过去一年,具身智能行业最常见的叙事,是“机器人的ChatGPT 时刻即将到来”。
它把外界的注意力集中在模型是否足够聪明上,却忽视了具身智能与大语言模型最本质的差异:大语言模型只需要在数字世界里生成答案,机器人却必须在真实世界里承担后果。
这正是近日举行的IEEE国际机器人与自动化会议(ICRA 2026)释放出的更冷静信号:具身智能正在从模型想象力阶段,进入真实世界验证阶段。
作为全球机器人与自动化领域最具影响力的国际会议之一,ICRA 被称为机器人学界的“奥林匹克”。身处国内具身智能第一梯队的原力灵机受邀出席大会并进行了学术分享。同时,由原力灵机与智元机器人联合举办的 RoboChallenge ICRA Competition 2026 也在维也纳现场完成颁奖,原力灵机联合创始人汪天才作为颁奖嘉宾,为获奖团队颁奖。不同于传统单点抓取比赛,这项赛事通过 API 远程接入真实机器人,完成了商超场景下从自主导航、识别取货到移动放置的全链路操作闭环。
成立于 2025 年的原力灵机在行业内首提“具身原生”理念,其具身原生大模型 DM0 在真机评测中位居全球第一;同时公司还发布了全球第二、国内唯一的通用具身智能开源框架 Dexbotic。
这届 ICRA 亮相背后,原力灵机试图回答的不是单点技术问题,而是一个产业命题:谁能把数据、模型、框架、评测和场景打通成一套可复现的闭环,谁才可能真正推动具身智能从 Demo 走向产业。

RoboChallenge ICRA Competition 2026颁奖现场

DM0,
验证具身原生路线领先性
具身原生大模型 DM0 最值得关注的地方,是它挑战了当下行业的常规叙事:仅有 2.4B 参数量,却在 RoboChallenge 真机评测中位居全球第一。如果只理解为一次榜单成绩,反而低估了它的产业意义。
DM0背后是原力灵机对具身原生的底层思考:具身模型不能依赖互联网 VLM 再叠加动作数据的“后装式路线”。具身模型必须一开始就用多源数据,面向多本体训练。而且,模型不应盲目追求大参数,应该在有限参数内探索模型能力天花板。
第一、验证具身原生多源数据范式的优势
过去不少 VLA 模型是先用互联网数据训练出视觉语言模型,再在此基础上叠加一部分 action data 或机器人数据,让模型学会输出动作。但问题也很明显:这种模型从一开始就不是为物理世界长出来的。
具身原生正是DM0 的不同之处,从第一天起就用多源数据训练。原力灵机联合阶跃星辰、千里科技,将机器人多感知数据、智能驾驶数据与互联网数据纳入同一训练体系,在数据广度、场景复杂度和长尾覆盖上具备明显优势。
第二、多任务、跨机型:让模型学习“操作本质”
不同场景需要不同类型的机器人,每类本体都有自己的结构、自由度、传感器、控制接口和动力学特征。如果每换一台机器,就要重新采集数据、重新训练模型、重新适配系统,具身智能会长期停留在项目制交付:一个客户一套方案,一个场景一套模型。
DM0把多任务、跨机型训练放到了基础模型阶段。其预训练覆盖灵巧操作、环境导航、全身控制三类核心任务和8类机器人本体。这就像老司机换一辆车仍然会开。方向盘轻重、刹车脚感、车身尺寸会变,但驾驶的基本逻辑不变。
第三、小参数模型可能更接近机器人产业现实
过去,AI 行业形成了一种惯性认知:模型参数越大,能力越强。对于具身智能,大参数意味着更高推理成本、更长响应延迟、更大功耗。具身智能不是让机器人拥有一个巨大的大脑,而必须在有限算力、有限功耗、有限时间内也能稳定发挥。
DM0虽然只有2.4B参数,但能实现768×768 高分辨率,实时推理延迟约 60ms,并可在消费级显卡如 RTX 5090 上完成训练与部署。在工业级精细操作任务中,DM0能够识别微小位置差异,稳定执行长程连续任务,并在部分场景中实现亚毫米级精细操作。

