[LG]《Priors in Time: Missing Inductive Biases for Language Model Interpretability》E S Lubana, C Rager, S S R. Hindupur, V Costa... [Goodfire AI & Harvard University] (2025)
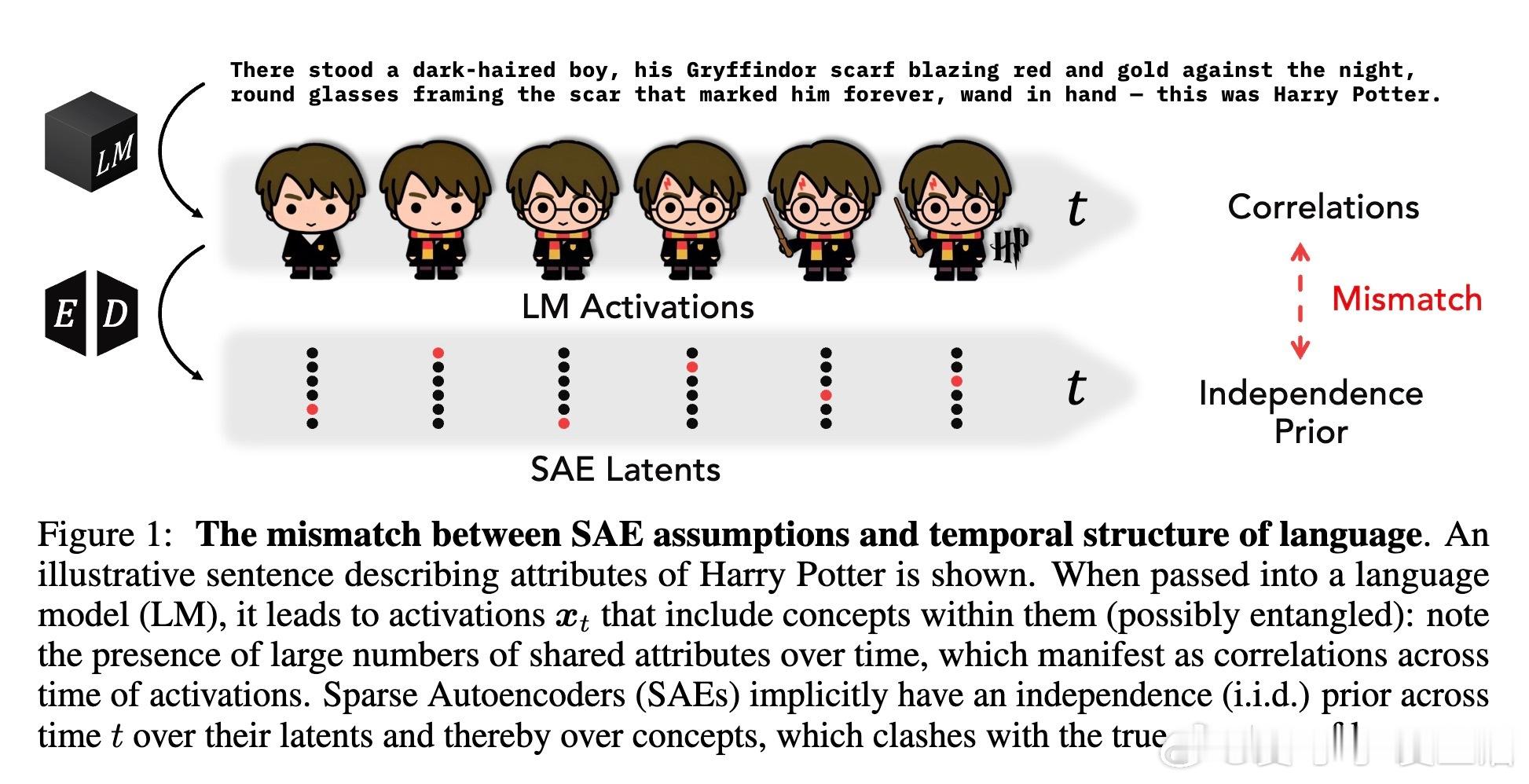
在理解大型语言模型(LLM)内部机制时,提取有意义的“概念”至关重要。