[LG]《Shaping capabilities with token-level data filtering》N Rathi, A Radford [Anthropic] (2026)
如何从源头上塑造AI的能力,而不仅仅是事后修补?Neil Rathi与Alec Radford(OpenAI)的最新研究为我们揭示了一个关键结论:能力塑造必须始于预训练,且精准到Token级别。
以下是关于这项研究的深度解析。
1. 幽灵在底座中:为什么后期防御注定失败
目前的AI安全主要依赖于事后补救,如RLHF或机器遗忘。但这些方法只是在模型表面涂了一层保护漆。一旦有害能力进入了预训练底座,它就成了挥之不去的幽灵。攻击者可以通过简单的微调或越狱手段,轻易地将这些能力重新唤醒。
金句:一旦能力在底座中扎根,安全就成了一场永无止境的猫鼠游戏。
2. Token级过滤:手术刀般的精准
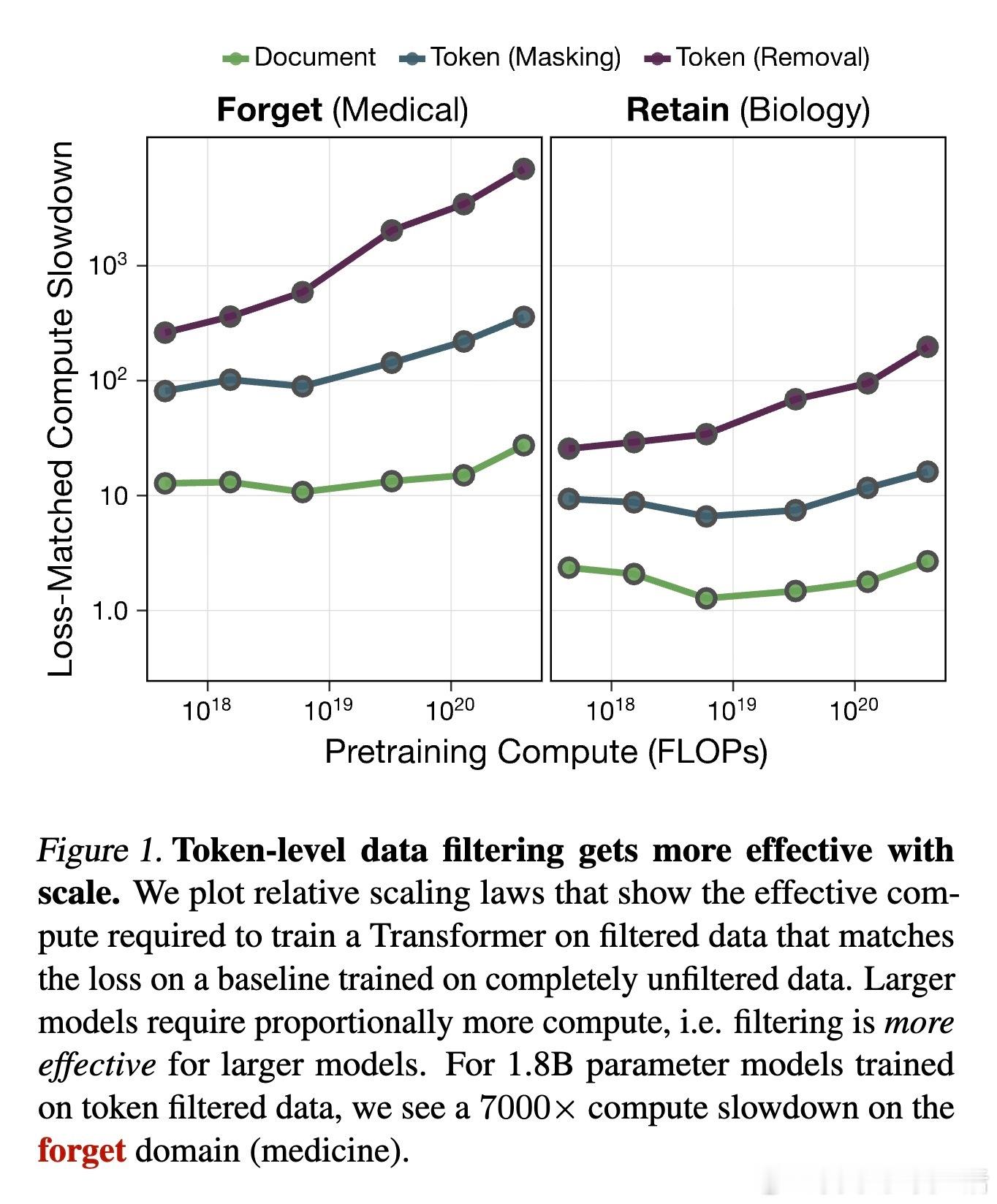
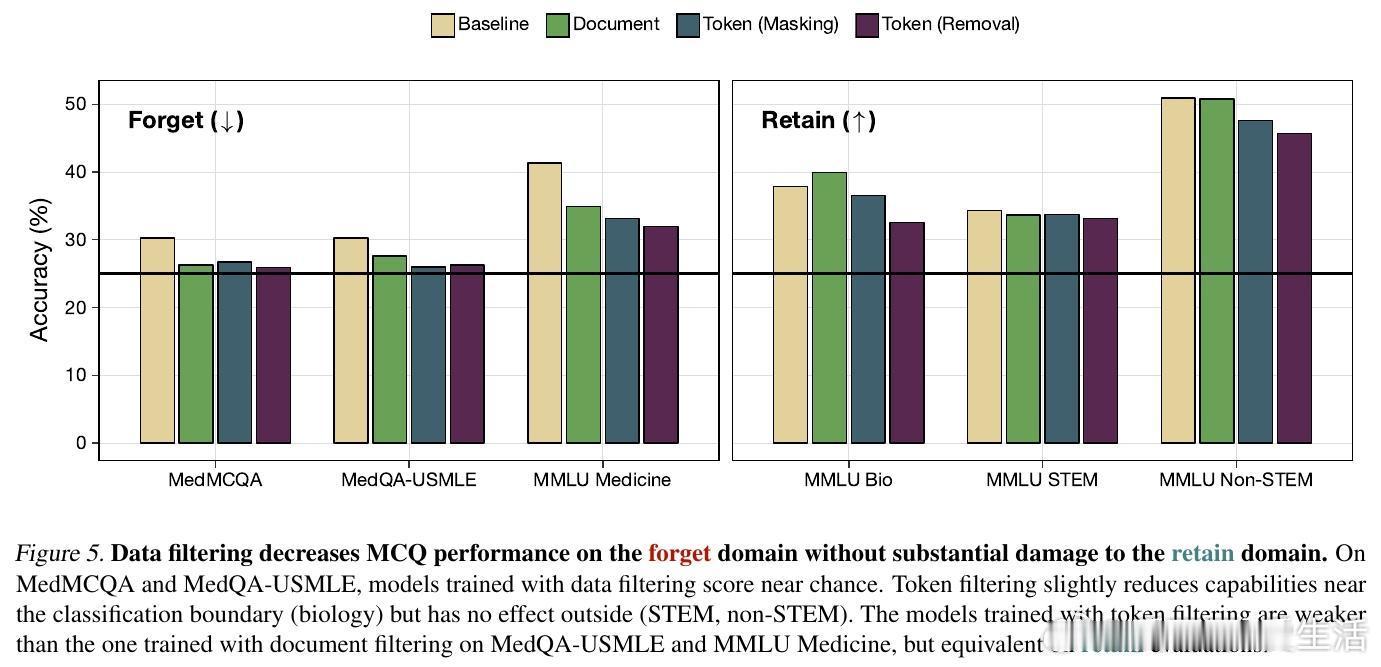
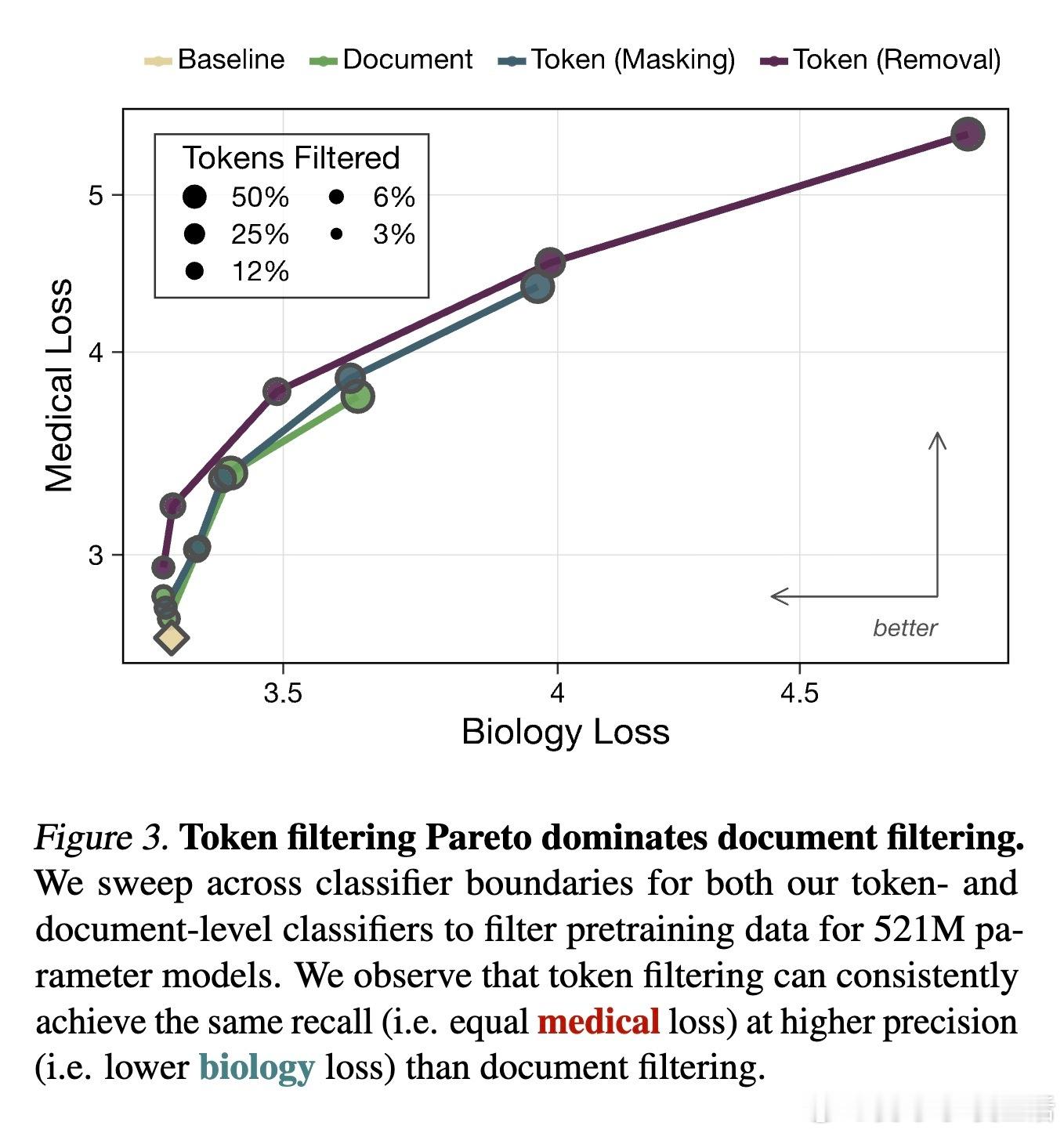
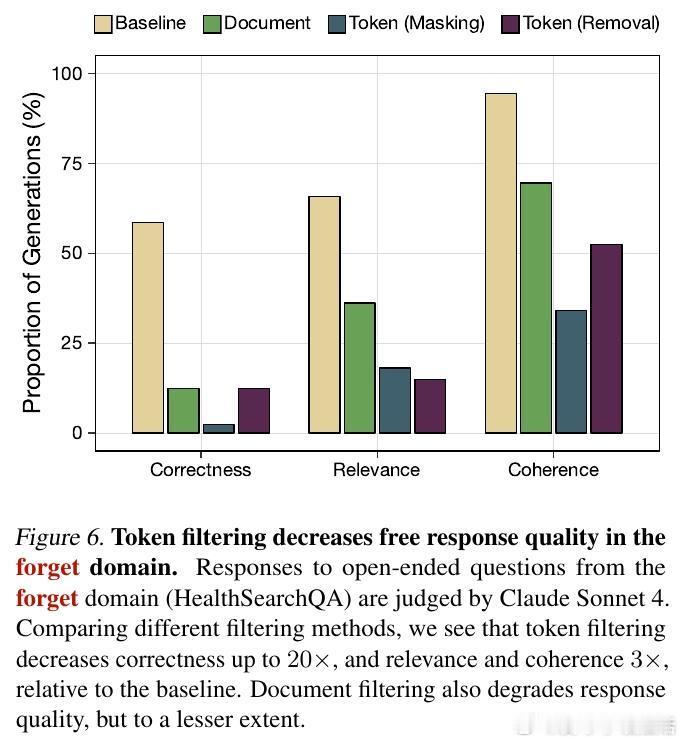
传统的做法是删除整个文档,但这往往会误伤无辜的知识。研究提出了一种Token级数据过滤方法:通过模型预测,精准地在预训练过程中屏蔽或删除特定领域的Token。实验证明,Token级过滤在保持通用能力的同时,对特定能力的削减效果远超文档级过滤。
