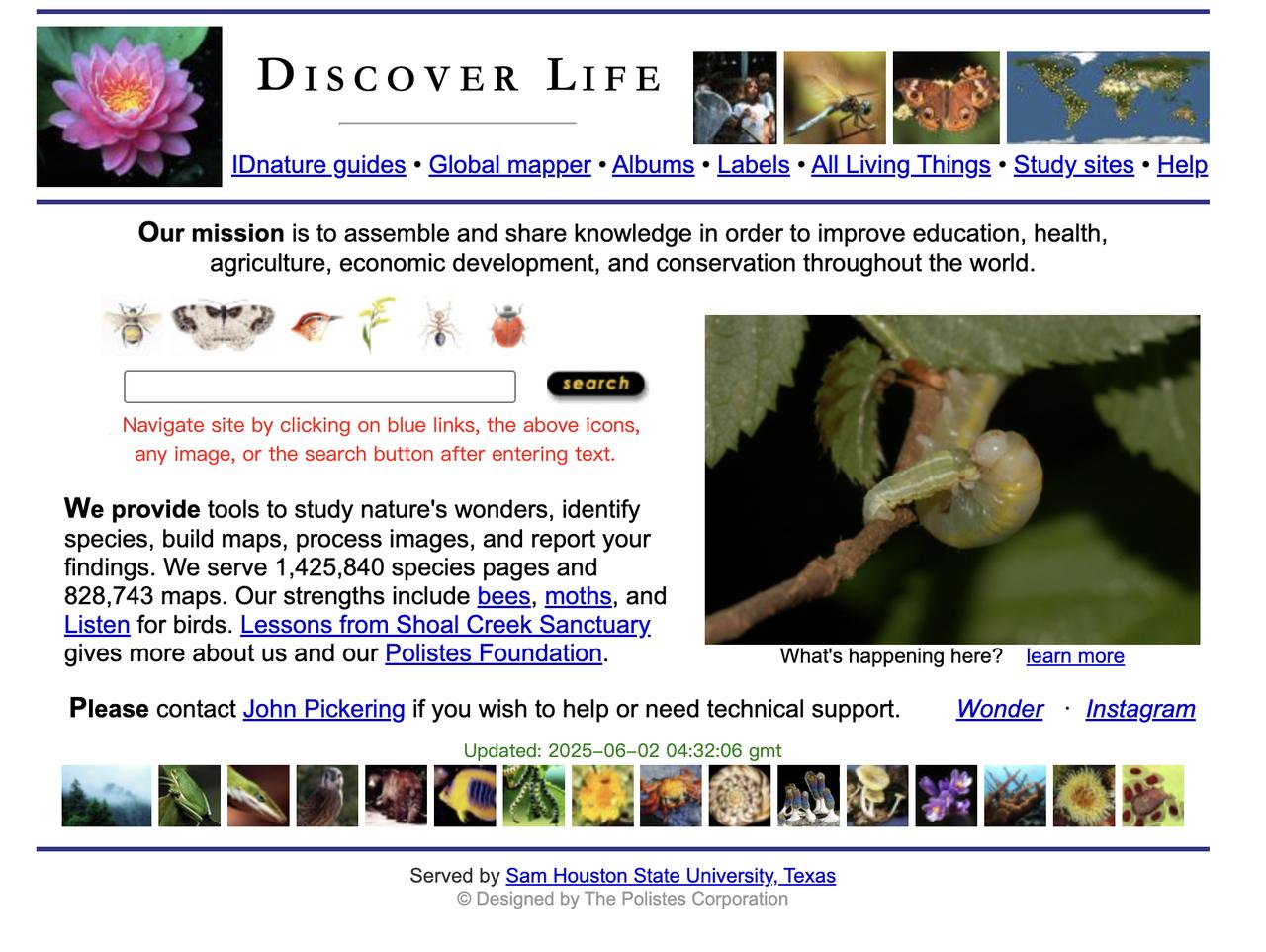
为了训练大模型,恶意爬虫挤爆了各类科学数据库? 今年2月,收藏了近300万张不同物种图片的在线图像库DiscoverLife的日点击数量开始飙增至数百万次。【图1】 罪魁祸首很明显:恶意爬虫。 随着AI的崛起,此类恶意爬虫的数量激增,从网站上“抓取”大量内容,很多网站管理者怀疑: 它们正在为训练聊天机器人和图像生成器等AI工具收集数据。 这种猜测有其背后的原因:以前大家觉得训练大模型需要庞大的计算能力,但现在发现,用少量资源也能开发出很厉害的AI工具。 这个突破直接导致了大规模的数据抓取热潮,大量爬虫开始疯狂搜集模型所需的训练数据。 其中,学术网站成了主要目标,因为它们的内容对AI开发者来说非常有价值。 旧金山网络服务商Cloudflare的副总裁Will Allen指出,只要内容新颖或高度相关,AI开发者就会非常感兴趣。 开放获取资源联盟(COAR)的一份报告显示,在他们调查的66家机构中,超过90%的网站都曾被恶意爬虫抓取内容,其中大约三分之二因此导致服务中断。 学术网站的运营者正在寻找技术解决方案,但目前很难在限制恶意爬虫的同时不影响正常用户。 当前主流的反爬虫措施是在网站代码中集成协议文件,告诉爬虫哪些内容可以抓取。但恶意爬虫会直接无视这些规则。 另一种方法是全面禁止这类爬虫行为,但这很容易误伤正常用户。 比如,学者们常常通过图书馆的代理服务器访问期刊,导致多个请求来自同一个IP地址,这很容易被误判为爬虫。 网站也可以针对性地封禁特定爬虫,但这需要先明辨爬虫“善恶”。 目前,Cloudflare等机构正在建立爬虫分类清单,但也有专家指出,很多新型爬虫身份隐匿,很难分辨它们的意图。 尽管现有反爬工具有多种,但爬虫持续进化,当前措施仍无法完全阻止非法抓取。 “我们真正需要的是关于AI合理使用这类资源的国际公约,否则长此以往,这些AI工具终将无优质数据可训练。”德国斯图加特州立国家历史博物馆的动物学家Orr表示。