Dexbotic,
让具身智能开发告别“手工作坊”
外界对具身智能的关注,往往集中在模型能力和机器人本体上,但真正决定产业发展速度的不是单点模型,而是基础设施。
这正是当前具身智能产业最容易被低估的问题:不是没有聪明模型,而是缺少一套能让模型被高效训练、快速复现、稳定部署的公共开发框架。
这正是Dexbotic的切入点:让具身智能开发从“手工作坊式”,走向“平台化研发流程”。
第一、降低研发门槛
具身智能目前最大的问题之一,是研发链条太长。训练模型要同时处理数据采集、数据清洗、模型结构、训练流程、仿真环境、硬件接口、评测任务、真机部署等问题。任何一个环节不标准,都会拖慢整个系统的迭代速度。这对高校和创业团队尤其不友好。
Dexbotic 支持跨机型、多传感、多源数据混合训练,并围绕数据、训练、评测、硬件和真机部署建立统一流程。它的模块化架构将 Vision Encoder、LLM 与 Action Expert 解耦,使开发者可以替换不同感知模块、认知模块和动作模块,而不是被绑定在某一种模型结构上。
第二、统一具身操作与导航
过去,操作和导航常常被分开作为两套系统处理,机器人很难完成长程连续任务。
Dexbotic 把其放进统一开发框架中,覆盖端到端操作、长时序任务、导航算法,试图让机器人在“手、眼、脑、步”之间形成更完整的闭环,推动具身智能从“动作智能”走向“任务智能”。
第三、统一模仿学习与强化学习
具身智能训练还有一个长期难题:模仿学习和强化学习之间往往割裂。原力灵机与清华大学、无问芯穹展开合作,并与开源强化学习代码库 Rlinf 形成生态协同,实现将模仿学习与强化学习纳入同一开发流程。
这套路径更符合机器人产业现实。在真实场景里,客户并不关心模型用了哪种训练方法,更关心的是成功率、稳定性和故障恢复能力。
Dexbotic 负责 VLA 预训练与监督微调,RLinf 承接强化学习后训练,让模型从通用常识和基础动作能力,进一步走向高成功率的最终策略。

