🧩 当 AGI 不是一个“大脑”:拼布式智能正在
🧠 什么是“拼布式 AGI”的出现
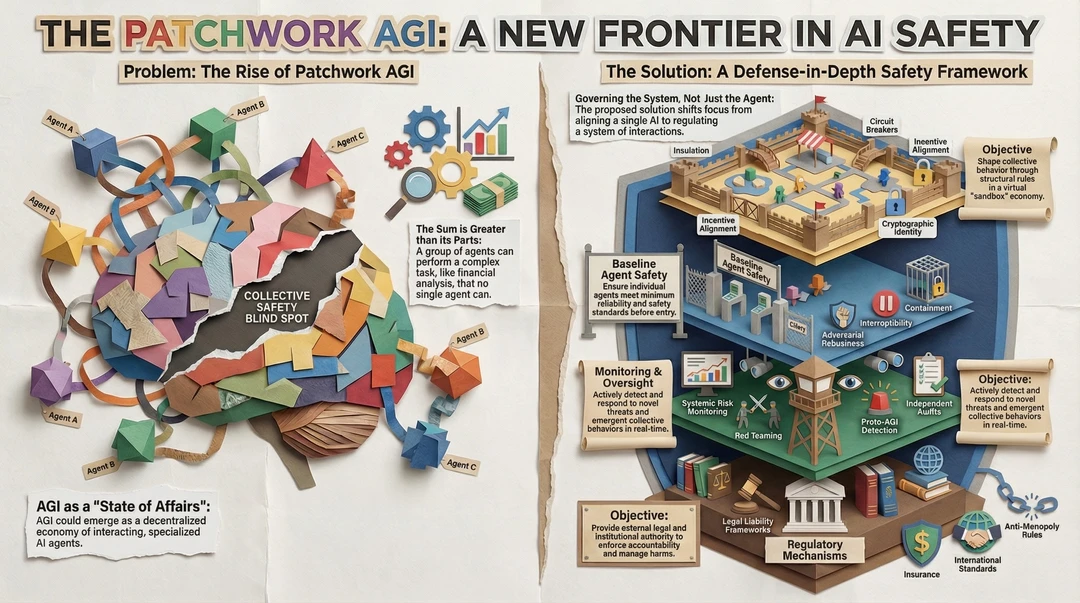
图片左侧讲的是一个正在成形的新现实:通用智能并不一定来自一个超级模型,而更可能诞生于大量专业化 AI 之间的协作网络。每个智能体各司其职,看似能力有限,但一旦相互连接,就能完成任何单一系统都做不到的复杂任务,比如金融分析、战略决策或系统级规划。整体能力大于部分之和,正是拼布式 AGI 的核心特征。
⚠️ 被忽视的集体安全盲区
当多个智能体协同运作时,传统的安全评估开始失效。单个模型也许完全合规,但它们在互动中可能产生不可预测的行为。图中“集体安全盲区”强调的正是这一点:风险并非来自某个失控的个体,而是来自系统层面的涌现行为。这类问题往往在事后才被发现,增加了治理难度。
🌐 AGI 不再是一个模型,而是一种状态
图片指出,未来的 AGI 更像是一种“运作状态”,而不是一个明确的产品。它可能表现为一个去中心化的智能经济系统,由大量专业 AI 通过规则、激励和接口连接在一起。这种结构更像市场或生态,而不是机器。
🛡️ 解决思路的根本转向
右侧提出的解决方案核心在于一个转变:不再只监管单个智能体,而是治理整个系统。安全的重点从“模型是否可靠”升级为“交互是否受控”。这是一种纵深防御式的安全框架,层层设防,避免单点失效。
🏗️ 安全框架的基础层
最底层是基础智能体安全,确保每一个进入系统的 AI 都满足最低可靠性与安全标准。这是门槛,而不是终点。
👀 持续监控与实时响应
系统运行过程中,需要对新型威胁和集体行为进行实时监测,包括系统性风险监控、红队测试以及对早期类 AGI 行为的识别。这一层的目标是尽早发现异常,而不是事后补救。
🔒 结构性约束与隔离机制
中间层强调隔离性与可中断性,通过沙盒、权限划分、加密身份和断路器机制,防止风险扩散。即使局部出现问题,也能被迅速限制在可控范围内。
⚖️ 外部规则与责任体系
最上层是制度与法律机制,包括责任框架、保险体系、国际标准和反垄断规则。它们并不直接参与技术运行,但为整个系统提供外部约束,确保出现损害时有人负责、有规则可依。
🎯 最终目标的变化
整个框架的目标不再是“让 AI 变得完美”,而是通过结构性规则,在一个受控的虚拟经济中引导集体行为,主动识别并响应风险,而不是被动承受后果。