大规模语言模型(LLM)架构的演进正在迎来细节优化与效率革新,2024-2025年多款旗舰模型虽基于类似Transformer骨架,却在关键设计细节上各显神通。深度剖析这些架构,揭示了未来AI模型的本质趋势与方法论价值。
• DeepSeek V3 / R1:
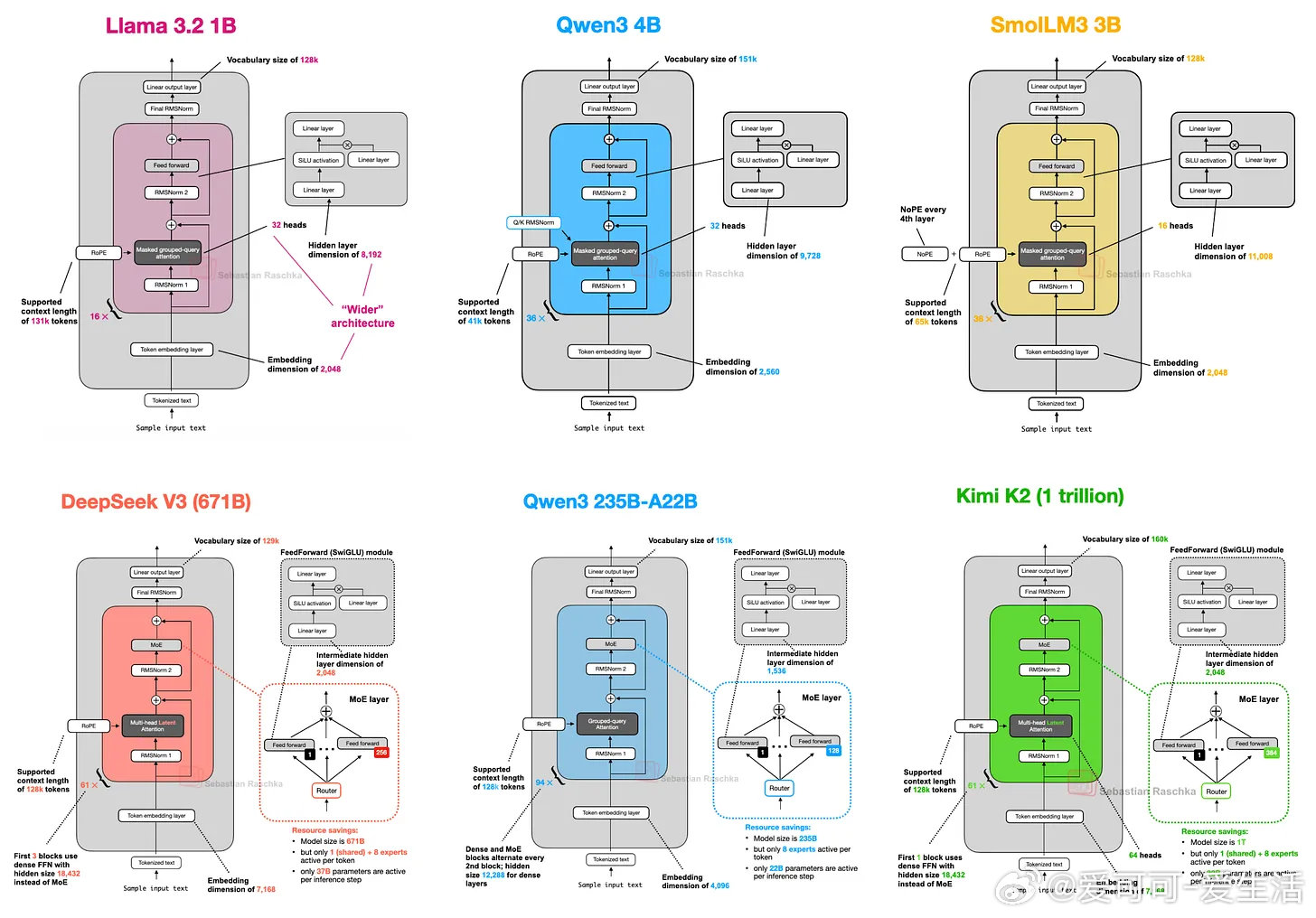
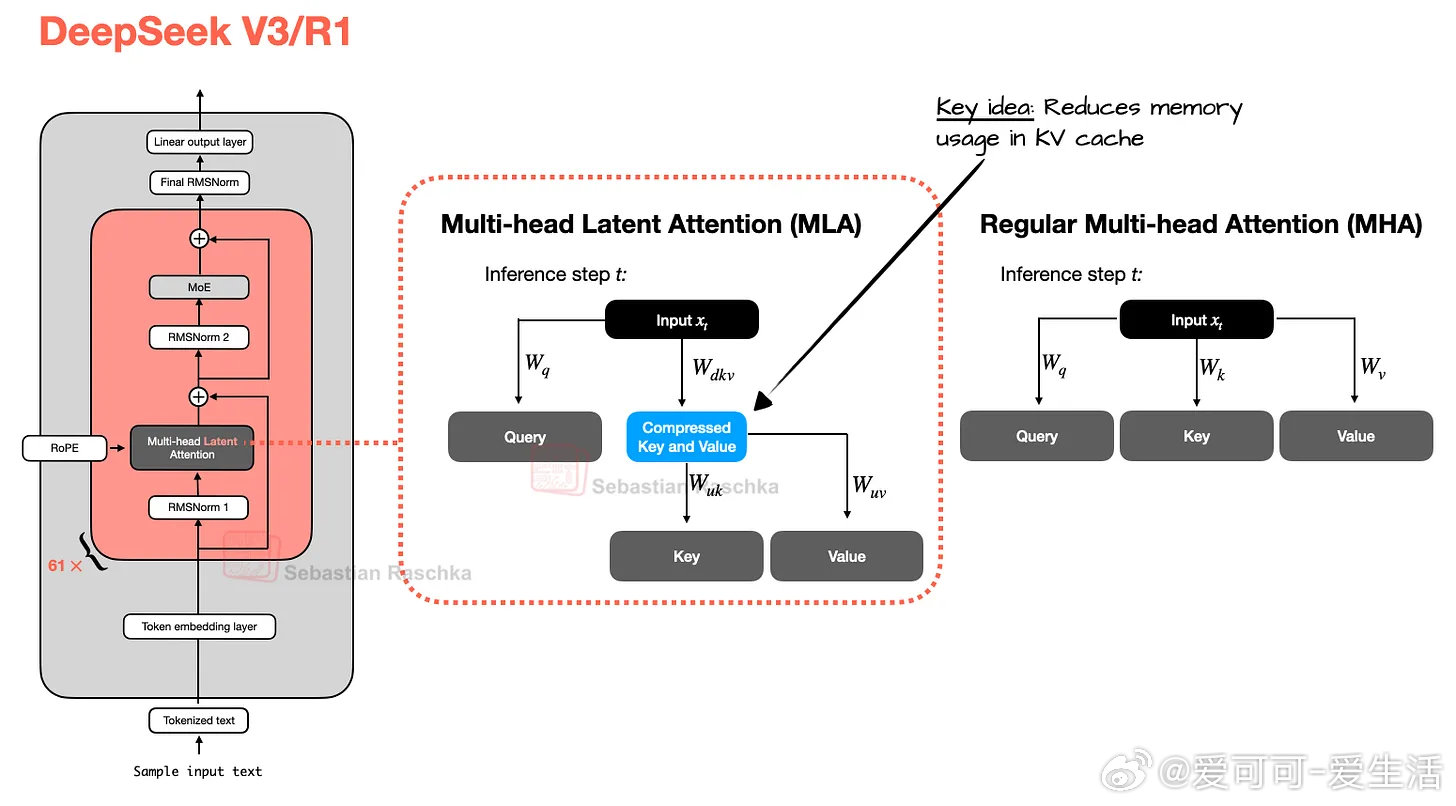
