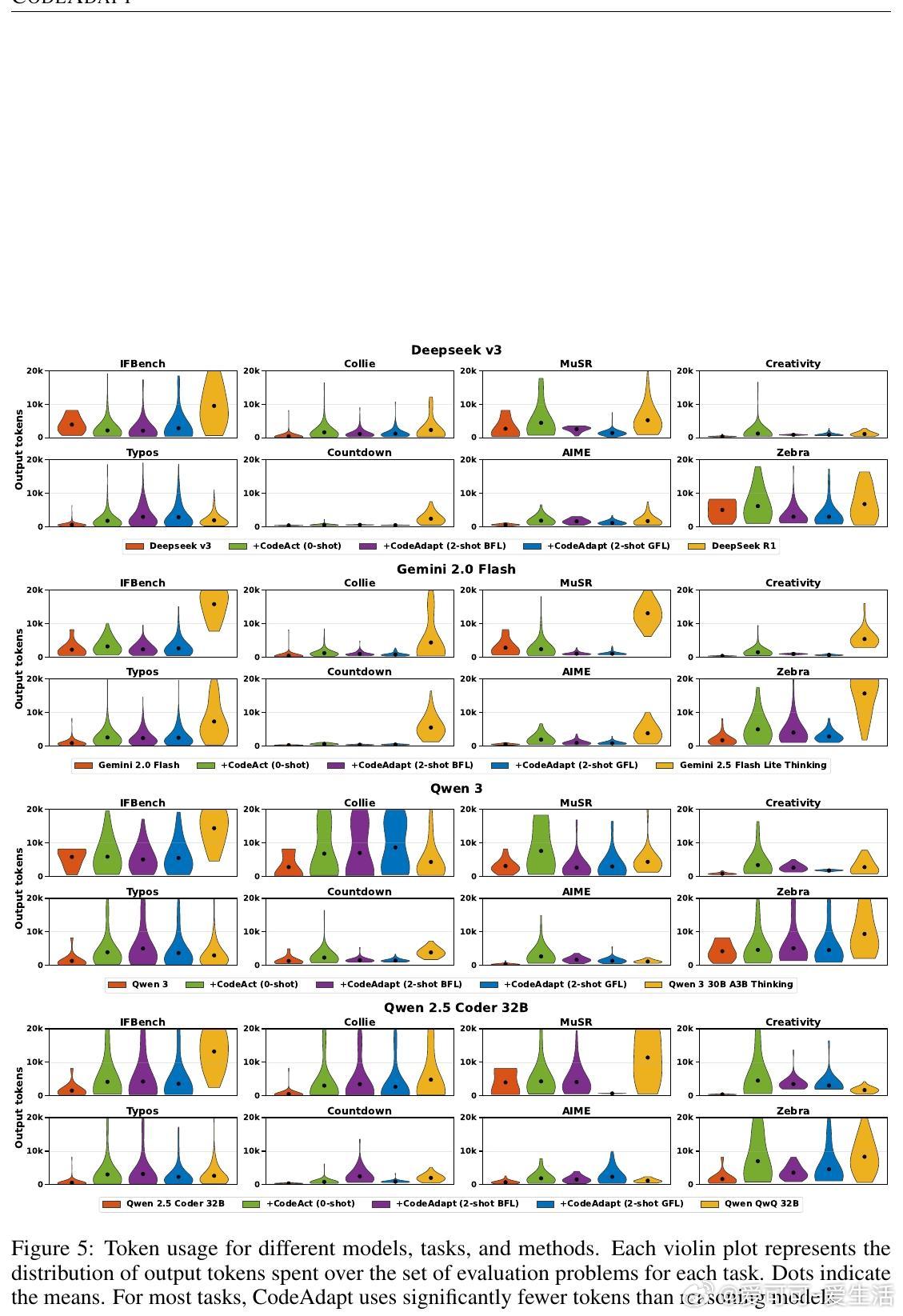
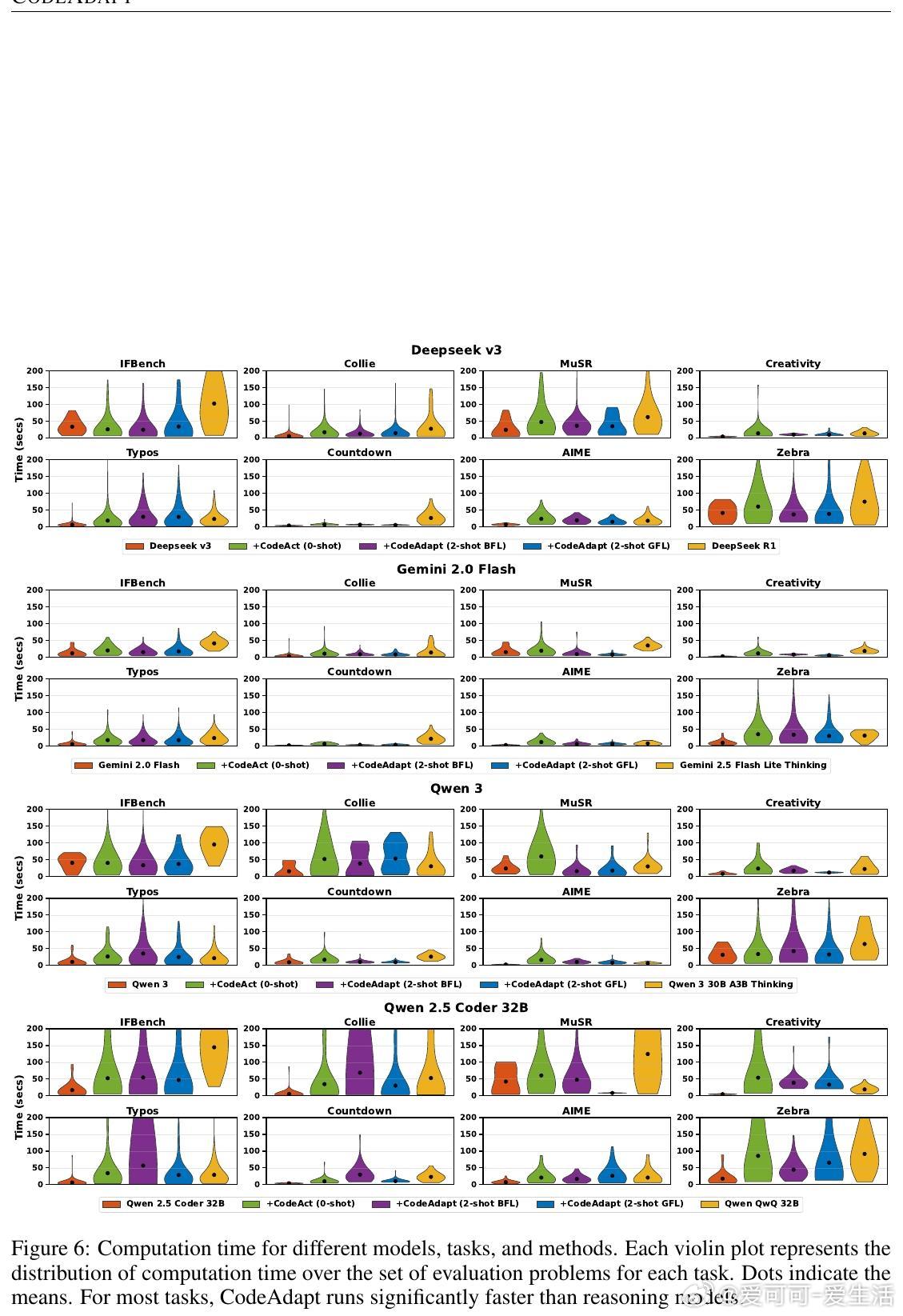
1. 性能超越:在涵盖指令执行、语言处理、数学逻辑等8个任务中,CodeAdapt支持的标准指导型LMs平均超过对应强化学习训练的RMs,部分任务提升达35.7%,且推理时的token使用效率提高10%-81%。
2. 资源节约:训练成本仅为RMs的极小部分(约几十美元级别),推理速度更快,消耗的计算资源明显降低。
3. 混合推理架构:将自然语言推理与符号化代码执行结合,模型能动态选择策略、分解子任务、迭代验证,表现出类人认知中的元认知能力(如进度监控、策略调整、资源管理)。
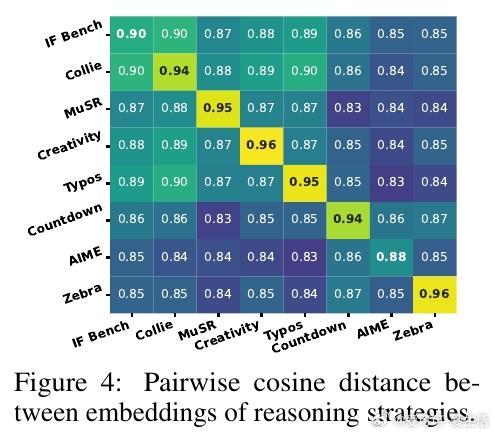
4. 任务适应性强:不同任务触发不同的代码与语言推理比例,展现出灵活应对多样问题的能力。比如逻辑约束问题重度依赖代码执行,而创造性任务则更多依赖语言表达。
5. 认知科学启示:支持“思维程序化”理论,即人类思考可能依赖于类似程序的表征,且自然语言本身可作为认知的基本形式之一。
【方法亮点】
- CodeAct框架允许LM以多轮对话形式生成并执行Python代码,实现精确计算、验证和问题分解。
