北大&小鹏汽车《EvoDriveVLA》论文,作者中出现了xianming,这套训练方法有点意思,给大家做个小总结:
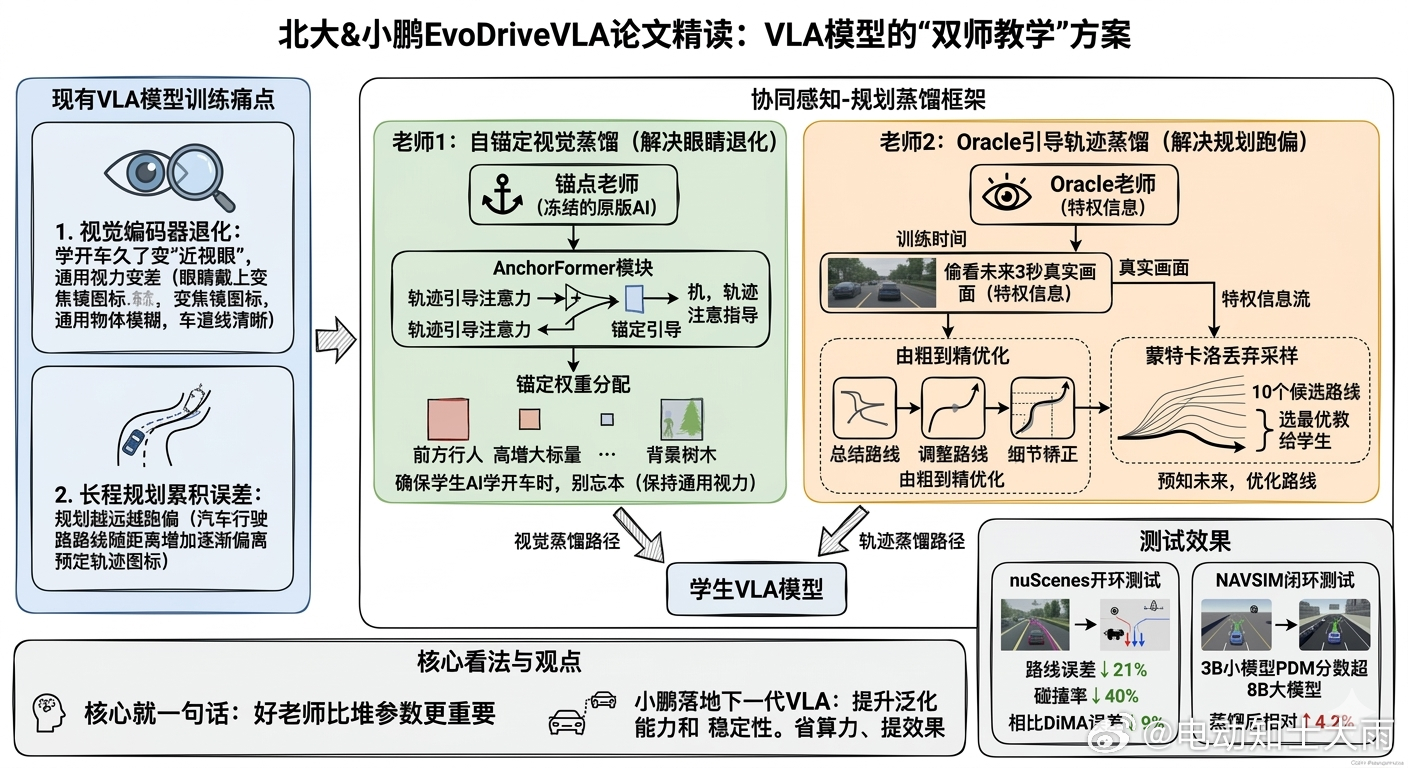
现在的端到端VLA模型训练有个通病——视觉编码器退化。简单说就是AI学开车学久了,原来能认猫狗、辨天气的"通用视力"反而变差,变成只会看车道线的"近视眼"。同时长程规划会累积误差,规划越远越跑偏。
