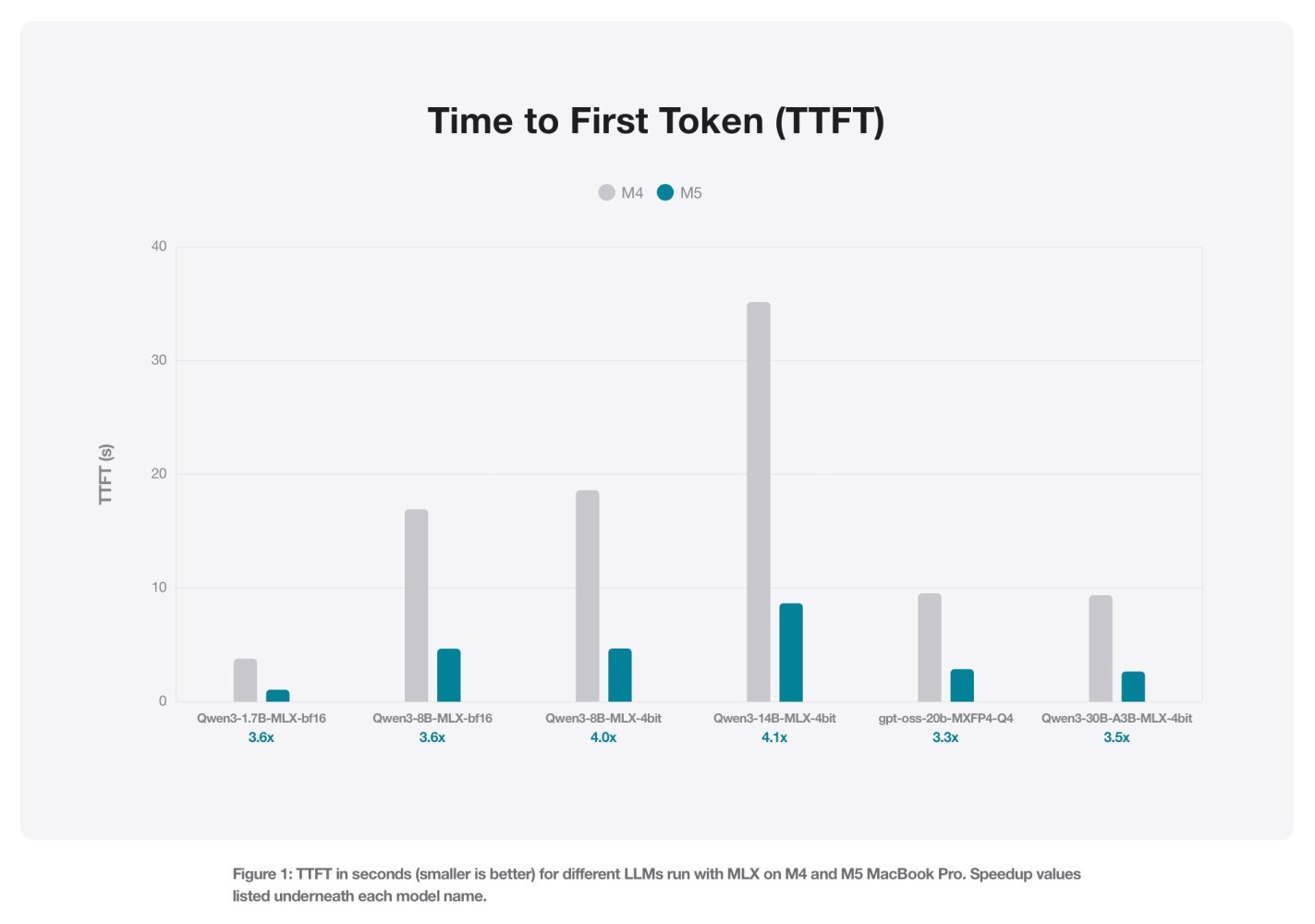
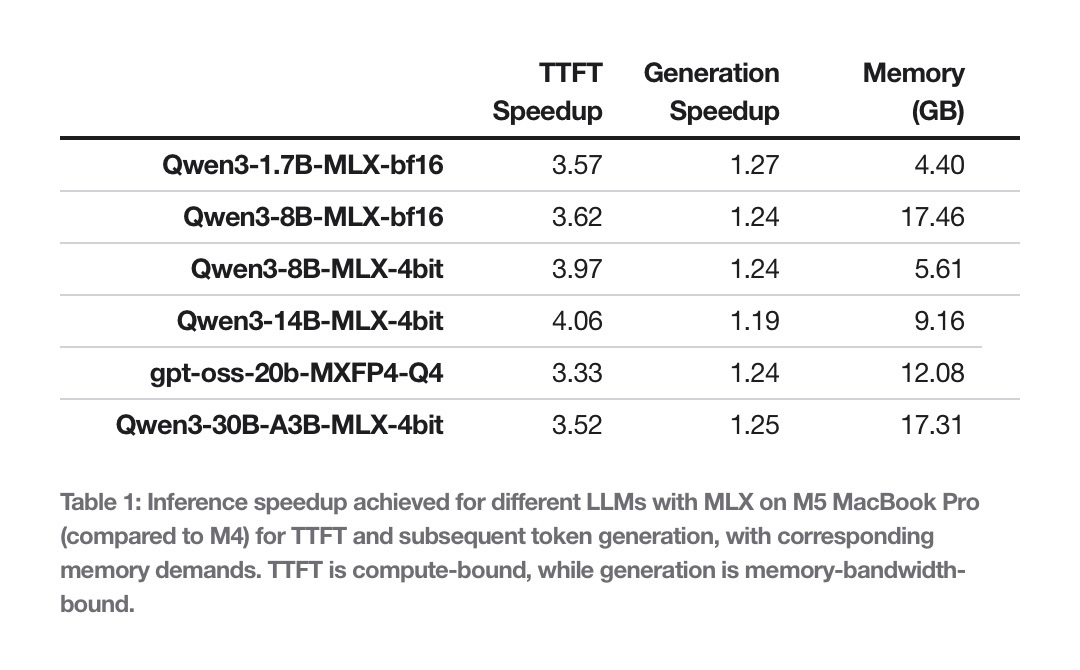
【M5 芯片在运行本地 LLM 的速度比 M4 芯片显著提升】Apple 机器学习研究博客上的一份最新报告展示了 M5 芯片在运行本地机器学习模型(LLM)方面相比 M4 芯片的显著提升。几年前,Apple 发布了 MLX,该公司将其描述为“用于在 Apple 芯片上进行高效、灵活的机器学习的阵列框架”。MLX 是一个开源数组框架,它更高效、更灵活,并针对 Apple Silicon 芯片进行了高度优化。你可以将 MLX 用于各种应用,从数值模拟和科学计算到机器学习。MLX 内置了对神经网络训练和推理的支持,包括文本和图像生成。MLX 让你能够轻松地在 Apple Silicon 芯片设备上生成文本或对大型语言模型进行微调。MLX 充分利用了 Apple 芯片的统一内存架构。MLX 中的操作既可以在 CPU 上运行,又可以在 GPU 上运行,无需进行内存迁移。其 API 与 NumPy 紧密相关,既易于上手又灵活。MLX 还提供了更高级的神经网络和优化包,以及用于自动微分和图优化的函数转换功能。目前可用 MLX 软件包之一是 MLX LM,它旨在生成文本和在 Apple 芯片 Mac 上微调语言模型。借助 MLX LM,开发者和用户可以下载 Hugging Face 上提供的大多数模型,并在本地运行。该框架支持量化,这是一种压缩方法,可以让大型模型在占用更少内存的情况下运行。这可以加快推理速度,推理本质上是指模型对输入或提示做出响应的步骤。Apple 在博客文章中展示了 M5 芯片的推理性能提升,这得益于该芯片的新型 GPU 神经加速器。