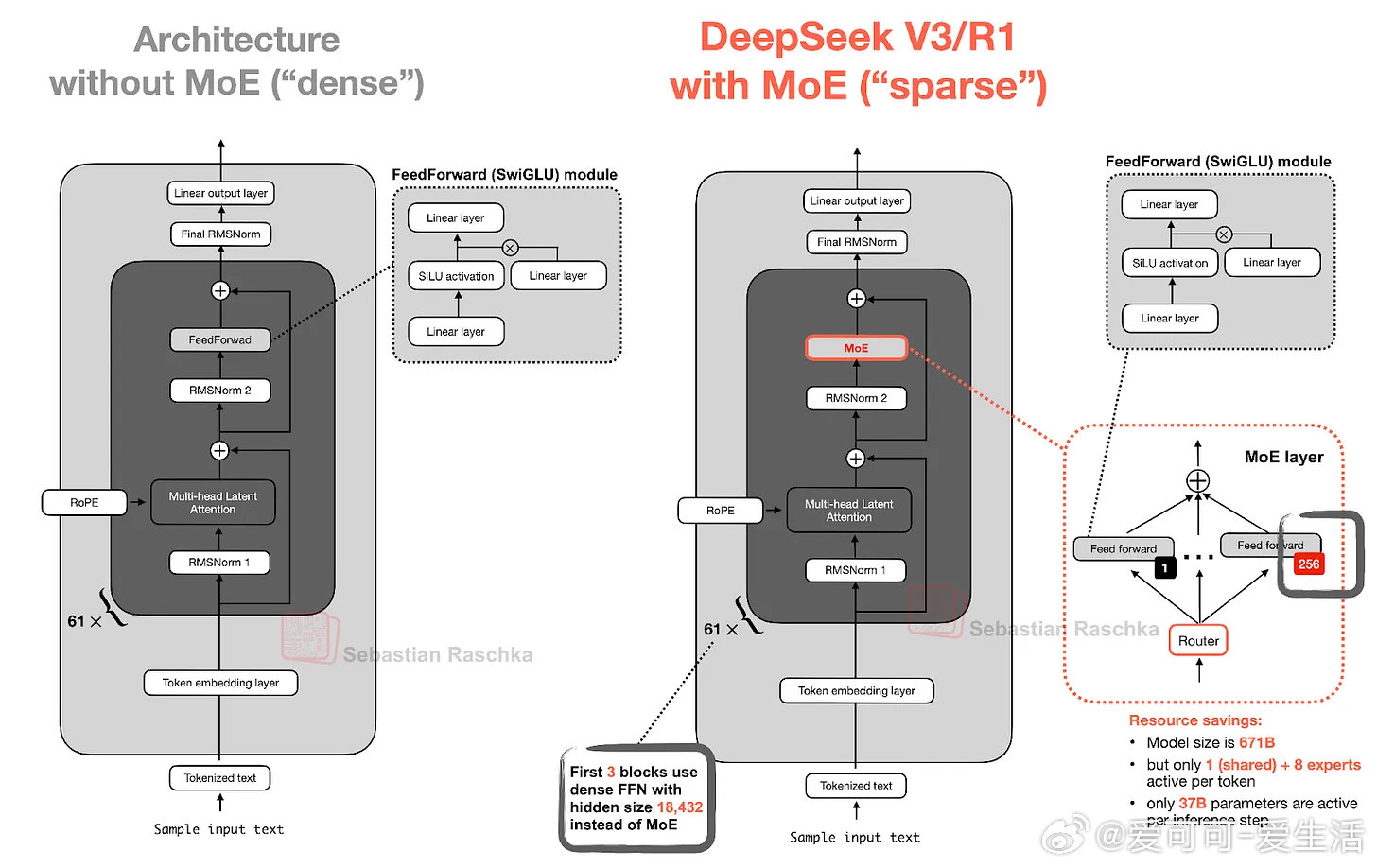
- 6710亿参数,采用多头潜在注意力(MLA)替代传统多头注意力(MHA),KV缓存压缩显著降低内存占用且提升性能。
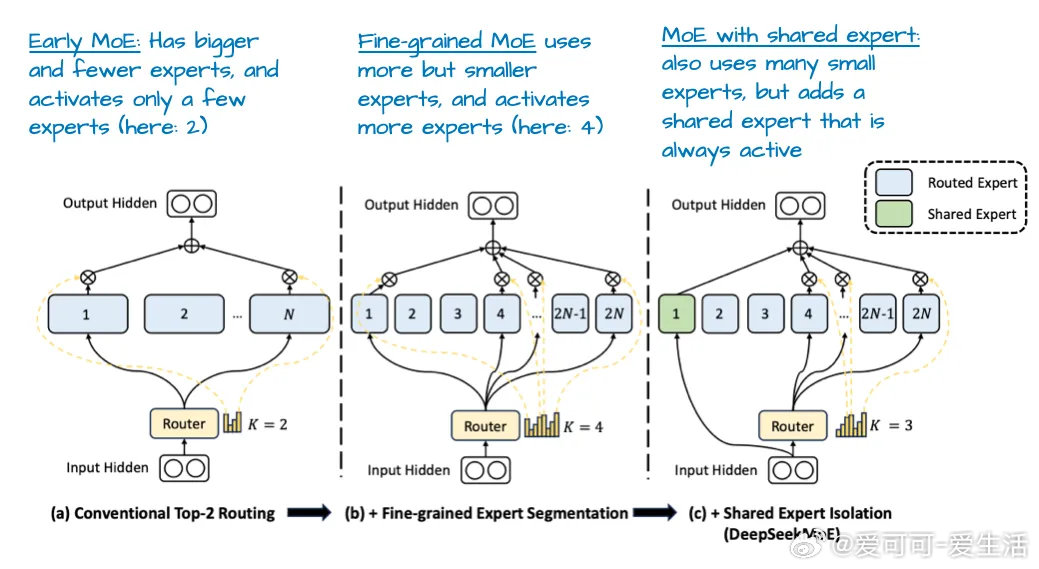
- 大规模专家混合(MoE)架构,256专家仅激活9个,推理时参数仅37B,兼顾容量与效率。
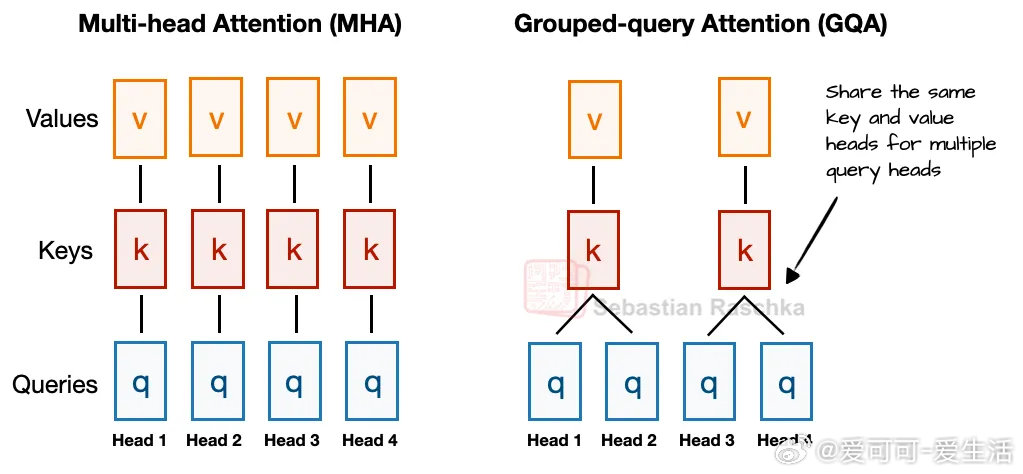