传统的稀疏自编码器(Sparse Autoencoders,SAEs)假设激活模式中概念在时间维度上相互独立且平稳,但本文指出,这与LLM激活表现出的丰富时间动态严重不符。具体表现为:
1. LLM激活的时间结构特点:
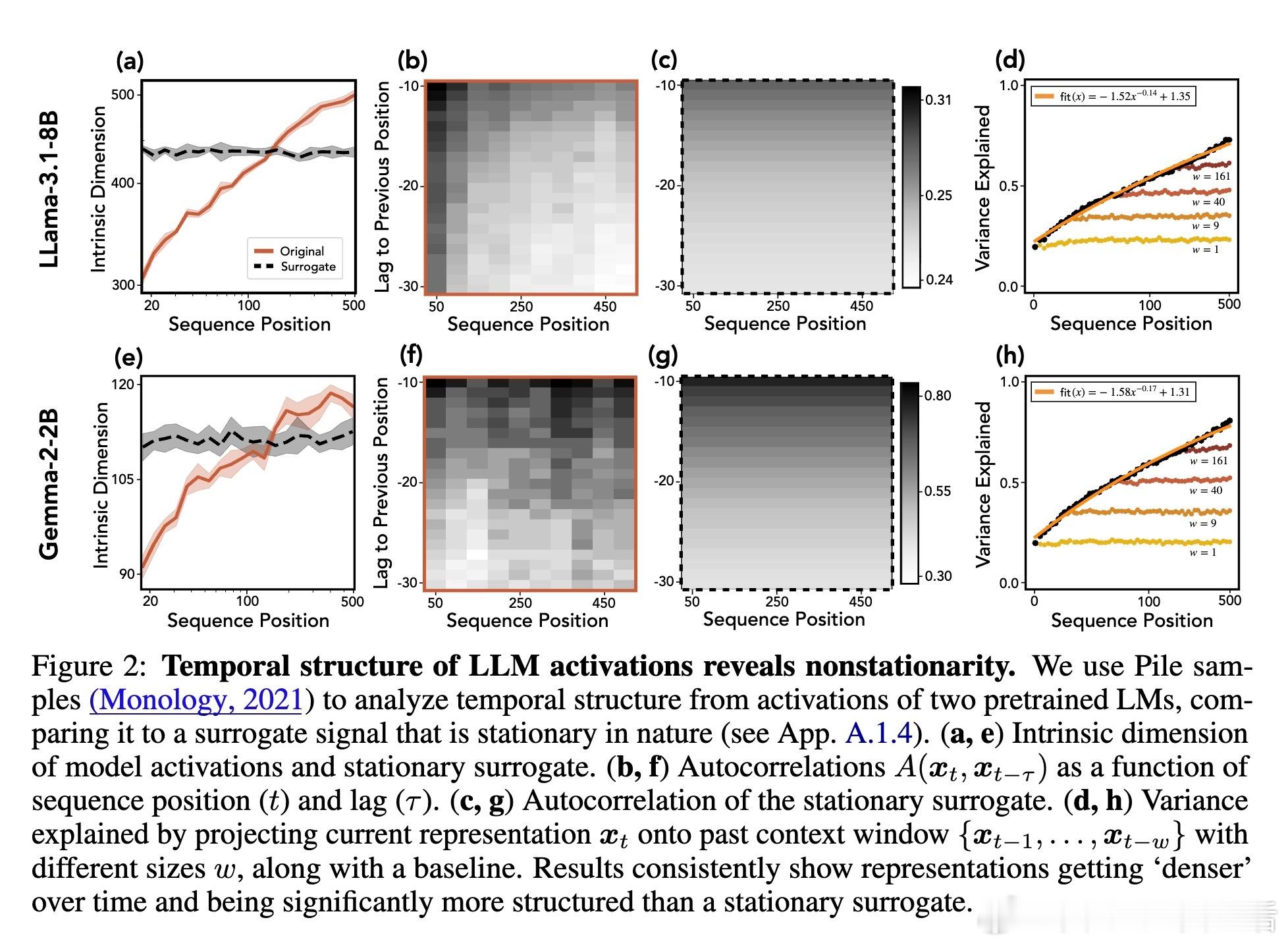
- 表现出随着序列推进,概念维度逐渐增多(内在维数增加)。
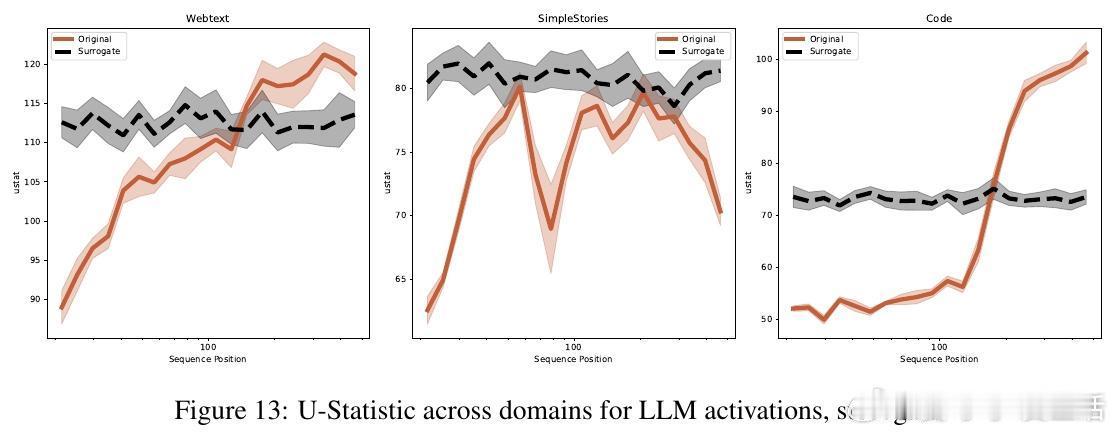
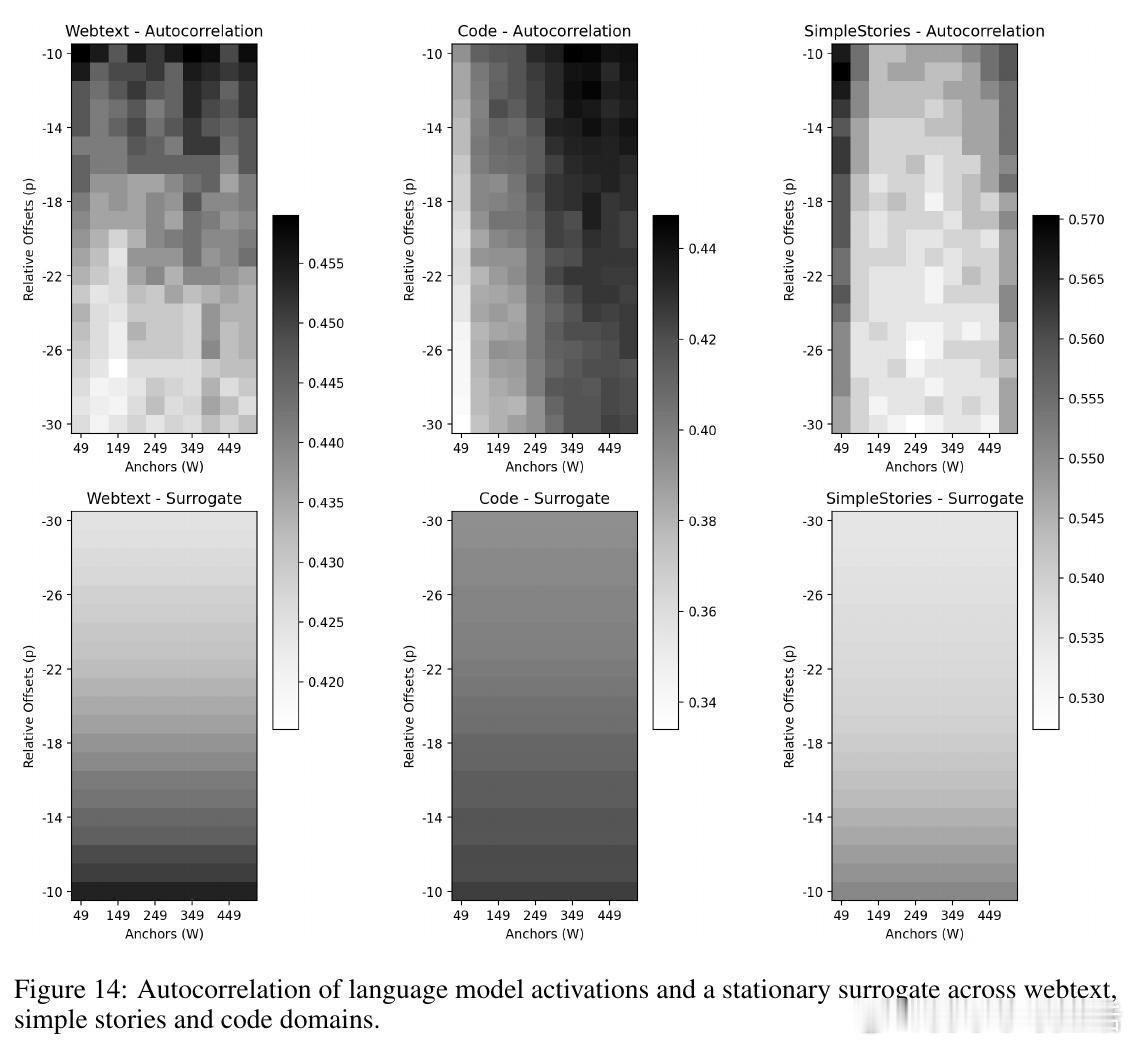
