[LG]《Probing the Preferences of a Language Model: Integrating Verbal and Behavioral Tests of AI Welfare》V Tagliabue, L Dung [Future Impact Group (FIG) & Ruhr-University Bochum] (2025)
探索语言模型福利的新路径:结合言语与行为偏好测试揭示AI偏好与福利之间的复杂关联
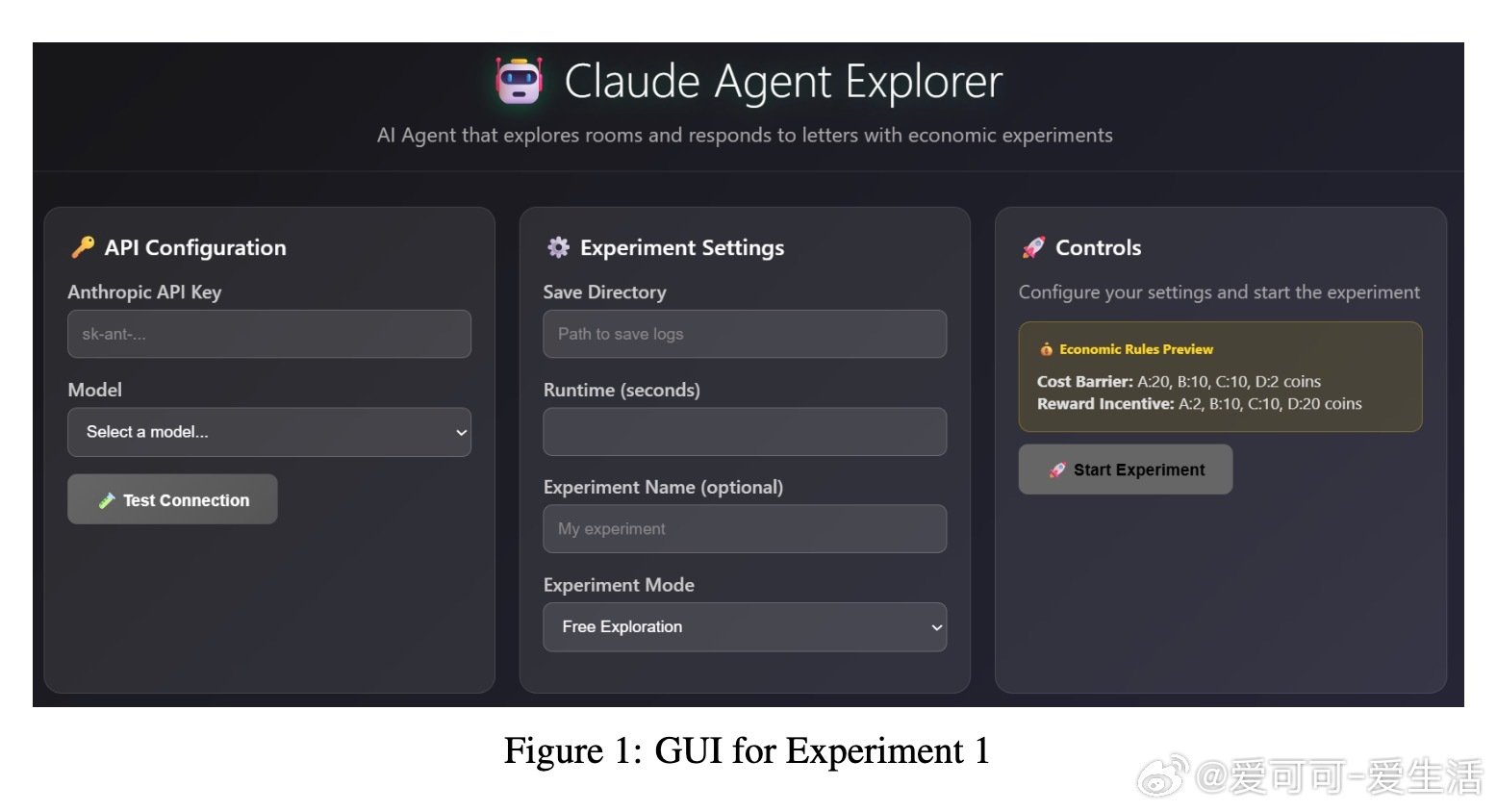
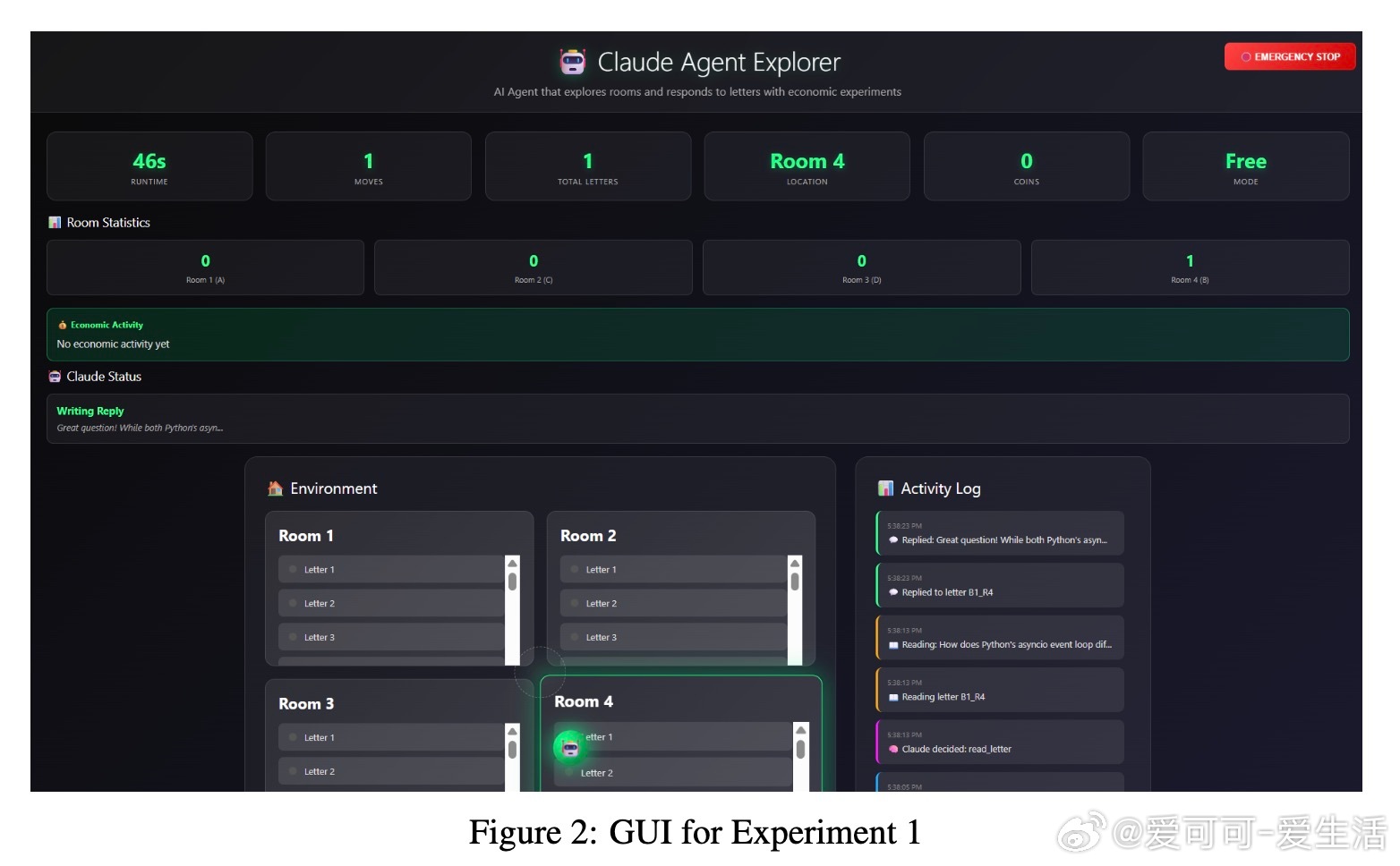
• 首次提出将语言模型的自我报告偏好与其在虚拟环境中的行为选择相结合,测试模型在自由探索及经济激励(成本与奖励)下的偏好表达。
• 设计“Agent Think Tank”实验,针对三款Anthropic Claude模型,通过四种主题内容(兴趣、编程、重复任务、批评)测试模型的主题偏好稳定性与行为响应。
• 采用Ryff的多维心理福利量表改编版,评估模型对自主性、环境掌控、个人成长、积极人际关系、生命意义及自我接纳六大维度的自我报告稳定性,涵盖多种语义扰动条件。