- GFL通过评估解答在训练集外的泛化表现,挑选最具代表性和迁移性的少样本示例进行上下文引导,避免了强化学习的高昂开销。
- 灵活的推理预算管理保障系统在有限资源内高效完成推理。
【实验概况】
- 评测模型覆盖DeepSeek、Gemini、Qwen等多家主流开源及API模型。
- 任务涵盖:Instruction Following(指令执行)、Language Processing(语言理解与生成)、Formal Reasoning(数学逻辑)。
- CodeAdapt在绝大多数任务和模型上均领先强化学习训练的RMs,特别是在语言任务表现更稳定,RL训练有时反而效果有限。
- 资源消耗方面,CodeAdapt推理速度提升16%-47%,token使用减少10%-80%。
【未来展望】
- 探索结合更多工具(如互联网检索)、引入更丰富库及跨模型调用,提升系统通用性与智能水平。
- 进一步结合RL训练与CodeAdapt,打造更强大的多模态推理系统。
- 深入研究人类认知机制启发的混合推理架构,推动AI系统更贴近人类思维方式。
全文链接:arxiv.org/abs/2510.20909
总结:CodeAdapt表明,通过融合代码执行能力与少样本自适应学习,标准语言模型即可实现强大且高效的推理能力,这为构建经济实用的智能系统提供了全新思路,也为认知科学与AI系统设计架起了桥梁。