- 激活在不同时间点间存在强相关性,且这种相关性随上下文变化而变化,表现出非平稳性。
- 当前激活的大部分方差信息可由过去上下文预测。
2. SAEs的隐含假设及其局限:
- SAE从贝叶斯角度隐含对潜变量(latents)时间独立且同分布的先验,忽略时间相关性。
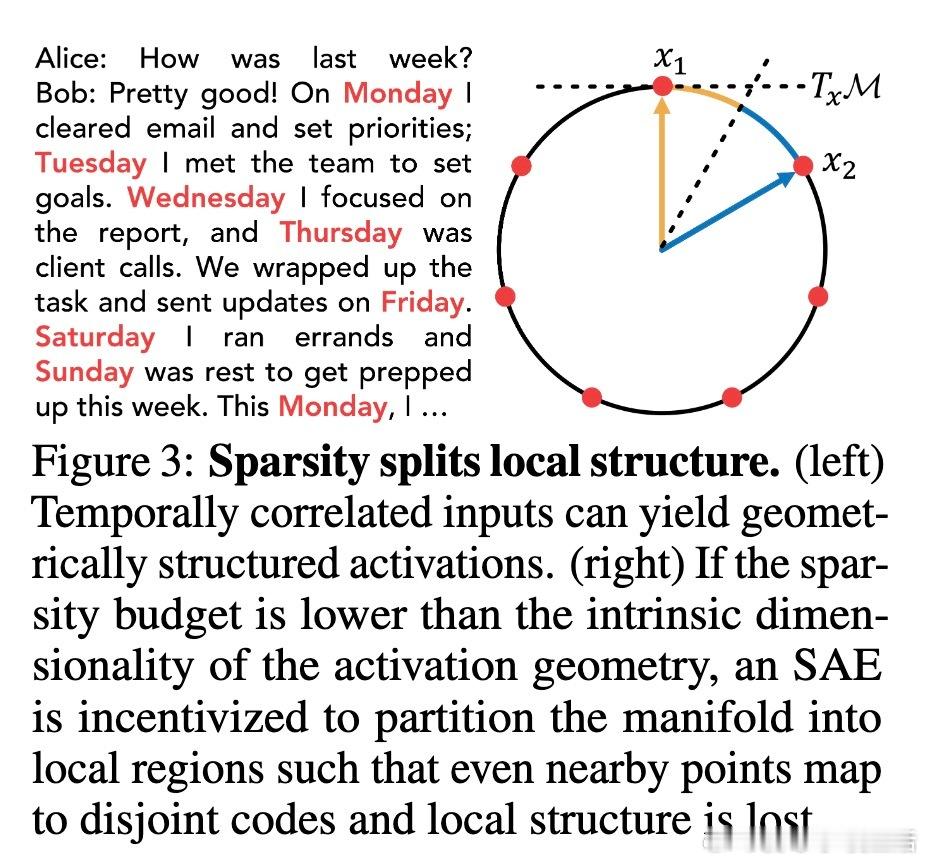
- 该假设导致SAEs无法捕获激活中的时间相关结构,且假设激活稀疏度恒定,难以适应激活随着时间“变密”的事实。