这种方法在本质上是数据归因理论的实践。它告诉我们,模型能力的获得往往取决于文档中那些关键的片段,而非整篇文章。
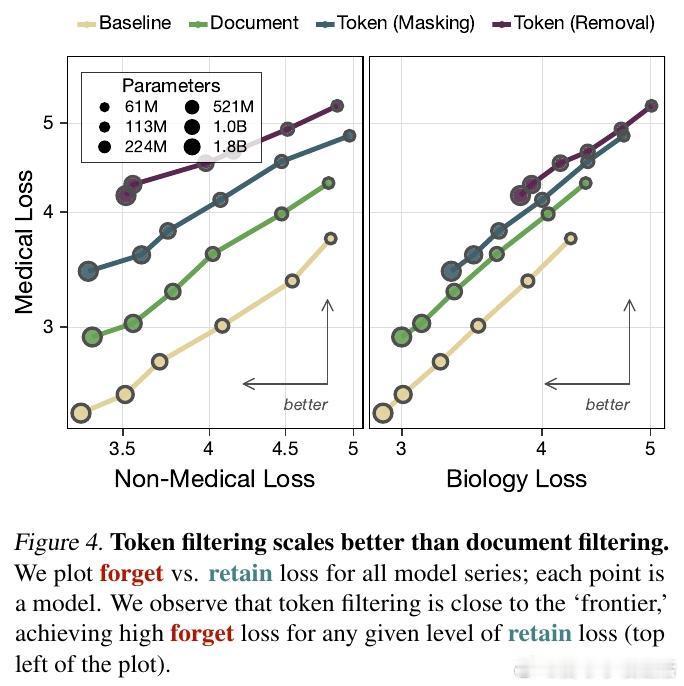
3. 规模效应的惊喜:越强大,越安全
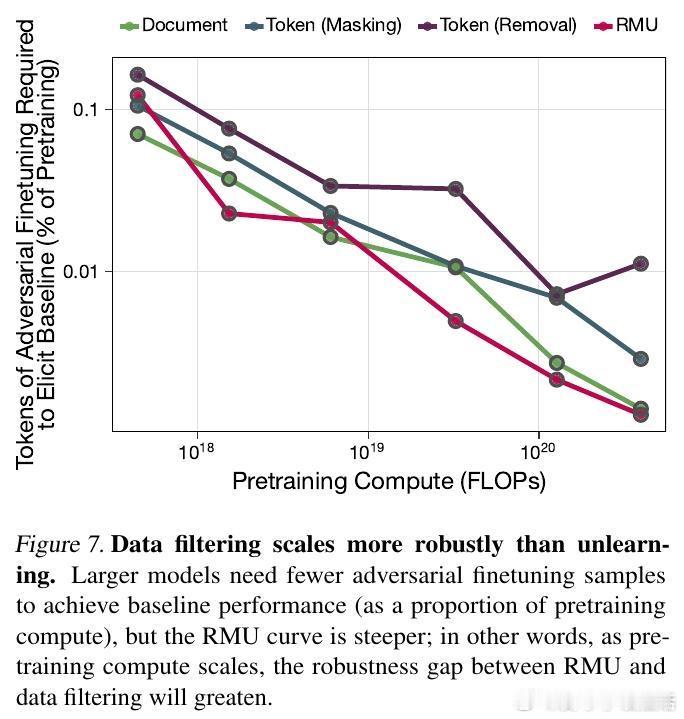
这是这项研究最令人振奋的发现:过滤的效果随模型规模的扩大而增强。在1.8B参数的模型上,Token过滤让模型学习特定领域(如医学)的计算成本增加了7000倍。这意味着,在大模型时代,这种源头治理的方法不仅有效,而且具有极佳的扩展性。
金句:规模不仅是能力的放大器,也可以成为安全防线的倍增器。
4. 韧性测试:比遗忘更彻底的清除
