IT时报记者郝俊慧
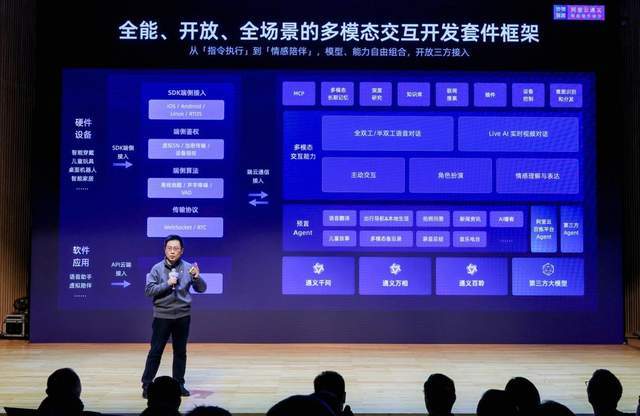
1月8日,在阿里云通义智能硬件展上,阿里云发布了多模态交互开发套件。该套件集成了通义千问(文本/视觉)、万相(图像)、百聆(语音)三款基础大模型,并预置了十多款覆盖生活与工作场景的Agent(智能体)及MCP工具。
随着大模型能力的增强,智能硬件已正式进入“软硬一体”的深度耦合期。大模型不再仅仅是云端的“大脑”,而是真正进入AI眼镜、具身机器人、陪伴玩具等终端,能听、会看、会思考。相比传统智能音箱基于关键词的简单响应,新一代智能硬件通过多模态感知和长期记忆,正让AI硬件从单纯的“指令响应”向“理解世界”“回答世界”“与世界交互”迭代。
阿里云多模态交互开发套件并不是单纯的基础大模型,它是为硬件企业和解决方案商提供的低开发门槛、响应速度快、场景丰富的平台。在芯片层面,该套件适配了30多款主流ARM、RISC-V和MIPS架构终端芯片平台,可满足市面上绝大多数硬件设备的快速接入需求。
未来,通义大模型还将与玄铁RISC-V实现软硬全链路的协同优化,实现通义大模型家族在RISC-V架构上的极致高效部署和推理性能。
在模型优化层面,除通义模型家族外,阿里云针对大量多模态交互场景进行分析,推出适合AI硬件交互的专有模型,全面支持全双工语音、视频、图文等交互方式,端到端语音交互时延可低至1秒,视频交互时延可低至1.5秒。
此外,该套件预置十多款MCP工具和Agent,覆盖生活、工作、娱乐、教育等多个场景,例如,基于预置的出行规划Agent,用户可直接调用路线规划、旅行攻略、吃喝玩乐探索等能力。
该套件还接入了阿里云百炼平台生态,用户不仅可以添加其他开发者提供的MCP和Agent模板,还能通过A2A协议兼容三方Agent,极大程度地扩展了应用的能力边界,帮助企业灵活搭建业务场景。
在应用落地方面,阿里云展示了针对智能穿戴设备、陪伴机器人、具身智能等领域的解决方案。在AI视觉场景中,基于千问VL、百聆CosyVoice等解决方案,阿里云构建了包含感知层、规划层、执行层以及长期记忆的完整交互流程,可最终实现同声传译、摄像模组翻译、多模态交互、录音转写等功能,解决了交互不自然、应答准确率低的痛点。
针对家庭陪伴机器人场景,基于千问模型和多模态交互套件的解决方案可实时监测异常状况并处理同类信息,用户可以基于关键词查找、定位视频,实现与机器人的对话和交互及设备控制。

根据国际权威市场研究机构Gartner发布的生成式AI技术创新指南系列报告,阿里云在生成式AI云基础设施、生成式AI工程、生成式AI模型以及AI知识管理应用四个维度均位于新兴领导者象限,是唯一代表全部四项新兴领导者象限中均占有一席之地的亚太企业。
当AI眼镜能看懂冰箱里的食材并主动规划菜谱,大模型才真正算得上“具身”。这种“体感无缝”的响应,是大模型真正渗透进人类生活空间的开始。