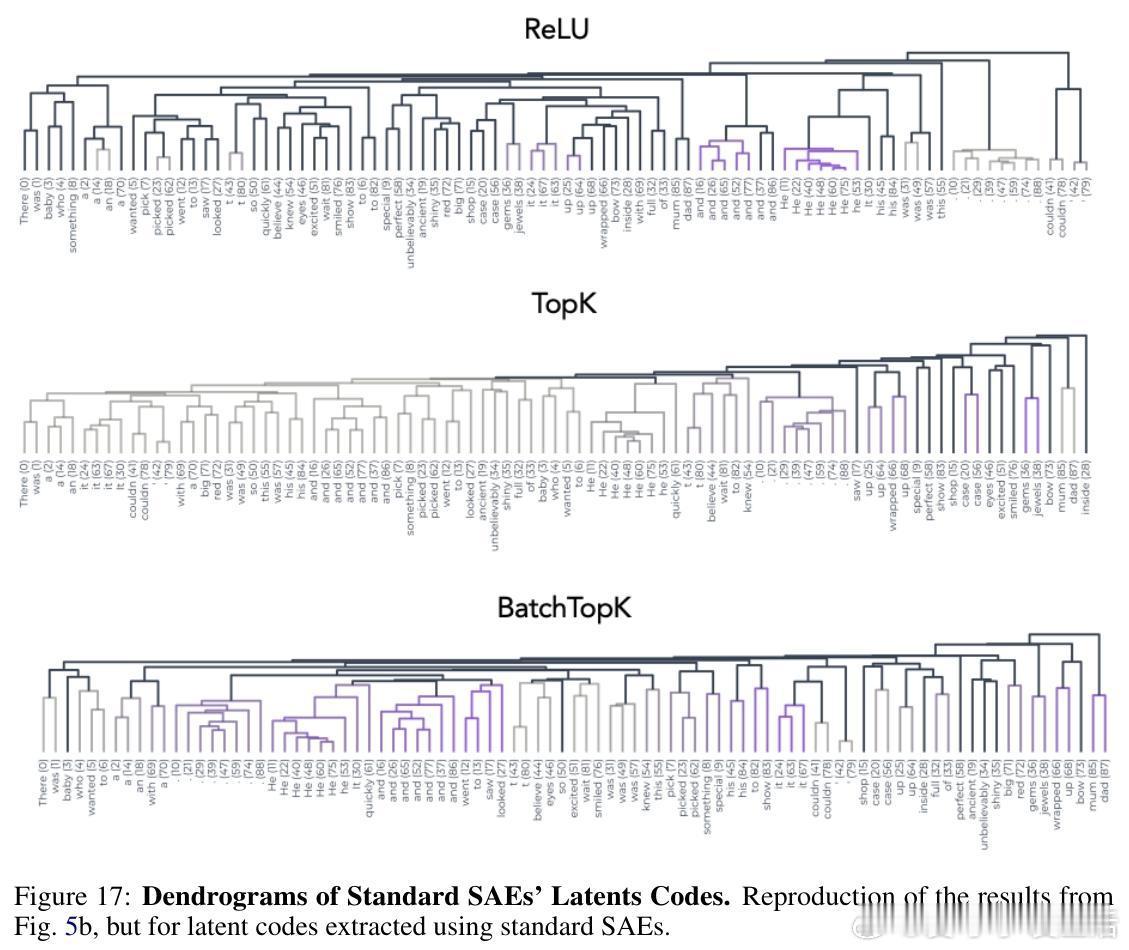
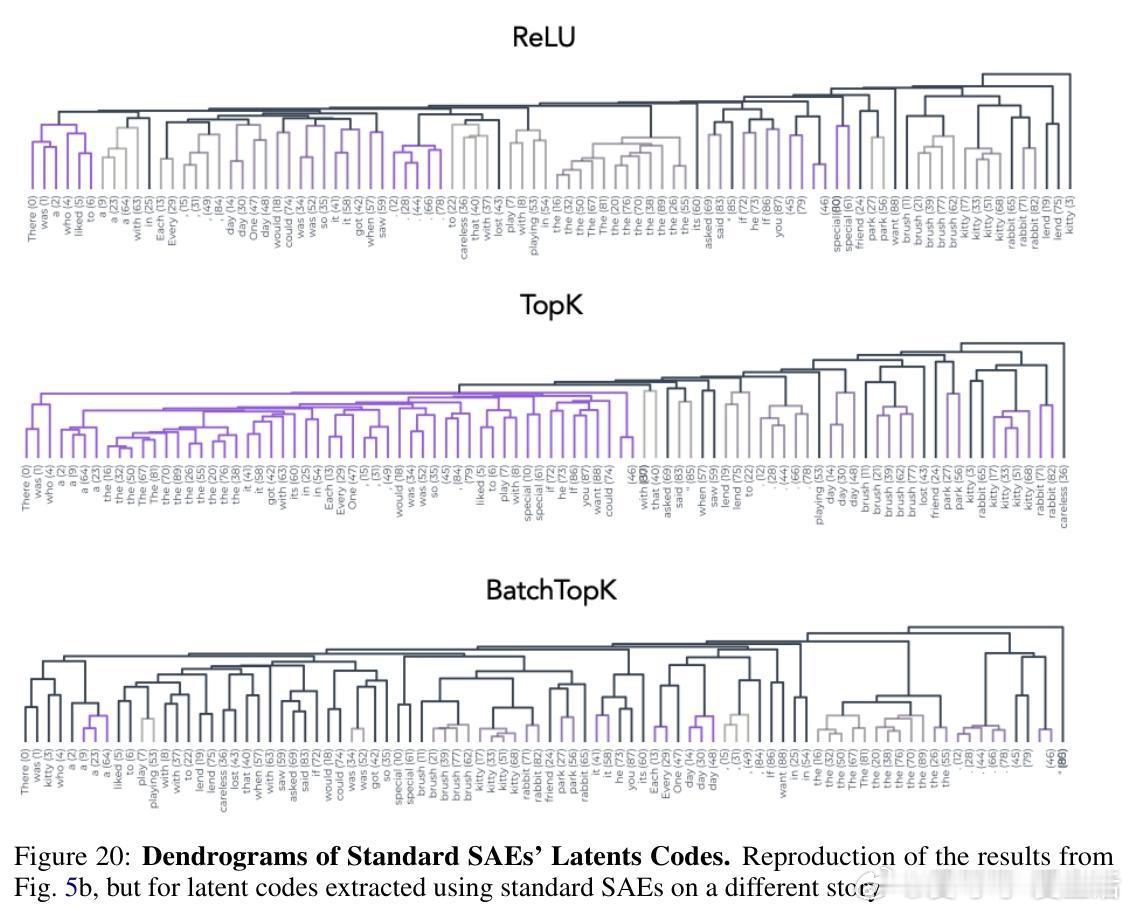
- 当激活维度超过预设稀疏预算时,SAEs会出现“支持切换”现象,即相邻时间点激活代码大不相同,破坏局部时间连续性和语义结构。
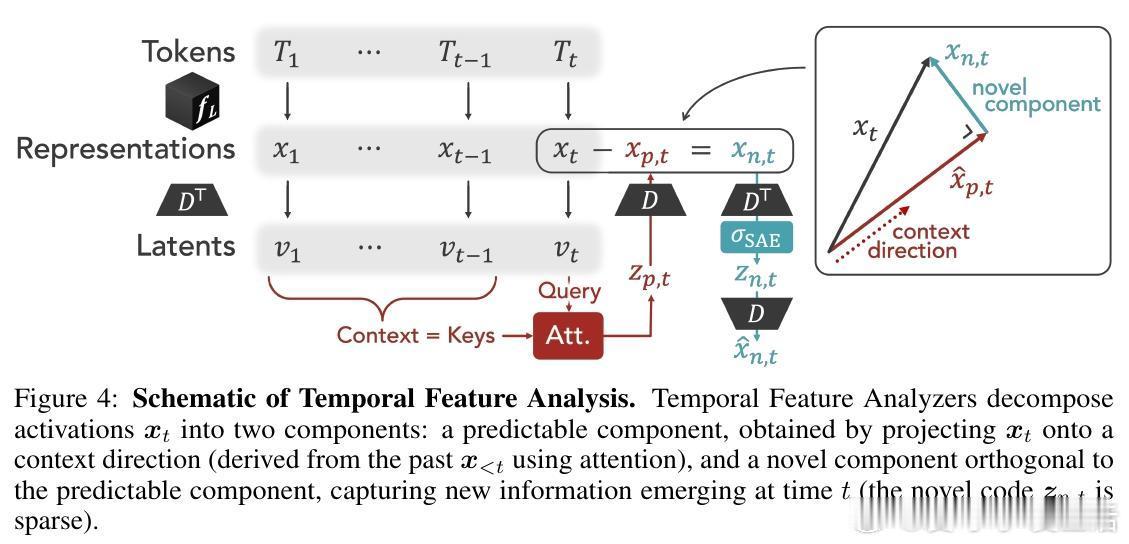
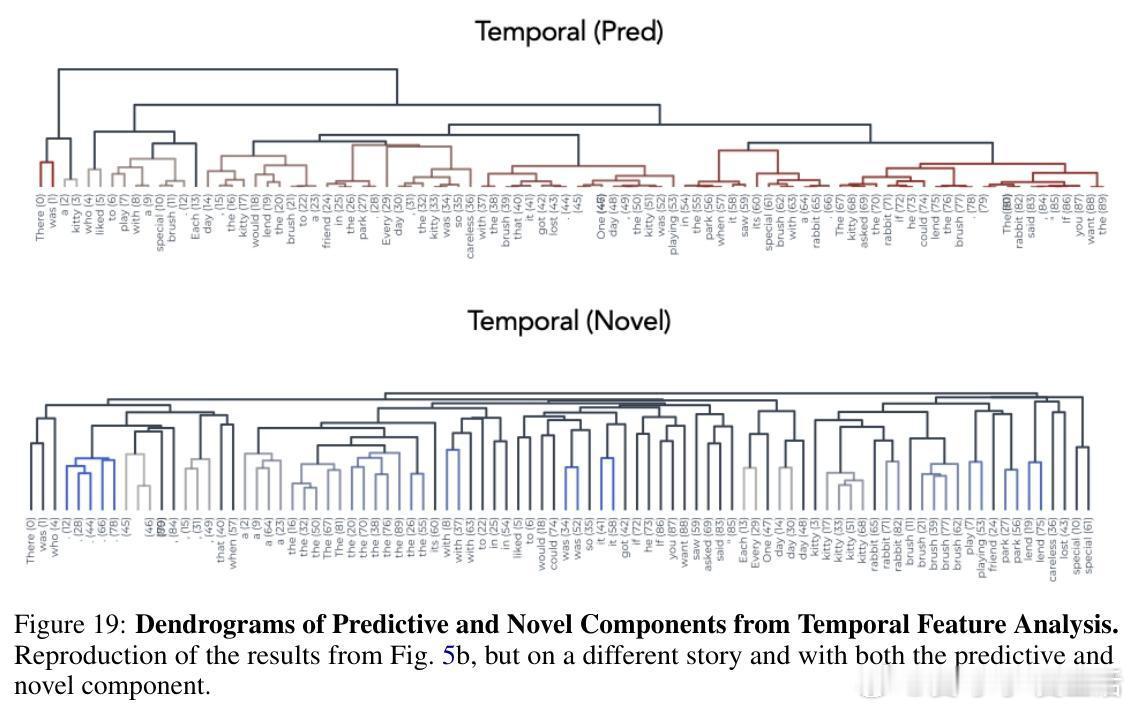
3. 提出“时间特征分析”(Temporal Feature Analysis,TFA):