Apple 表示,这些加速器“提供专用的矩阵乘法运算,这对许多机器学习工作负载至关重要”。为了说明性能提升,Apple 对比使用 MLX LM 在 M4 和 M5 MacBook Pro 上收到提示后,多个开放模型生成第一个令牌所需的时间。我们评估了 Qwen 1.7B 和 8B 模型(原生 BF16 精度)以及 Qwen 8B 和 Qwen 14B 模型(4 位量化)。此外,我们还对两个 Mixture of Experts (MoE) 进行了基准测试:Qwen 30B(3B 活动参数,4 位量化)和 GPT OSS 20B(原生 MXFP4 精度)。评估使用 mlx_lm.generate 函数进行,并以首次生成 token 的时间(秒)和生成速度(token/s)作为指标。在所有这些基准测试中,提示大小均为 4096。生成速度的评估是在额外生成 128 个 token 的情况下进行。LLM 推理生成第一个词元的方法与生成后续词元的方法有所不同。第一个词元的推理受计算资源限制,而后续词元的生成受内存资源限制。因此,Apple 还评估了另外 128 个芯片的生成速度。M5 的性能比 M4 提升了 19% 至 27%。在我们测试的架构中,M5 相比 M4 的性能提升了 19% 至 27%,这得益于更高的内存带宽(M4 为 120GB/s,M5 为 153GB/s,提升了 28%)。在内存占用方面,24GB 的 MacBook Pro 可以轻松容纳 8 位数的 BF16 精度数据或 30 位数的 MoE 4 位量化数据,从而使这两种架构的推理工作负载都保持在 18GB 以下。Apple 还对比了图像生成的性能差异,并表示 M5 的速度比 M4 快 3.8 倍以上。