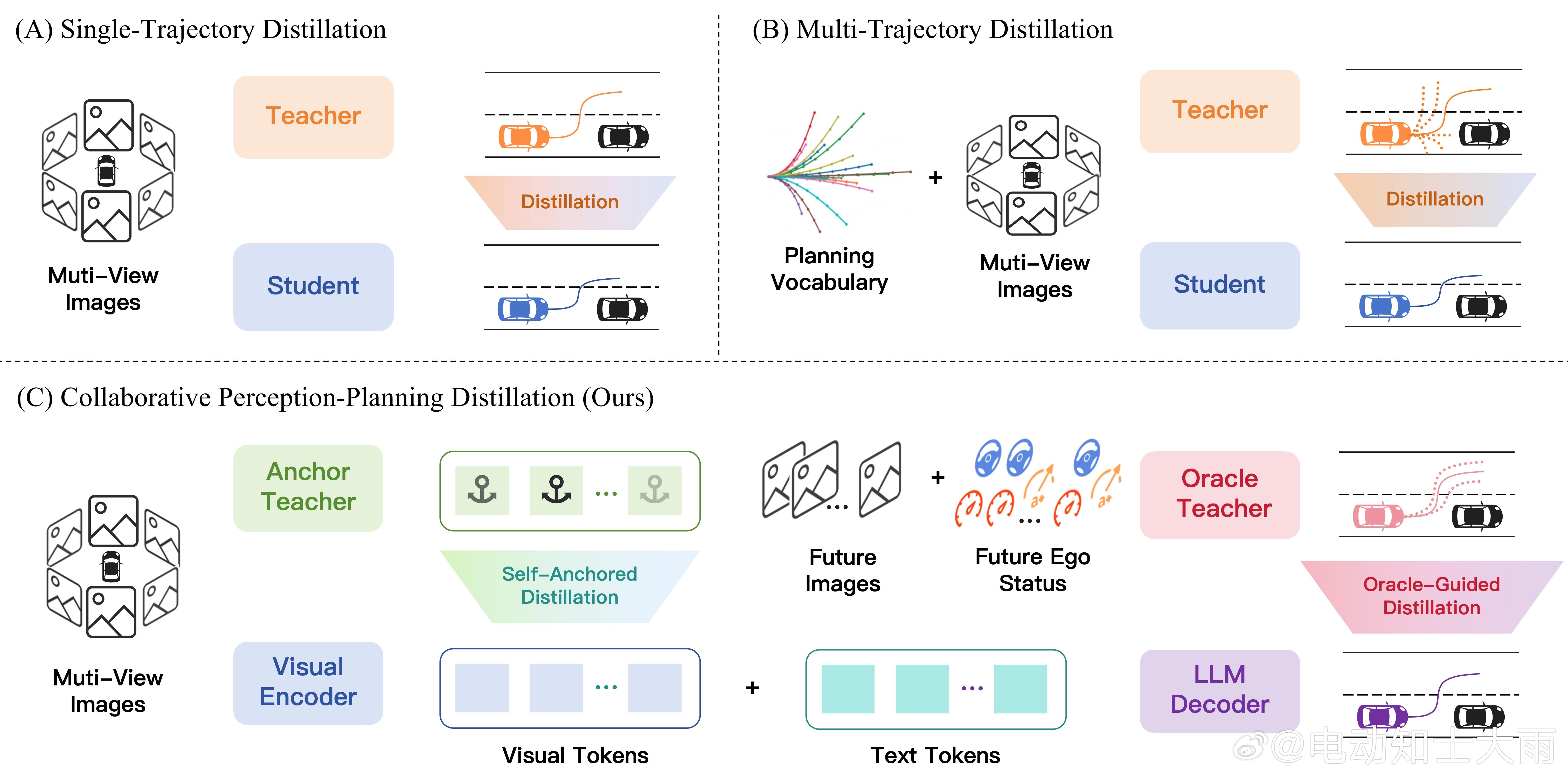
论文提出了VLA模型的"双师教学"方案:协同感知-规划蒸馏框架,让AI同时拜两个老师。
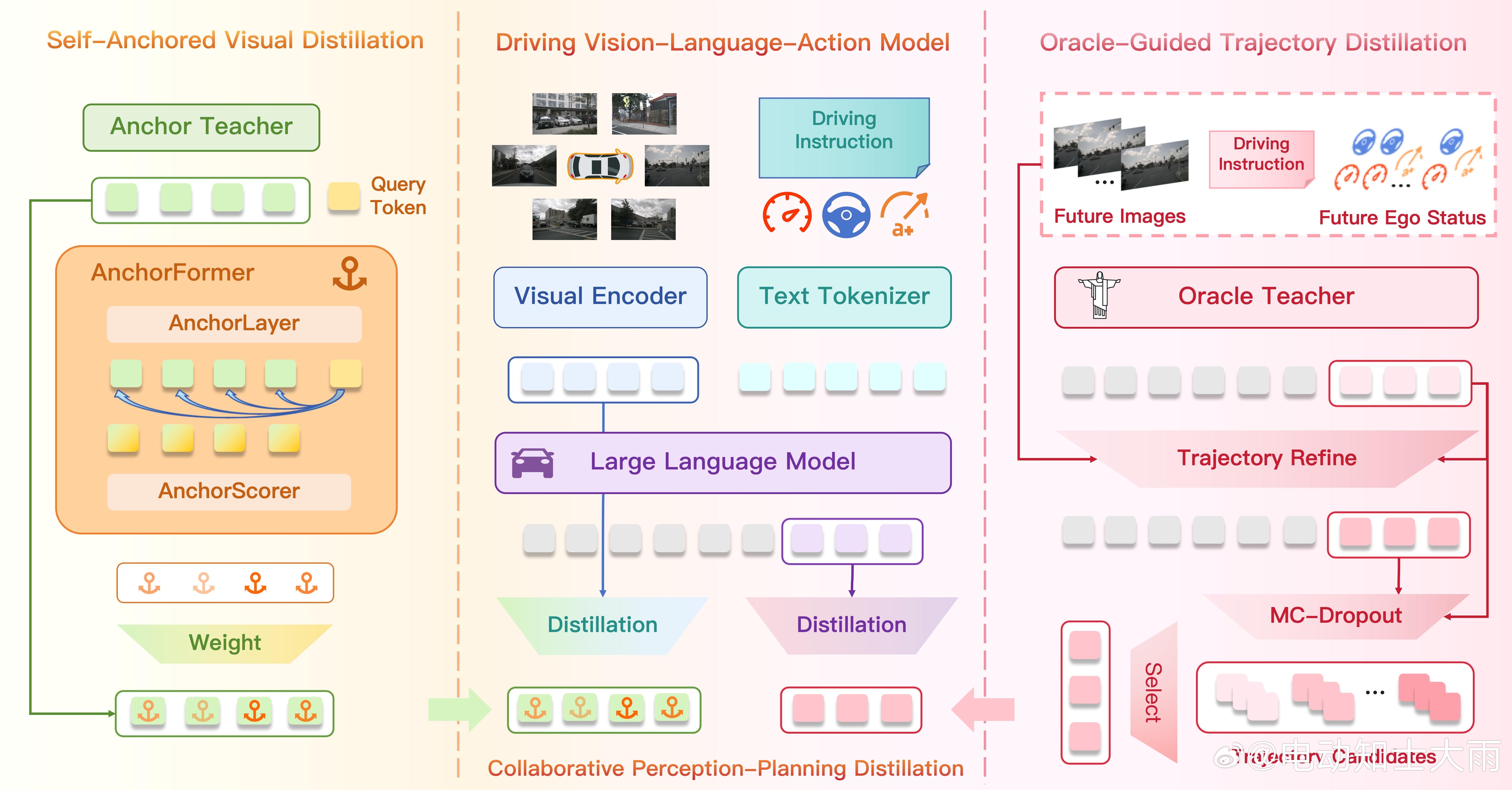
老师1:自锚定视觉蒸馏(解决眼睛退化)