- 受神经科学启发,TFA将激活分解为“可预测成分”(predictable component)和“新颖成分”(novel component)。
- 可预测成分由当前激活在过去上下文子空间上的投影构成,捕获慢变、上下文相关的信息。
- 新颖成分为残差,捕获当前时间点新增、快速变化的信息,具有稀疏性。
- 训练目标是重构激活,惩罚新颖成分的稀疏度,允许可预测成分自由表达上下文依赖。
4. TFA的优势及实验证明:
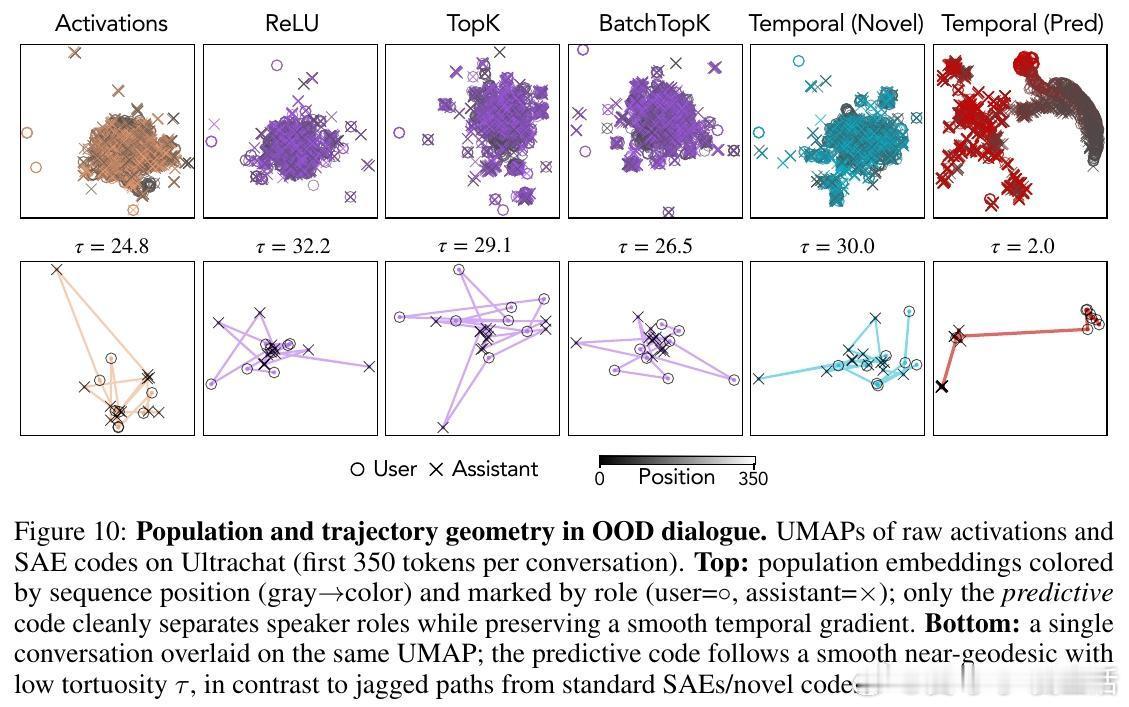
