从古埃及等全球文字看中文的优越性:唯一还在常规应用的非字母化文字(1)
近期学习古埃及文字,也看了世界上不少文字。以前就接触过很多文字,有个疑问,为什么中文如此特殊?本文结合计算机编码,介绍全球各种文字,有不少技术细节。
因为有大模型方便学习,最近领悟了:中文是唯一还在活跃使用的,没有任何字母化的文字体系!
传统彝文也是非字母化的。如“ꁧꊿꋍꄔ, ꃅꉈꋍꄔ,ꃅꊿꄚꃴ, ꀋꆏꀋꄔ。ꊰꇭꃅꂷ, ꐈꁧꃅꂷ,ꁮꐚꊿꐚ, ꃅꄔꊿꄔ。ꊰꏦꀕꄔ, ꀋꐚꀋꇁ!”(男女一对,天地一双;天配地合,永不分散。百年好合,早生贵子,富贵人丁,天地同长。百年今日,永不散场!)
东巴文也是一字一义非字母化的。如“𐰀𐰁𐰂 𐰃𐰄𐰅 𐰆𐰇𐰈 𐰉𐰊𐰋 𐰌𐰍𐰎”(愿流水长清,星光常明,家屋安稳,福泽满门!),可以感觉到,东巴文字符比较简单,比彝文简单。东巴文大约有700多个字素,彝文进入计算机规范编码的有1100多个,各地还用的有上万个。
壮语文字也是非字母化的。如“見𭕆倿㖃旱? 倿㖃壯! 𬻀𬻀倿腎𰯨!”(你好吗老弟?老弟真棒!多吃点老弟,保重!),可以看出壮语文字就是借汉字加上自造出来。壮语文字正体字有4900多个,加上变形的约1万个。
越南喃字也是非字母化的。如“𣎏𤆵𫡘酟,當㨳𢷣𠊛些!”(杯中有美酒,抓紧身边人,干杯!)。喃字类似壮语,也是借用汉字加自造的,有些和壮语完全相同。但由于和壮语发音差异较大,所以算是用同一个思路造出的不同文字。
上面介绍的非字母文字,除了汉语都太小众了 。虽然还有人用,但意义不大了,只是文化遗存展示,没可能发展了。
要注意,汉语、壮语都搞了拼音化运动。东巴文有注音,但不是拼音化;彝文搞了好几次拼音化都失败了。壮语的拼音化只是学术性的,几乎没有使用。汉语的拼音化,变成了注音。汉语只看拼音有时会有理解困难,较少单独使用。虽然汉语拼音很常用,但不是字母化。
越南官方文字就字母化了,直接用拉丁文来表示,是法国传教士、殖民者从17世纪开始干的。后来经过百多年政治变迁,官方称为“国语字”,在20世纪下半叶清除了汉字和喃字。有些越南拉丁字符加了注音,是独特的字母,但在计算机编码中算是“扩展拉丁字符”,不是单独的越南字符。越南文字在计算机编码中共有196个。如“Chào bạn, bạn khỏe không? Mình khỏe, cảm ơn bạn nhiều lắm!”(你好,你好吗?我很好,非常感谢你!),看上去就是英文字符,元音上加了多种声调。
韩文看上去类似汉字,在计算机里编码占了上万个。但其实是辅音字母“ㄱ、ㄴ、ㄷ、ㄹ、ㅁ、ㅂ、ㅅ、ㅇ、ㅈ、ㅊ、ㅋ、ㅌ、ㅍ、ㅎ”等等和元音字母“ㅏ、ㅑ、ㅓ、ㅕ、ㅗ、ㅛ、ㅜ、ㅠ、ㅡ、ㅣ”组成。但不是线性排列,而是象汉字一样结构排列,因此象是汉字,其实完全字母化了。例如“韩国”就是한국 = ㅎ+ㅏ+ㄴ + ㄱ+ㅜ+ㄱ,发音是han+guk。
1443年朝鲜世宗大王主持自主创制了字母化文字方案,不是殖民者搞的,有一定的特色,韩国很自豪。韩国试图向国外推广这个拼音化方案,如记载中国境内濒危语言(如赫哲语、嘉戎语)、印尼旅游小岛的“用韩字母教当地方言”的短期志愿项目、联合国教科文组织和一些高校开展“韩字母记录濒危语言”工作坊。但只有学术性活动,没有官方任何进展。
日文应该是世界上最混合的文字体系,也可以说是最接近汉字的常见文字体系。日文的基础是大量汉字(有简写、自造),发音基本不同,但借来当“语素”。但日文中混杂了大量平假名、片假名、罗马字符(拉丁字符)。如“今日のLUNCHは、SUSHIをテイクアウトして、公園で食べることにした!天気も最高だし、ちょっとしたピクニック気分!”看上去非常地“混合”。
平假名是汉字草书所化,曲线、圆润;片假名是汉字楷书所化,直线、棱角分明。这些其实是注音符号,各有104个(清音 46 + 浊音 20 + 半浊音 5 + 拗音 33)。片假名只占10%表示外来语的发音;平假名占90%,是用来快速书写替代汉字,等于顺着发音写容易,写多了就习惯了。日本人也有可能只用汉字互相对话、与中国人文字对话,但发音和中国人完全不同。
严格来说,日语没有字母化,而是汉字+音节文字。等于中文汉字与拼音混写,拼音用自造的字符。但由于音节文字大量出现,可以认为是不小的字母化倾向。
这是东亚的特殊情况,除了汉字体系保持纯正没有任何字母化,其它都完全字母化、部分字母化了。至于东亚之外的其它地区,现在全部字母化了,但字符种类有非常多种。
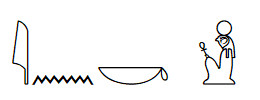
其它地区在文明早期阶段,也有一些非字母化的文字体系,但都消亡了。如苏美尔楔形文字(图)、古埃及圣书体/僧侣体/世俗体、印度河流域的哈拉帕文字、克里特岛线形文字、赫梯象形文字、玛雅象形文字。楔形文字、古埃及文字在消亡之前,就已经字母化了。
所以,现在汉字是全球唯一的非字母化文字。就是这么牛!后面分析文字形体的文化与思维影响。(待续)






![原来不会写汉字吗,那问题来了她是怎么看剧本的[思考]](http://image.uczzd.cn/594263305349332891.jpg?id=0)
