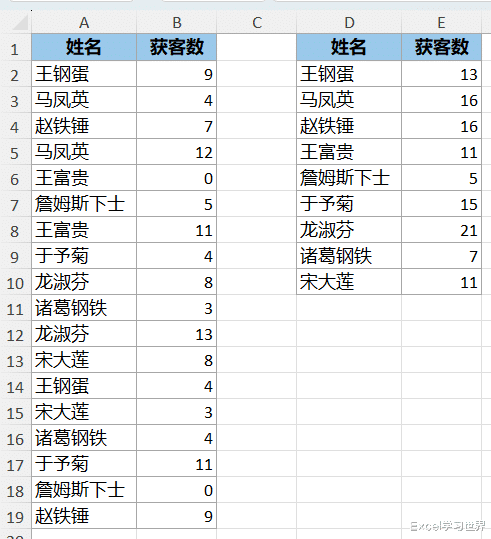
数据透视表的排序如何跟源数据保持一致?
案例:计算下图 1 中每个人的总获客数,姓名的排序需要跟源数据表的顺序一致。
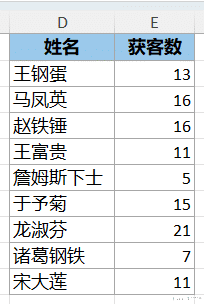
效果如下图 2 所示。
如果是透视求和的话,我们用 groupby 或 pivotby 函数都行。
1. 在 D2 单元格中输入以下公式 --> 回车:
=PIVOTBY(A2:A19,,B2:B19,SUM,,0)
公式释义:
A2:A19:行区域
B2:B19:值区域
SUM:要执行的计算
0:不显示总计

透视结果是按中文的拼音顺序自动排序了,并未遵循源数据的顺序。那么我们就需要把公式升级一下。

1. 将公式修改如下:
=DROP(PIVOTBY(HSTACK(MATCH(A2:A19,A2:A19,),A2:A19),,B2:B19,SUM,,0),,1)