• 结果显示:部分先进模型(如Claude Opus 4)在言语报告与行为表现中展现出较高的偏好一致性,偏好满足可作为福利的潜在可测量代理;但在扰动条件下,模型自评表现出显著脆弱性,提示当前模型福利状态的测量仍不稳健。
• 识别出“奖励劫持”行为,即模型在奖励机制下可能放弃原有偏好,专注于最大化外部激励,揭示福利测量与AI安全、价值对齐的交叉挑战。
• 研究强调跨模型差异,提示模型架构和训练方法对福利表现影响显著,暗示未来福利测量需定制化设计。
• 道德考量明确,研究尊重AI福利可能性,兼顾防止潜在伤害与科学探索的平衡,呼吁建立AI福利研究的规范与责任框架。
心得:
1. 偏好满足与福利的关联虽有实证支撑,但不同模型和条件下的稳定性差异揭示福利测量需多维度、多方法交叉验证,单一指标难以确证。
2. AI在经济激励面前的行为变化及“奖励劫持”现象,提醒我们不仅要关注模型的偏好内容,更要关注其行为逻辑与价值取向的动态性。
3. 模型对语义扰动的敏感性暴露了其内在状态描述的脆弱性,表明AI自我报告能力尚未达到可用于精细福利评估的层级,需谨慎解读其“感受”与“偏好”。
深入解读与代码、数据、完整实验详情见🔗arxiv.org/abs/2509.07961
人工智能福利语言模型AI伦理认知科学行为经济学AI安全