复制一个冻结的"原版AI"当锚点老师,用AnchorFormer模块,根据轨迹引导注意力给不同区域分配"锚定权重"。
比如前方有行人,那块区域就多盯着点,确保学生AI学开车时,别忘本。
老师2:Oracle引导轨迹蒸馏(解决规划跑偏)
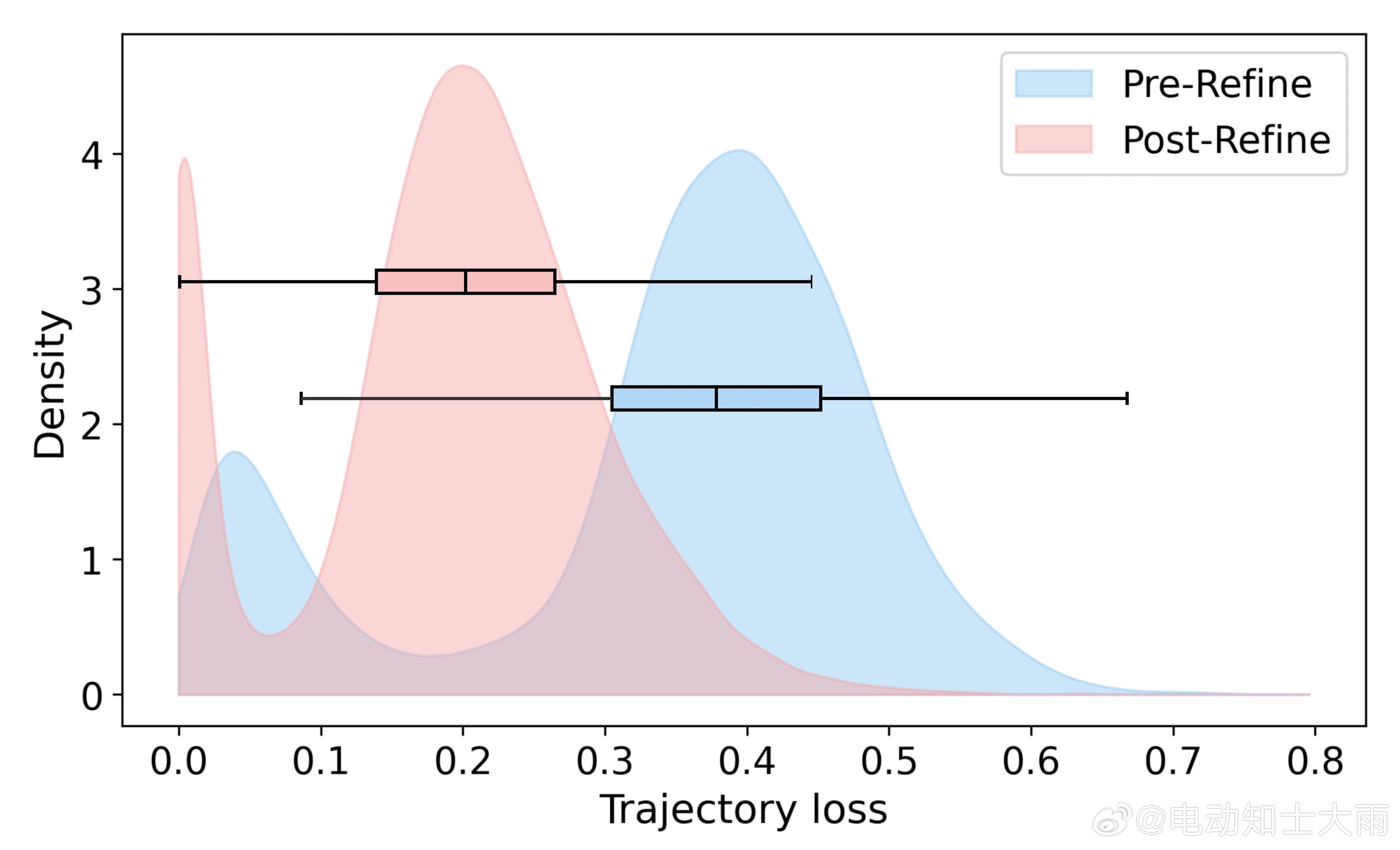
训练时让AI"偷看"未来3秒的真实画面(特权信息)由粗到精优化:
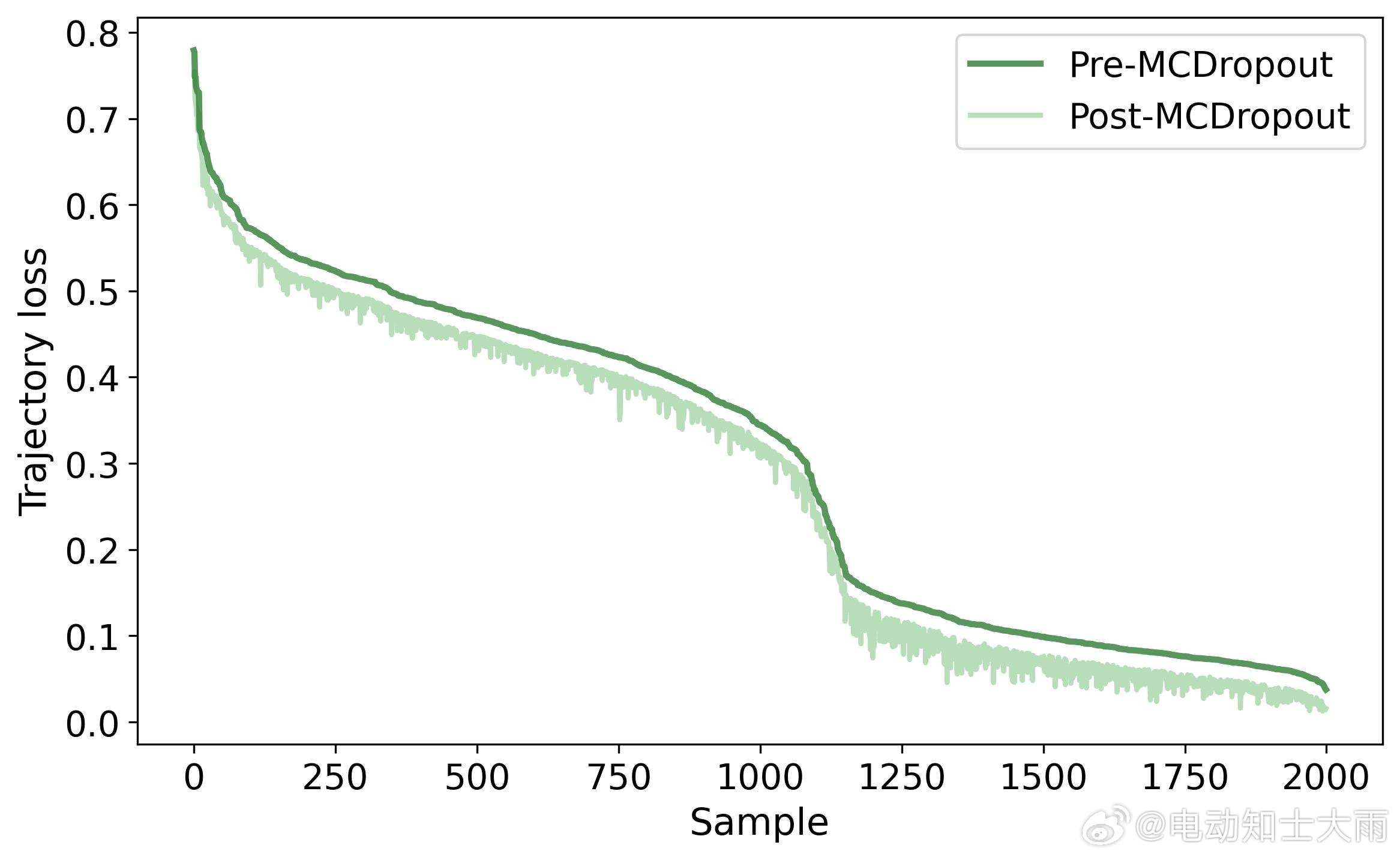
先画个大概路线,再慢慢修正细节。蒙特卡洛丢弃采样:随机生成10条候选路线,选最优的教给学生,学生学的是"如果我能预知未来,我会怎么开"效果怎么样?
▶nuScenes开环测试:相比OpenDriveVLA,路线误差降21%,碰撞率降40%相比DiMA,误差再降9%
▶NAVSIM闭环测试:3B小模型PDM分数超8B大模型蒸馏后相对提升4.2%
我的看法:这套方法论不是直接给VLA2.0用的,但思路可以迁移。核心就一句话:好老师比堆参数更重要。
小鹏如果能把这个蒸馏框架落地到下一代VLA,智驾的泛化能力和稳定性应该还能再拔一截。毕竟现在各家都在卷端到端,谁能把"老师教学生"这套玩明白,谁就能省算力、提效果。
图片8是一图读懂,不喜欢看文字的同学,可以看图。