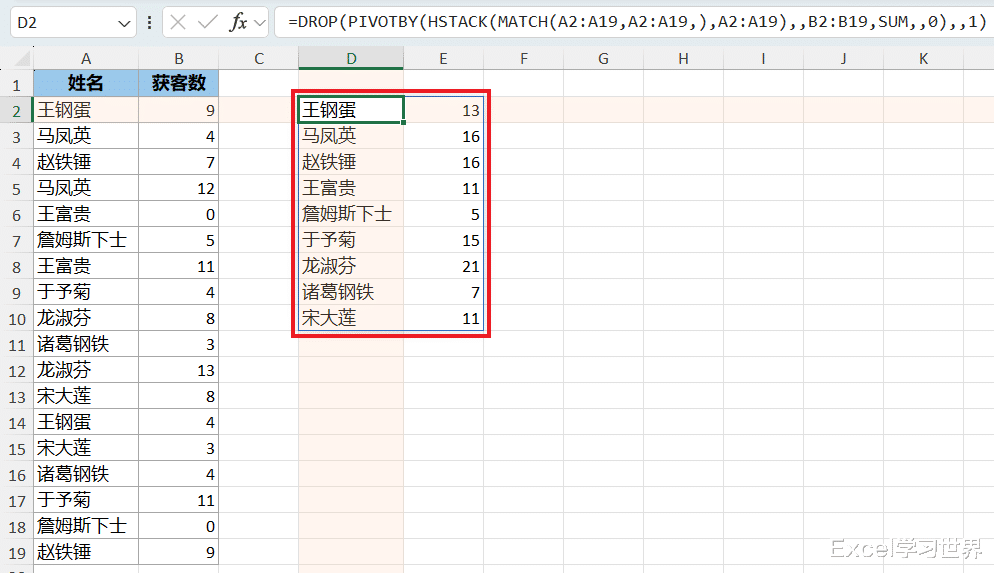
公式释义:
MATCH(A2:A19,A2:A19,):在整个区域中依次查找每个姓名,从而得到每个姓名第一次出现的位置所代表的数字;
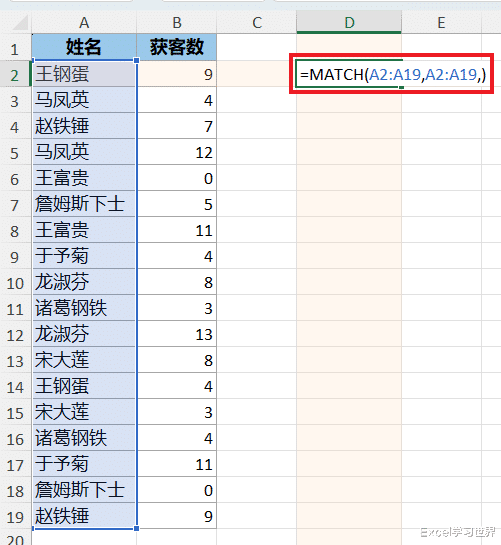
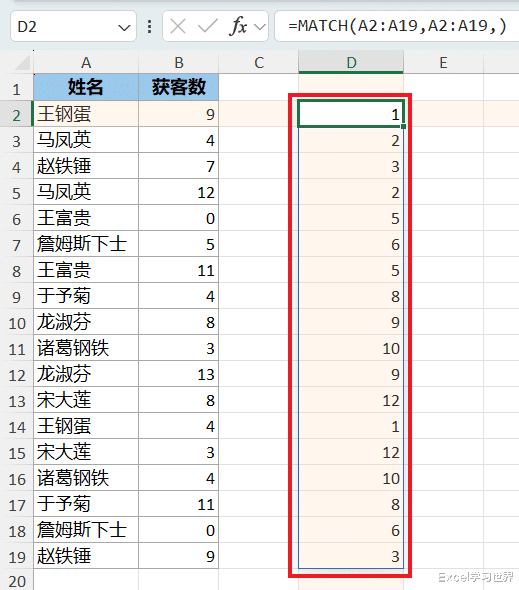
HSTACK(...,A2:A19):
hstack 函数的作用是按顺序水平追加数组,以返回更大的数组;
语法为 HSTACK(数组1,[数组2],...);
到此为止,相当于给 A 列的每个姓名增加了一列,统计每个姓名第一次出现的位置;
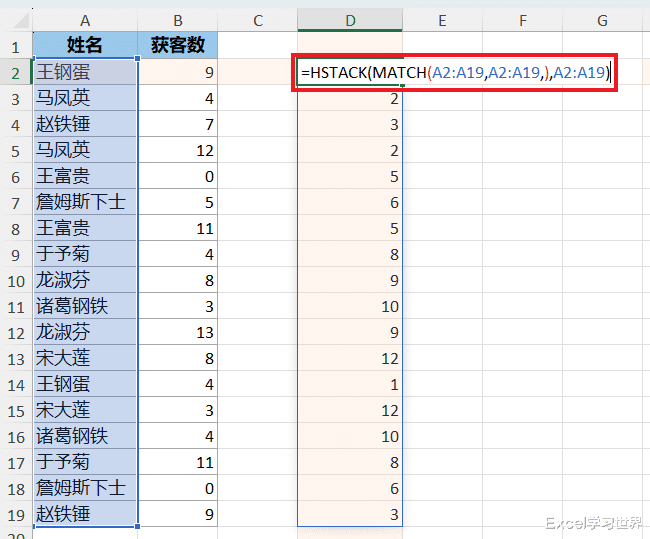

PIVOTBY(...,,B2:B19,SUM,,0):此时再套用 pivotby 函数,就会以 D 列的数值顺序排序了,也就是按源数据表中姓名出现的先后顺序排序;

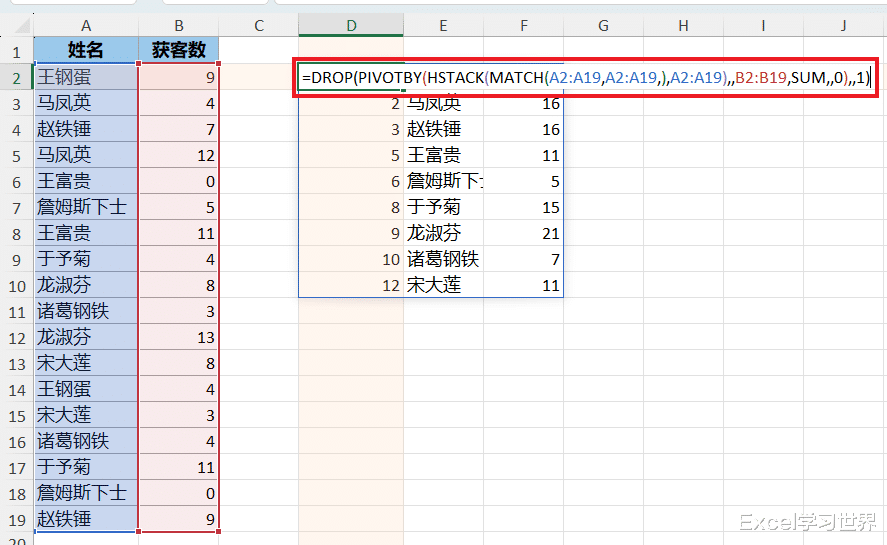
DROP(...,,1):最后再用 drop 函数去除第一列,得到最终结果;
2. 添加标题,用格式刷复制格式。