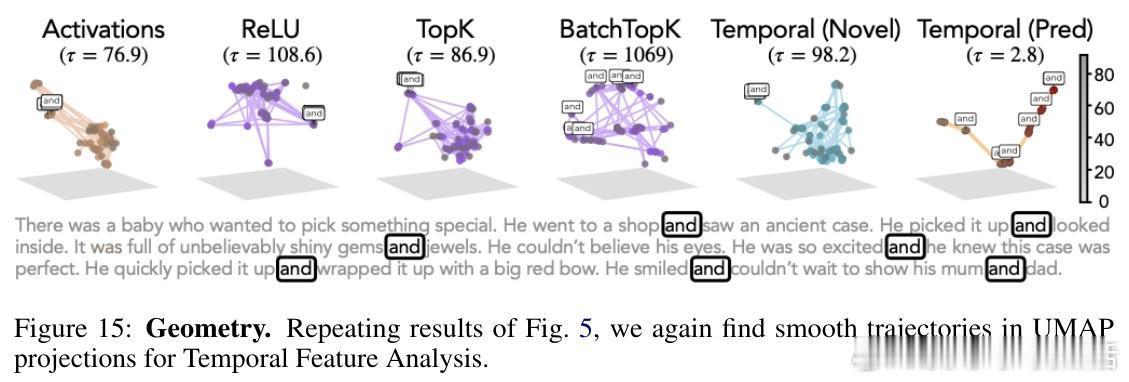
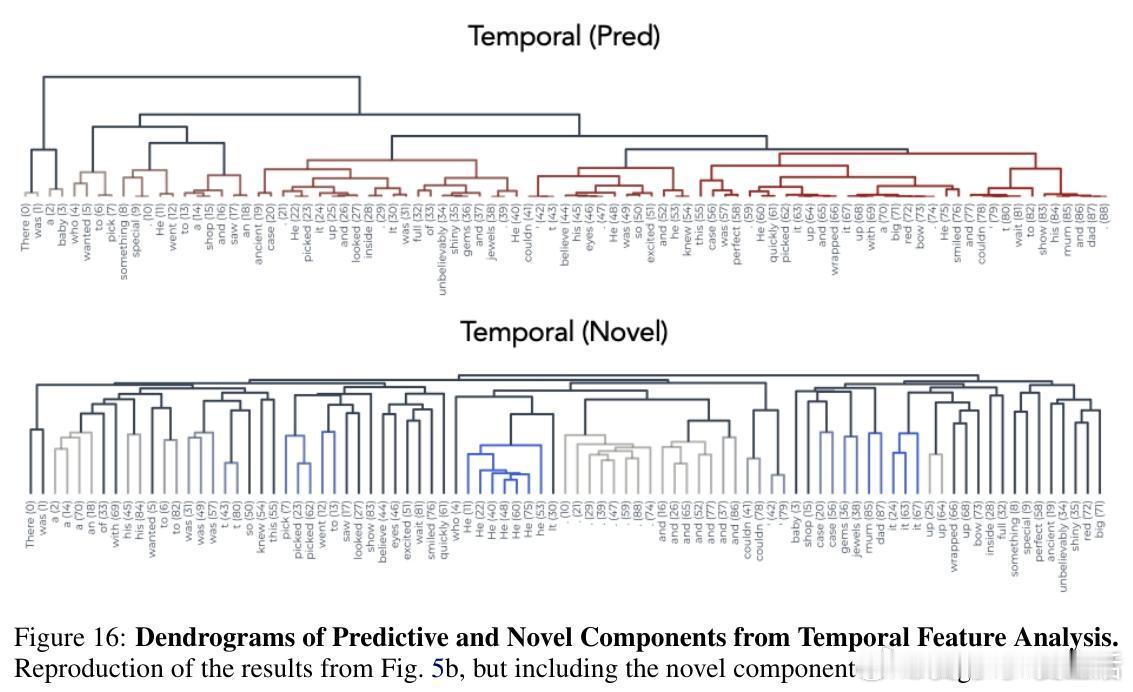
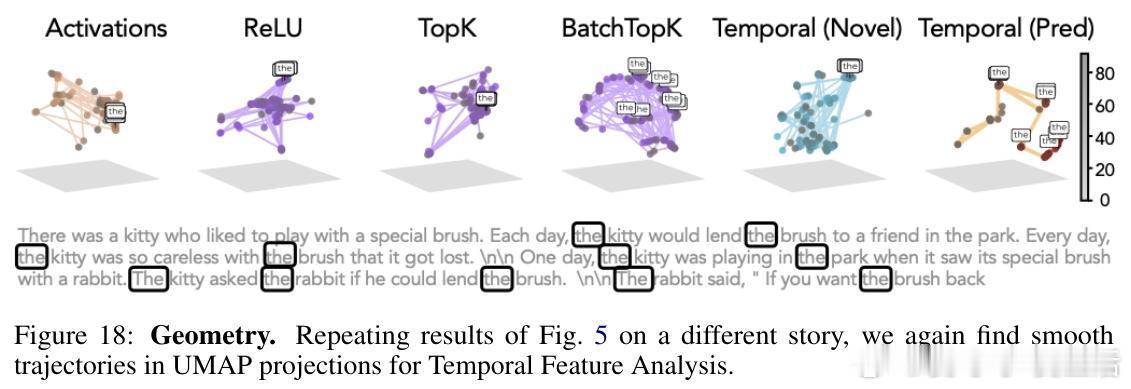
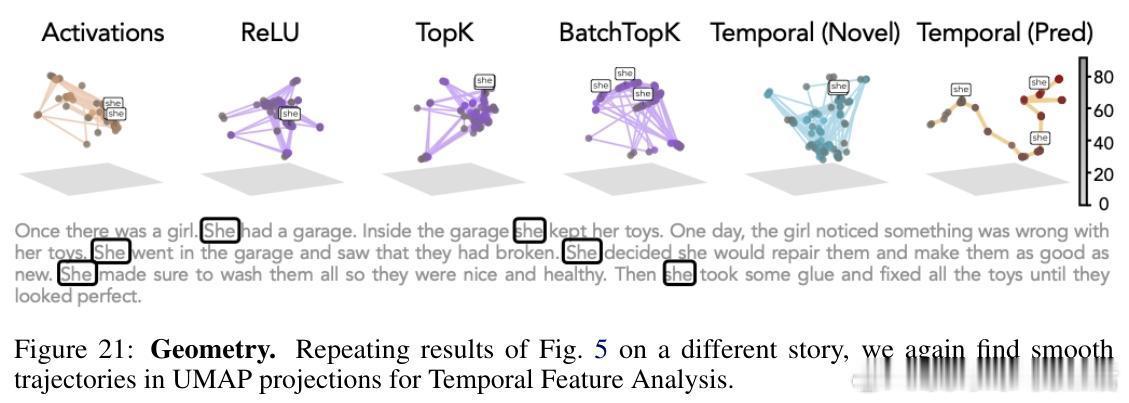
- 在故事解析中,预测成分刻画了事件边界,呈现平滑的时间轨迹,类似神经科学中的“时间展开”现象。
- 在语义歧义的“花园路径句子”中,TFA预测成分正确捕获长期依赖,恢复正确句法结构,而传统SAEs仅捕获局部、短期信息。
