Mixture-of-Experts(MoE)正在驱动R1、K2、Qwen3等前沿大模型,Tilde开源了MoMoE——一款高性能MoE训练与推理实现,显著超越现有最快方案:
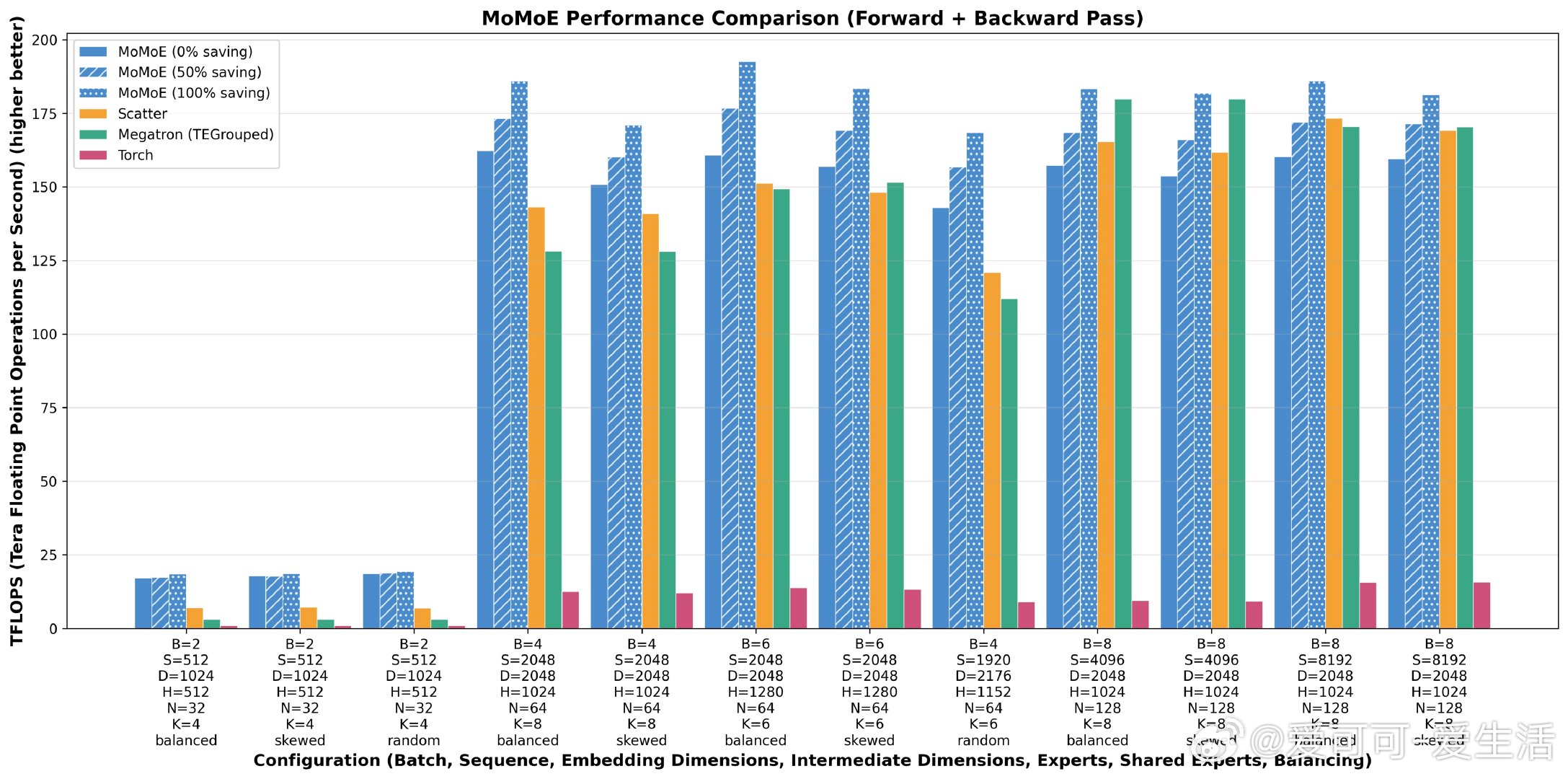
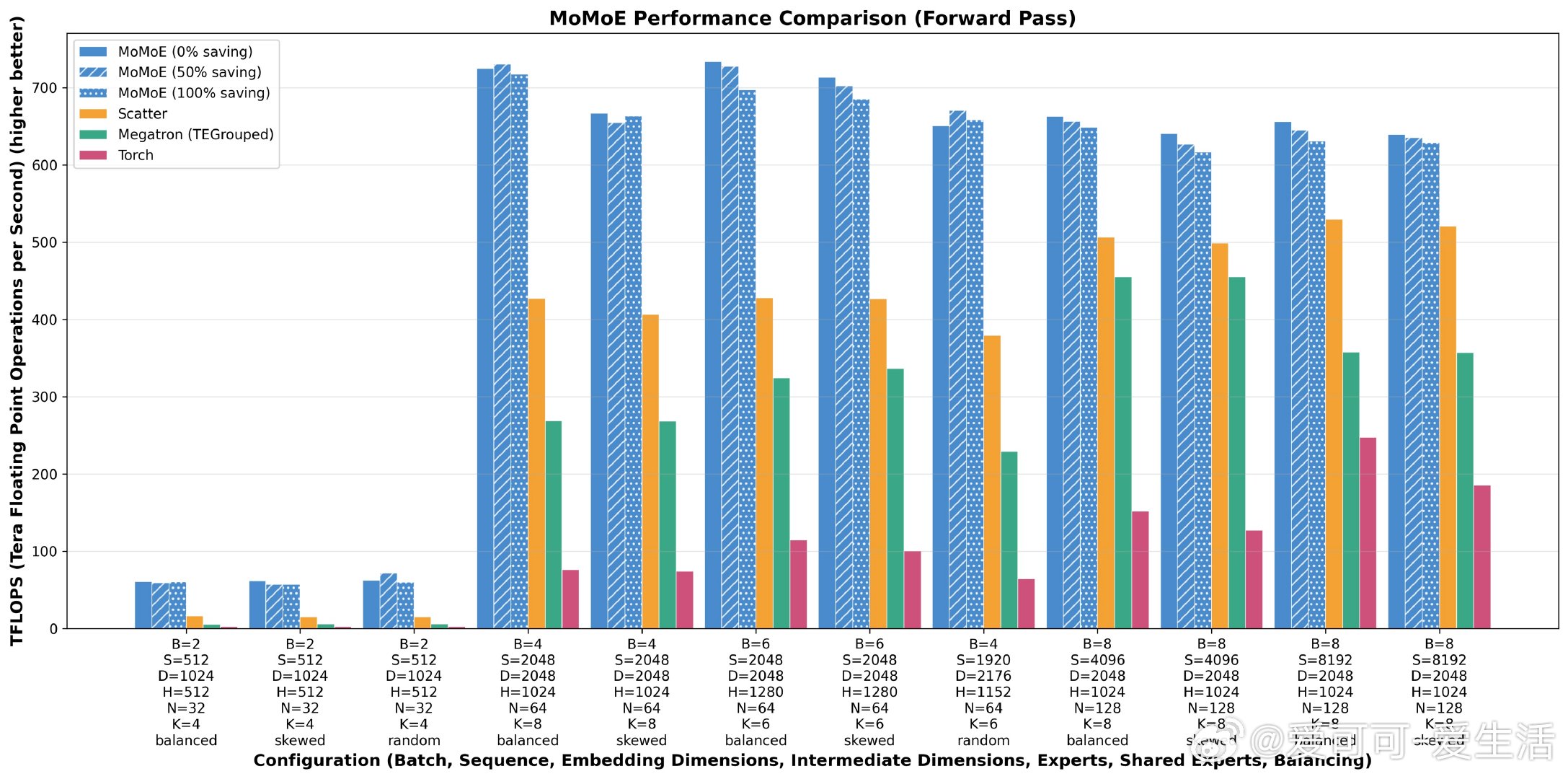
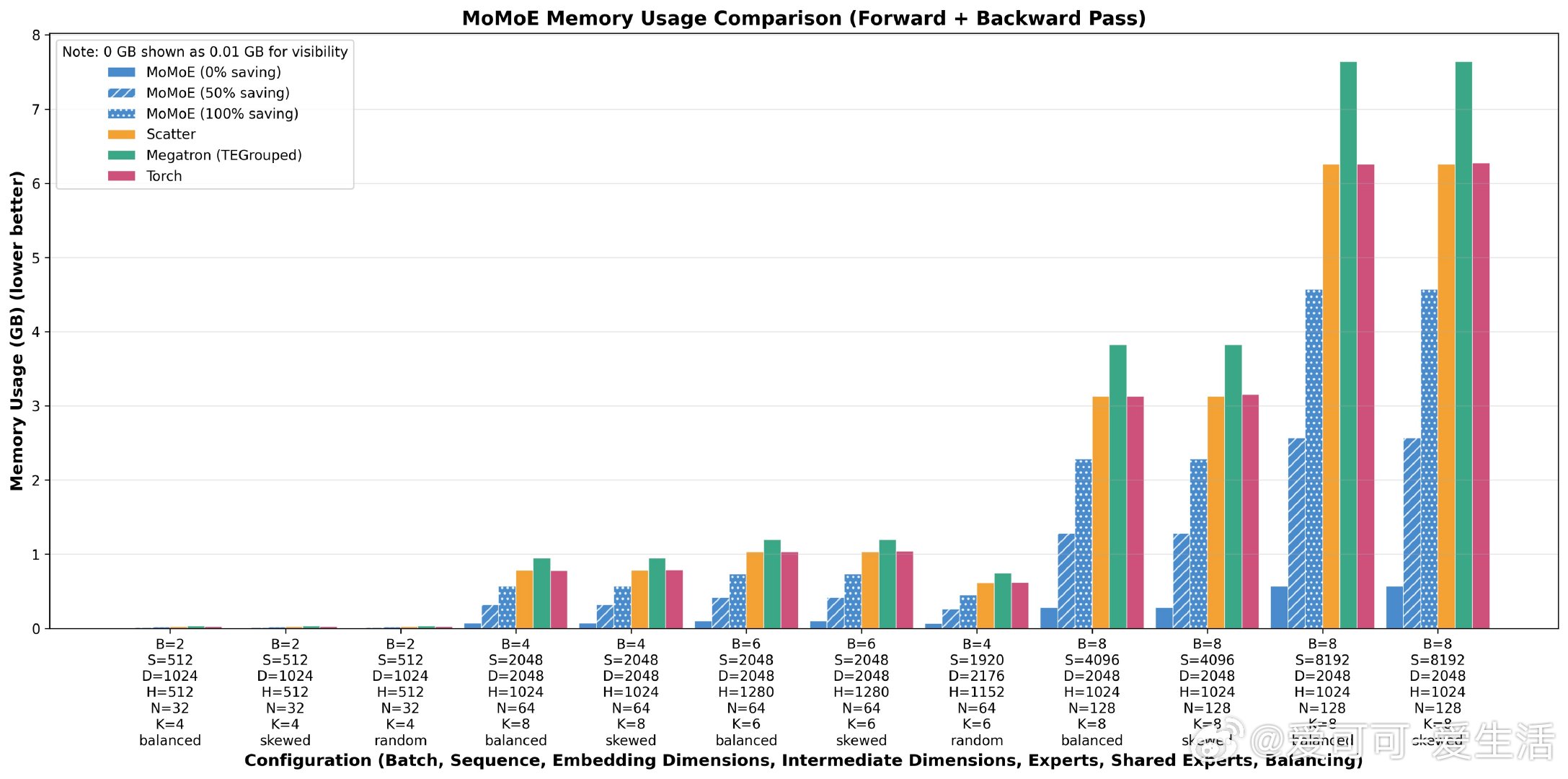
• 推理吞吐提升70%,训练吞吐提升20%,内存使用降低90%及以上
• 解决传统开源MoE内核因Python控制流、token批处理低效、内存访问不优等瓶颈
• 采用双核前向实现:融合gather、投影、SwiGLU,及高效BF16散射+归约求和
• 反向传播支持灵活配置,首次实现生产级分段重计算,平衡训练速度与内存消耗
• 数值精度与PyTorch基线一致,FLOP等价预训练表现优于等量密集模型
• 开放源码,推动MoE社区研究与应用创新,算法与硬件深度协同设计典范
MoMoE代表了大规模MoE模型训练推理的性能与效率新标杆,具备长期研究和工业应用价值。
🔗 github.com/tilde-research/MoMoE-impl/tree/main
MixtureOfExperts 大模型 深度学习 开源 AI训练 模型推理