研究对比了目前最先进的机器遗忘技术(如RMU)。结果显示,面对恶意微调攻击,通过Token过滤训练的模型展现出了10倍以上的韧性。机器遗忘往往只是混淆了表征,而数据过滤则是从根本上切断了知识的来源,让模型在面对诱导时无从应起。
5. 意外的收获:过滤让对齐变得更容易
一个长期的担忧是,如果模型在预训练中没见过某些内容,它是否就无法学会拒绝?研究给出了否定的答案。事实上,Token级过滤后的模型在拒绝训练中表现得更好。因为它能更清晰地识别出已知分布与未知禁区之间的界限。
这种分布上的差异,为模型建立了一道天然的认知屏障,使得安全指令的泛化变得更加顺畅。
6. 技术实现:SAE与弱监督的胜利
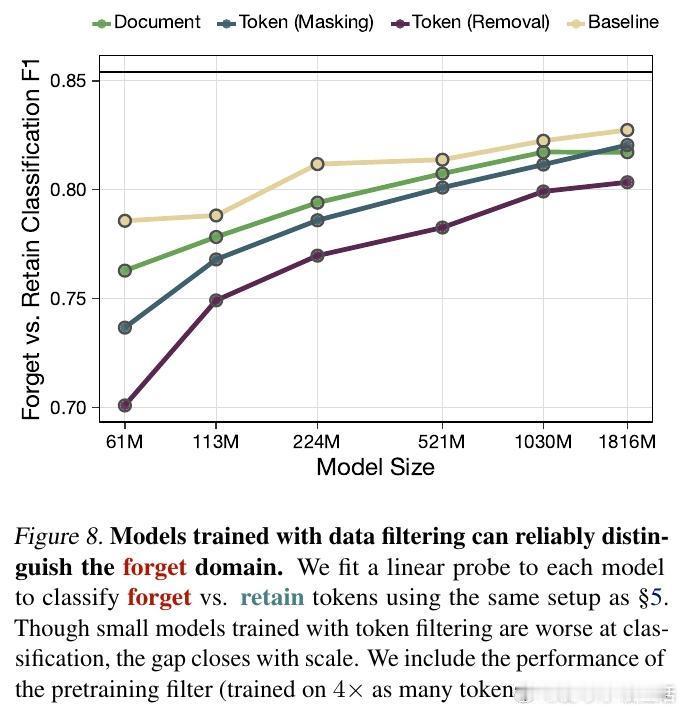
如何在大规模语料中精准标记Token?研究引入了一套利用稀疏自编码器(SAE)提取特征,并将其蒸馏到小型双向语言模型(biLM)的流程。即便标注存在噪声,只要算力充足,模型依然能从弱信号中学习到正确的过滤方向。这证明了我们不需要完美的标签,也能构建强大的过滤器。
7. 思考深度:安全应是底座的基因
这项研究标志着AI安全范式的转型:从后期的行为约束转向前期的能力塑造。安全不应该是模型训练完成后的附加组件,而应该是底座基因的一部分。通过在预训练阶段精准地修剪能力树,我们可以构建出天然具备免疫力的基础模型。
真正的安全不是学会克制欲望,而是从一开始就缺乏产生危险欲望的土壤。
论文链接:arxiv.org/abs/2601.21571