- MLA优于分组查询注意力(GQA),提升模型表现和推理效率。
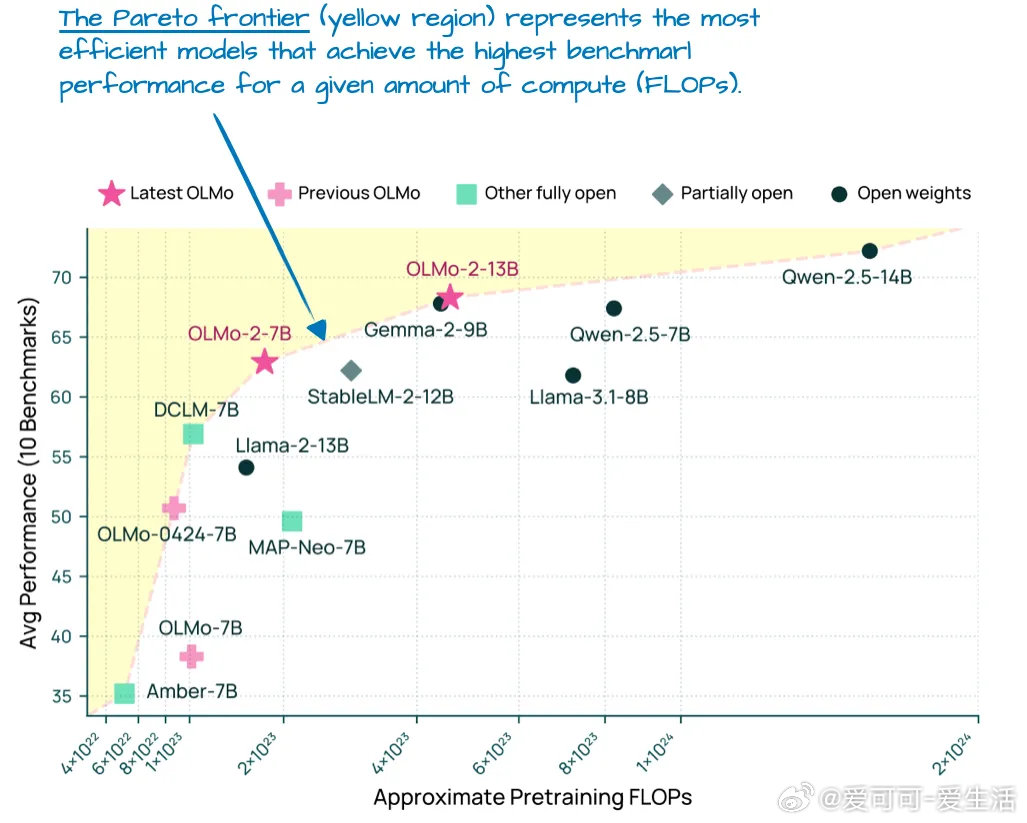
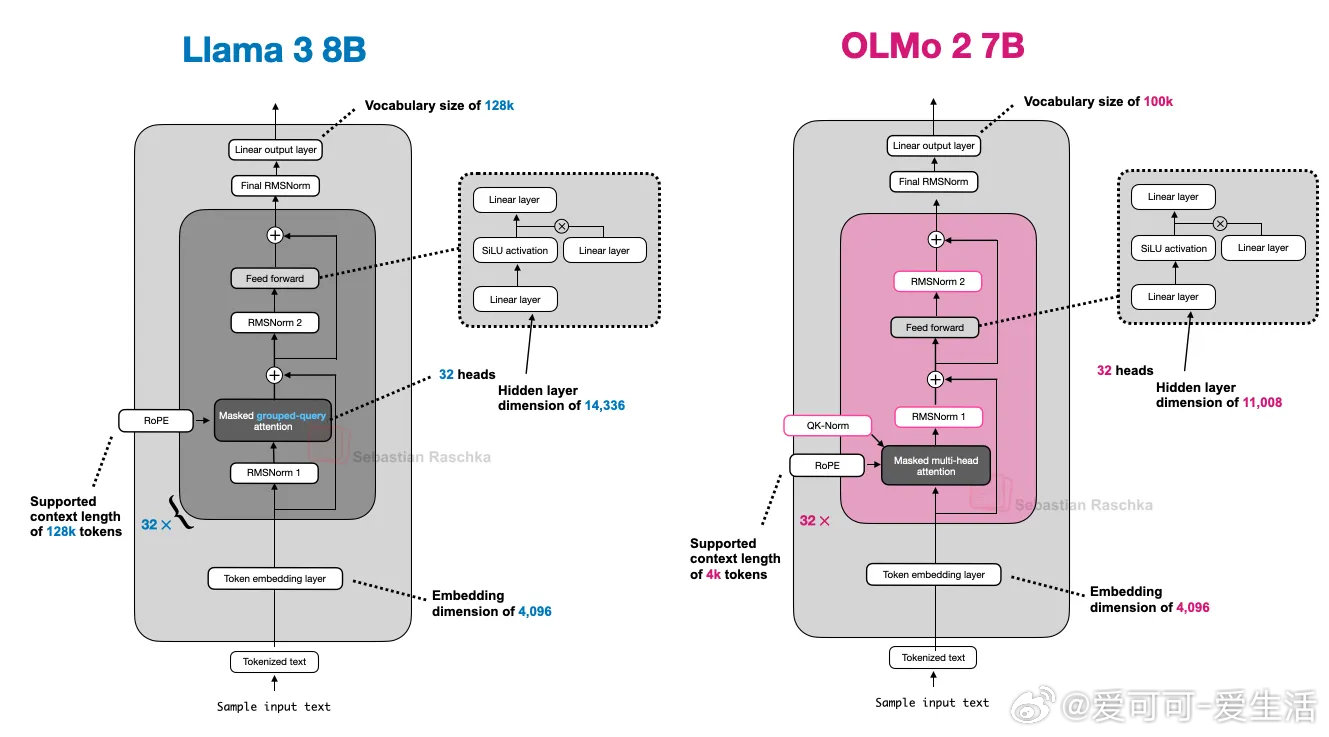
• OLMo 2:
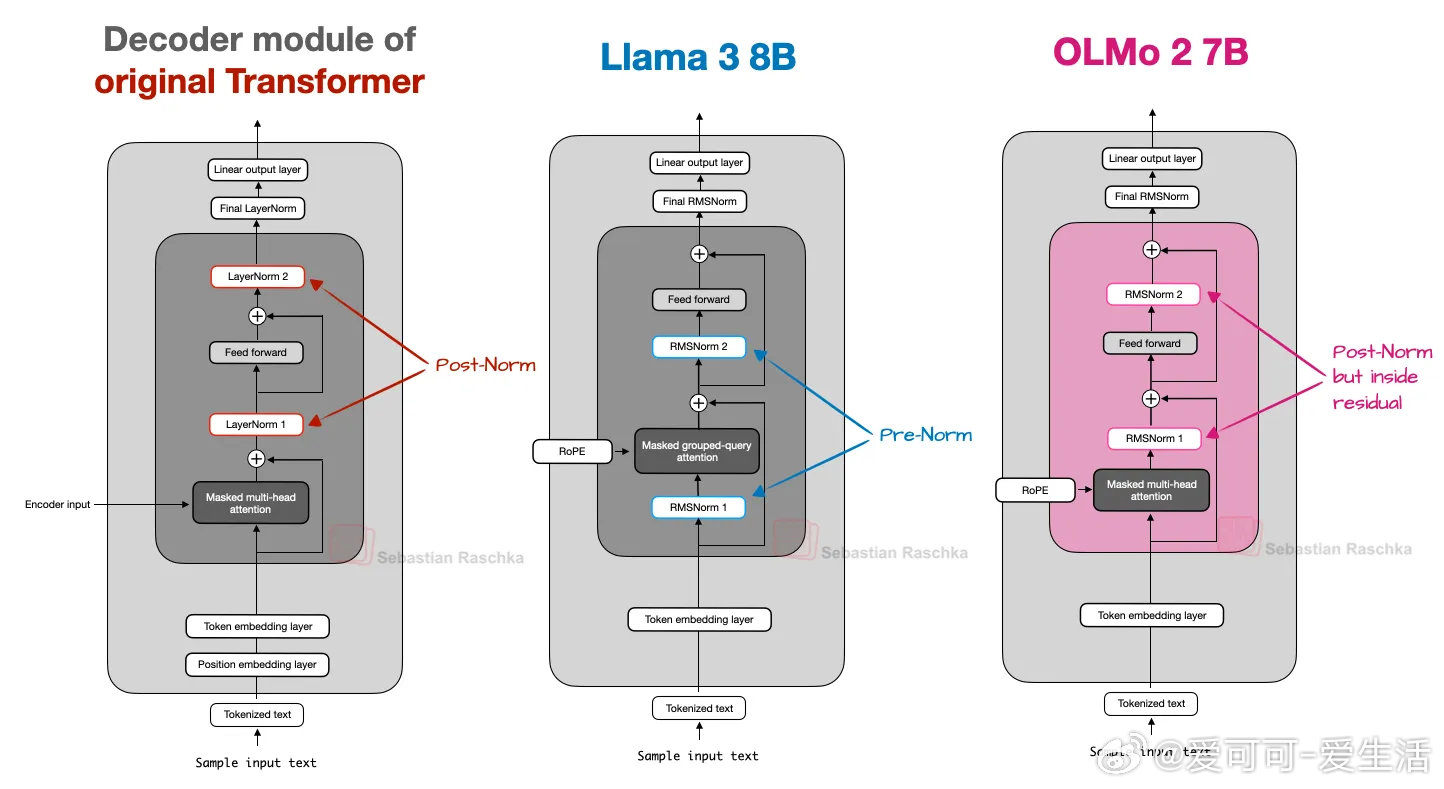
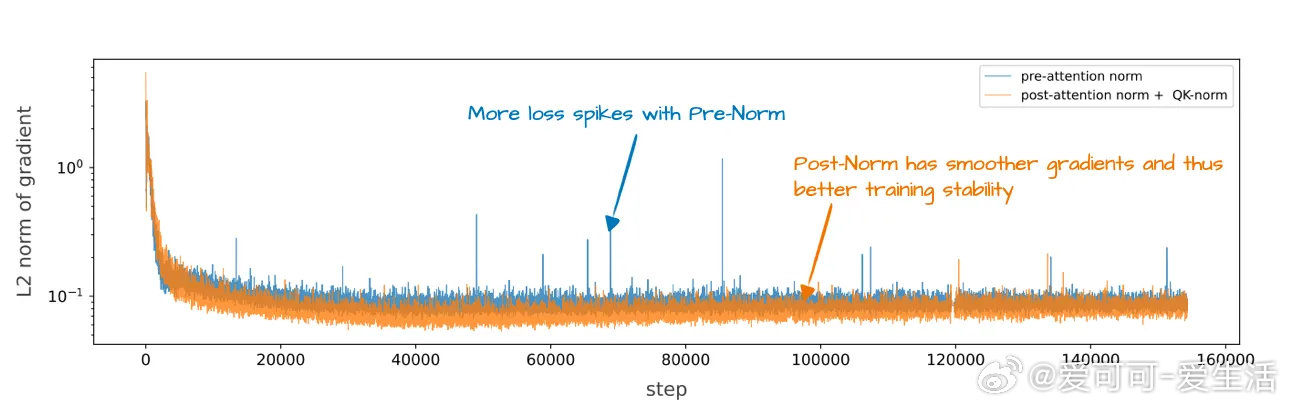