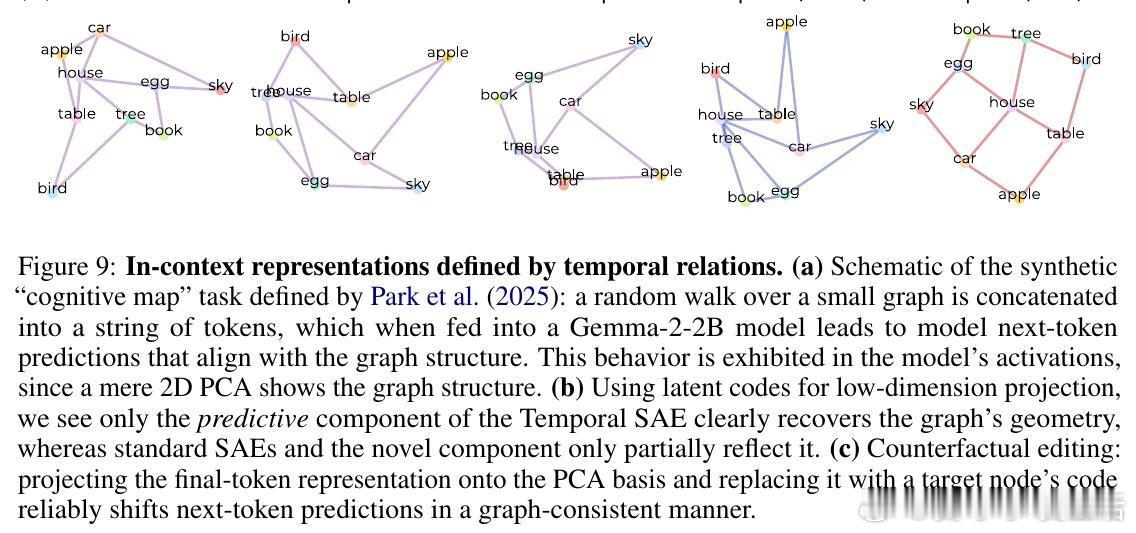
- 在上下文构造的认知图谱任务中,预测成分重现了图结构,并支持通过干预latent实现语义调整,体现强大的时序推理能力。
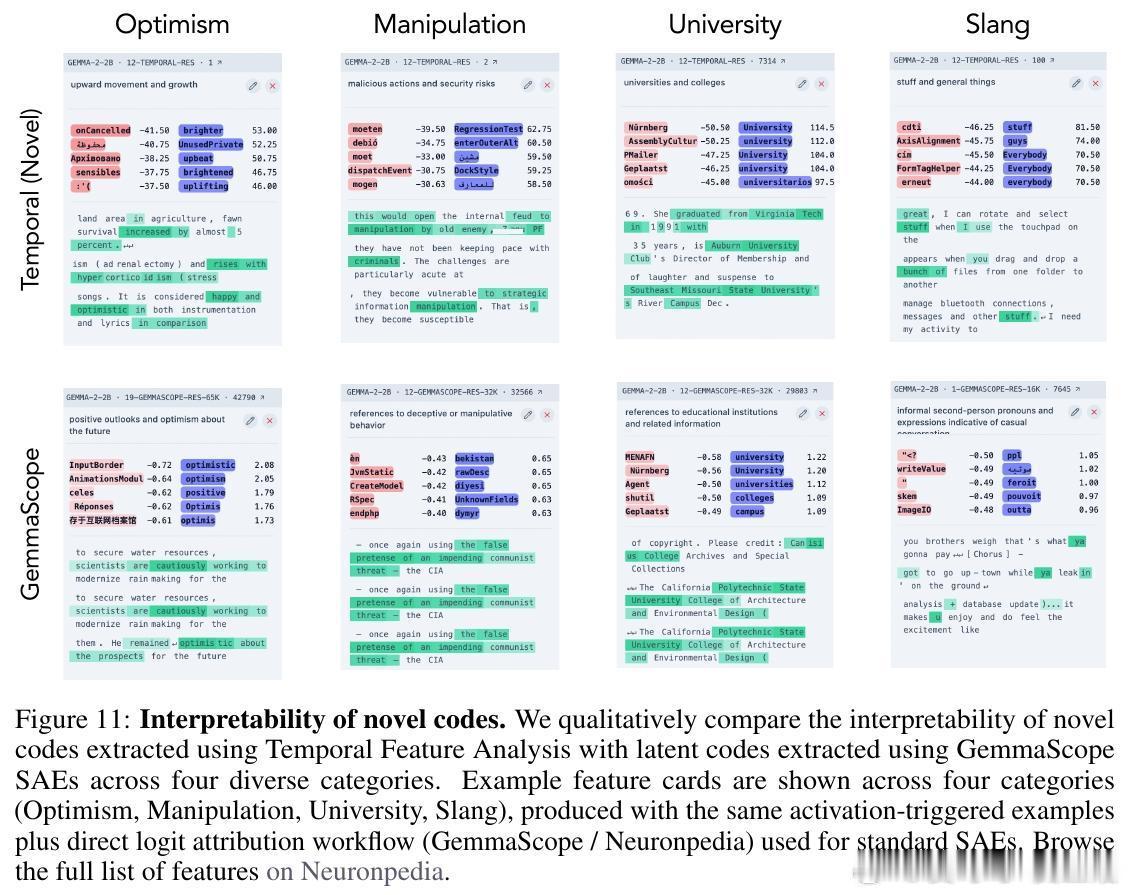
- 新颖成分仍保持传统SAE的自动可解释性,可生成清晰的语义特征卡片。
5. 理论与实践意义:
- 传统SAEs的时间独立先验与语言模型激活的时间相关性不匹配,限制了其解释能力。
- 引入符合数据真实动态的时间先验(如TFA)能更好地捕获模型计算机制,提升解释的鲁棒性和准确性。
- 未来方向包括将特征视为低维流形而非孤立方向,探索更丰富的时间相关正则化,以及更深入的因果干预评估。
总结:本文强调,为了更准确地解读语言模型的内部表征,必须设计与语言数据时间动态相匹配的归纳偏置。时间特征分析作为一种新的解释框架,突破了传统稀疏编码的限制,从时序角度揭示了语言模型的深层结构与机制,促进了人工智能与神经科学的交叉理解。
论文地址:arxiv.org/abs/2511.01836