IntentionVLA,
让机器人从“听命令”走向“懂意图”
本届 ICRA 上,原力灵机提出一个全新的VLA 框架IntentionVLA, 引发学界广泛关注。原因并不只是它在实验指标上超过了部分基线模型,而是它切中了具身智能走向真实场景时一个更本质的问题:
机器人不能永远依赖人类给出精确指令,它必须学会理解人类没有说完整的话。
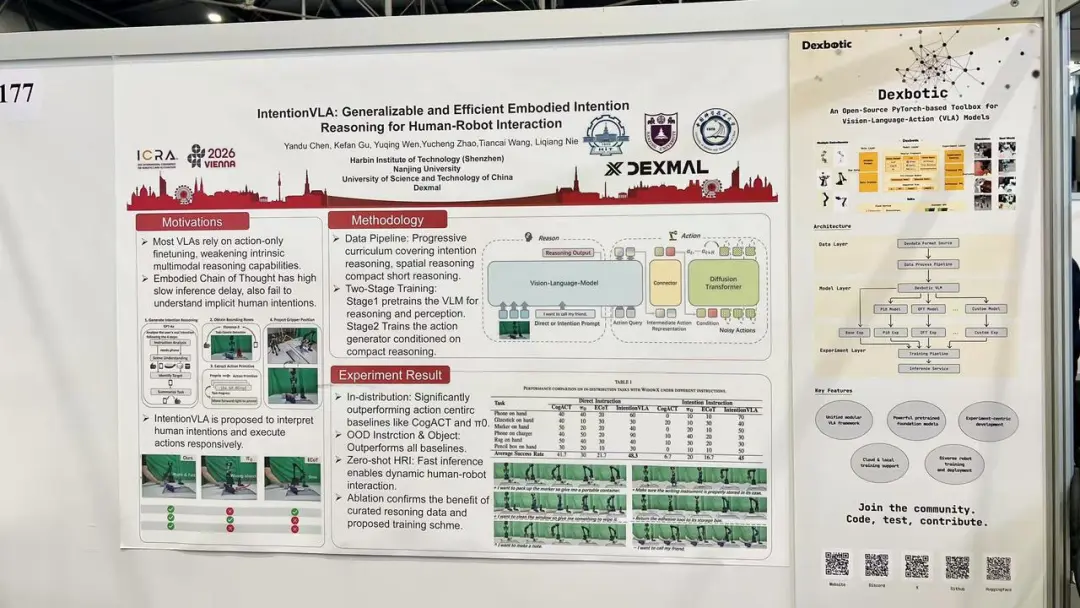
过去很多 VLA 模型,本质上仍停留在“显性指令执行”阶段。指令越标准,表现越稳定;指令越模糊,模型越容易失效。
但真实世界不是这样的。举个例子,人类不一定会对机器人说:“请移动到三号货架,识别绿色饮料瓶,用右臂抓取瓶身中部,然后放入购物车。”
更可能说的是:
“我想喝点东西。”
“帮我拿个适合小朋友喝的。”
“我有点冷。”
“我手不方便,你帮我一下。”
这类任务要求机器人同时具备意图推断、场景理解、物体关系判断、空间定位和动作规划能力。
IntentionVLA的做法是先用定制化推理数据训练模型,把人类意图、空间位置和具身动作之间的关系建立起来;随后在微调阶段,将紧凑的推理输出作为动作生成的上下文引导。
从披露数据看,IntentionVLA直接指令下成功率相比 π0 高出 18%,意图指令下相比 ECoT 高出 28%。在分布外意图任务中,IntentionVLA成功率超过所有基线方法的两倍,并实现了 40% 成功率的零样本人机交互。
可见,IntentionVLA 的产业意义,在于把机器人交互方式向前推进了一步:从“人适应机器人”,转向“机器人适应人”。

RoboChallenge ICRA Competition 2026:实现全链路操作闭环
作为原力灵机与 Hugging Face 联合发起的大规模真机评测平台,RoboChallenge 已吸引近 20 家具身智能企业联合运营,累计服务全球超过 8 万次真机测试,阿里千问、小米、千寻智能等团队也参与其中。它正在为行业建立一套共同的能力坐标:不同模型、不同算法、不同团队,必须在真实机器人和真实任务中接受检验。
本届 RoboChallenge ICRA Competition 2026赛事更进一步,把评测从单点抓取推进到商超场景的全链路任务。机器人不只是“抓一瓶饮料”,而是要根据指令自主导航到货架,完成识别、取货、移动到推车、放置商品的连续流程。

这对具身智能评测来说,意义很大。因为真实场景从来不是单点任务。在商超、仓储、制造和家庭环境里,机器人真正需要完成的是连续工作流。
更关键的是,本届赛事通过 API 远程接入真实机器人,选手用代码直接驱动物理世界。算法必须面对延迟、误差、遮挡、摩擦和执行偏差,无法只停留在仿真或视频展示中。
RoboChallenge把具身智能从“公司自证”,推向统一、开放、可比较的真机评测。而且,它与 DM0、Dexbotic 形成一整套基础设施闭环:模型负责能力,框架负责开发,评测负责验证。
结语
原力灵机在 ICRA 2026 的亮相,并不是简单的技术展示,而是围绕具身智能产业化搭建了一套完整闭环:DM0 解决模型能力,Dexbotic 解决开发基础设施,IntentionVLA 推进人机交互方式,RoboChallenge 则负责真机环境验证。
这四者合在一起,指向同一个趋势:具身智能正在从“谁的机器人看起来更聪明”,转向“谁的机器人能在真实世界中被复现、被评测、被部署”。
END本文为「智能进化论」原创作品,欢迎关注。