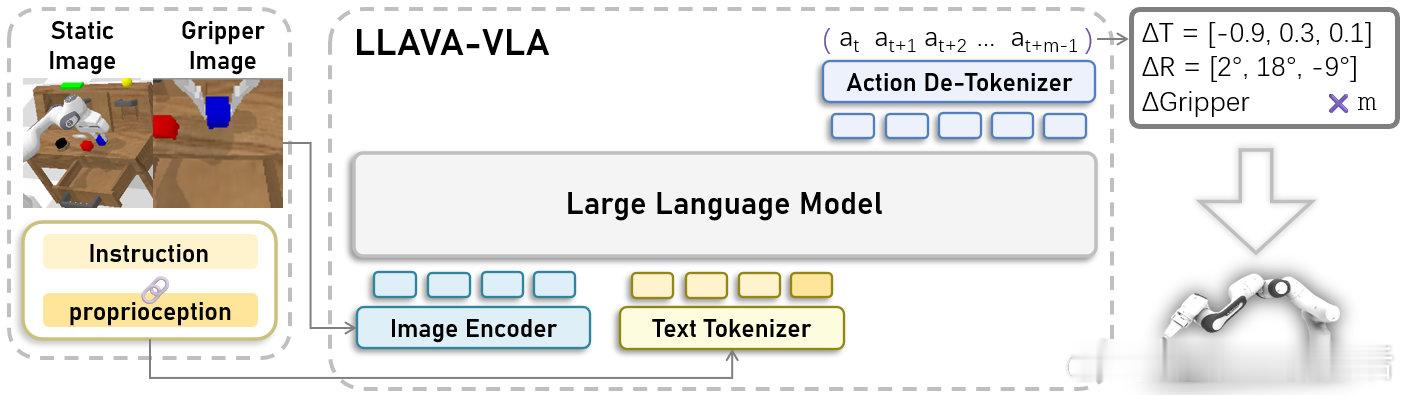
LLaVA-VLA:简洁高效的开源视觉-语言-动作模型,助力机器人操作与具身智能研究。
• 🏗️ 极简架构:基于流行VLM LLaVA,摒弃复杂hack,设计直观易改,适合教育与科研基线。
• 🏆 性能领先:CALVIN基准平均成功步数3.68,超越OpenVLA等主流基线,无需大规模机器人预训练。
• 💸 高效训练:仅需7小时微调LLaVA-v1.5-7b,显著降低硬件和时间成本。
• 🔌 无缝扩展:依托LLaVA生态,方便技术移植和衍生项目开发。
• 📊 多视角融合:上下拼接第一人称与第三人称视角图像,兼顾全局与细节,提升操作精度。
• 🤖 动作分块:创新动作切片设计,增强规划能力与时间一致性。
• 🔄 持续维护:提供训练代码、模型库,已支持RoboTwin仿真部署及动作专家模块。
• 🚀 适配消费级GPU:推出0.5b轻量模型,兼容24G显存,推动普及应用。
通过简洁设计与多模态融合,LLaVA-VLA体现了高性能机器人视觉语言融合的可行路径,强调动作规划与动作-感知一体化的本质,具备长期研究和实践参考价值。
详见项目🔗 github.com/OpenHelix-Team/LLaVA-VLA
视觉语言模型 机器人操作 开源AI 具身智能 多模态学习 机器人学习