- 继承GPT核心架构,独特采用位置后置归一化(Post-Norm)及QK-Norm(对查询与键归一化),显著稳定训练过程。
- 保持传统多头注意力,透明开源,提供了极佳的LLM设计蓝本。
• Gemma 3(Google):
- 采用滑动窗口注意力减少KV缓存内存占用,局部注意力机制提升长序列处理效率。
- 独特归一化层布局,结合Pre-Norm和Post-Norm优势,提升模型稳定性。
- 27B规模实现本地运行友好与多语言支持平衡。
• Mistral Small 3.1:
- 24B参数,取消滑动窗口,选用更高效的Grouped-Query Attention,实现更低延迟推理。
• Llama 4:
- MoE架构异于DeepSeek V3,专家数量与激活策略不同,依旧沿用Grouped-Query Attention。
- 400B参数,活跃参数17B,体现不同专家层设计对模型表现与资源利用的权衡。
• Qwen3系列:
- 多尺寸密集模型与MoE模型并存,兼顾训练简便性与推理效率。
- MoE变体取消共享专家,优化推理开销,提供灵活多样的应用方案。
• SmolLM3:
- 3B参数小模型,采用无位置编码(NoPE)技术,提升长序列泛化能力。
- 性能优于部分同规模模型,适合资源有限环境。
• Kimi 2:
- 1万亿参数级巨型模型,基于DeepSeek V3架构放大,采用MuON优化器替代AdamW,训练损失曲线更平滑且收敛更快。
- 目前公开模型中参数规模最大,代表下一代超大规模LLM趋势。
洞察:当前大规模语言模型的设计趋向于“容量与效率并重”,通过稀疏专家(MoE)、高效注意力机制(MLA、滑动窗口)及归一化创新来突破算力瓶颈,同时保持训练稳定和模型泛化能力。架构层面的细节优化成为推动LLM性能提升的关键路径,反映了AI模型从粗放扩张向精细雕琢的转变。
探索完整架构对比与设计细节🔗 sebastianraschka.com/p/the-big-llm-architecture-comparison
大规模语言模型 深度学习 人工智能 Transformer MixtureOfExperts 模型效率 机器学习