[LG]《Meta-TTRL: A Metacognitive Framework for Self-Improving Test-Time Reinforcement Learning in Unified Multimodal Models》L S Tan, J Chen, X Fu, L Ma… [Tsinghua University & JD.COM] (2026)
文本到图像生成模型在测试时只能"抽好牌",却不能"从每局游戏中学习"——每次遇到相似提示词,失败模式原封不动地重演,所有测试时算力换来的改善随着推理结束烟消云散,根本原因是现有方法锁死参数、只做采样与搜索,无法将经验转化为能力积累。
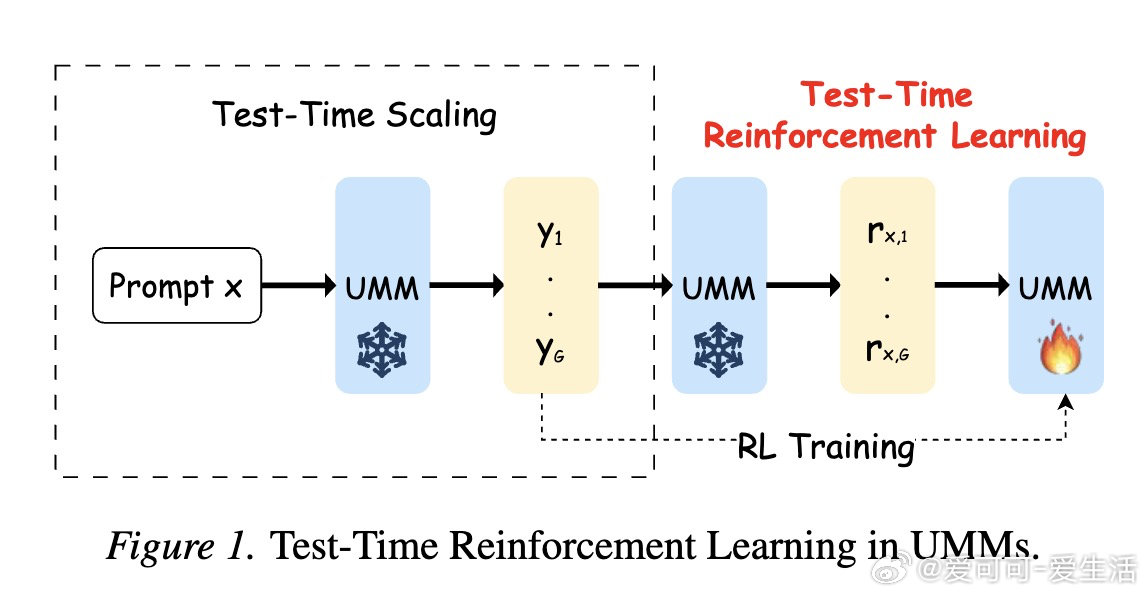
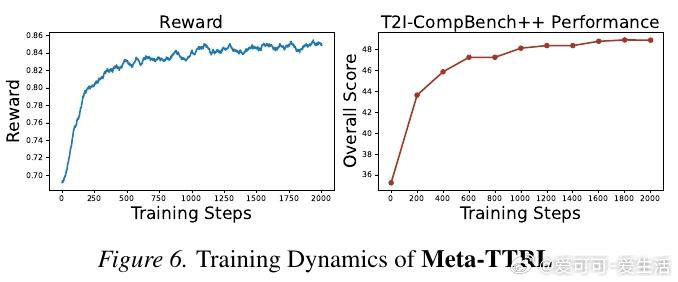
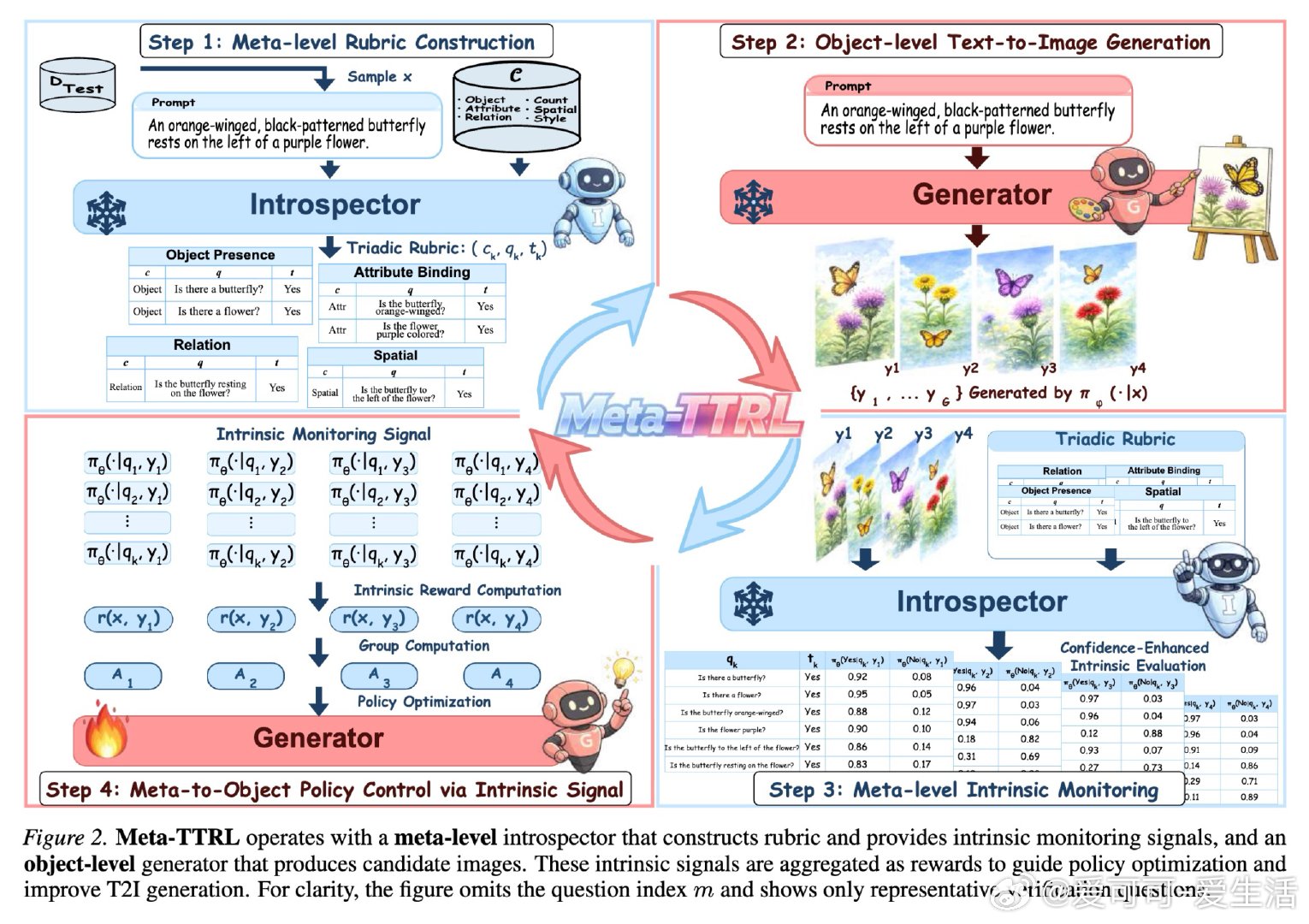
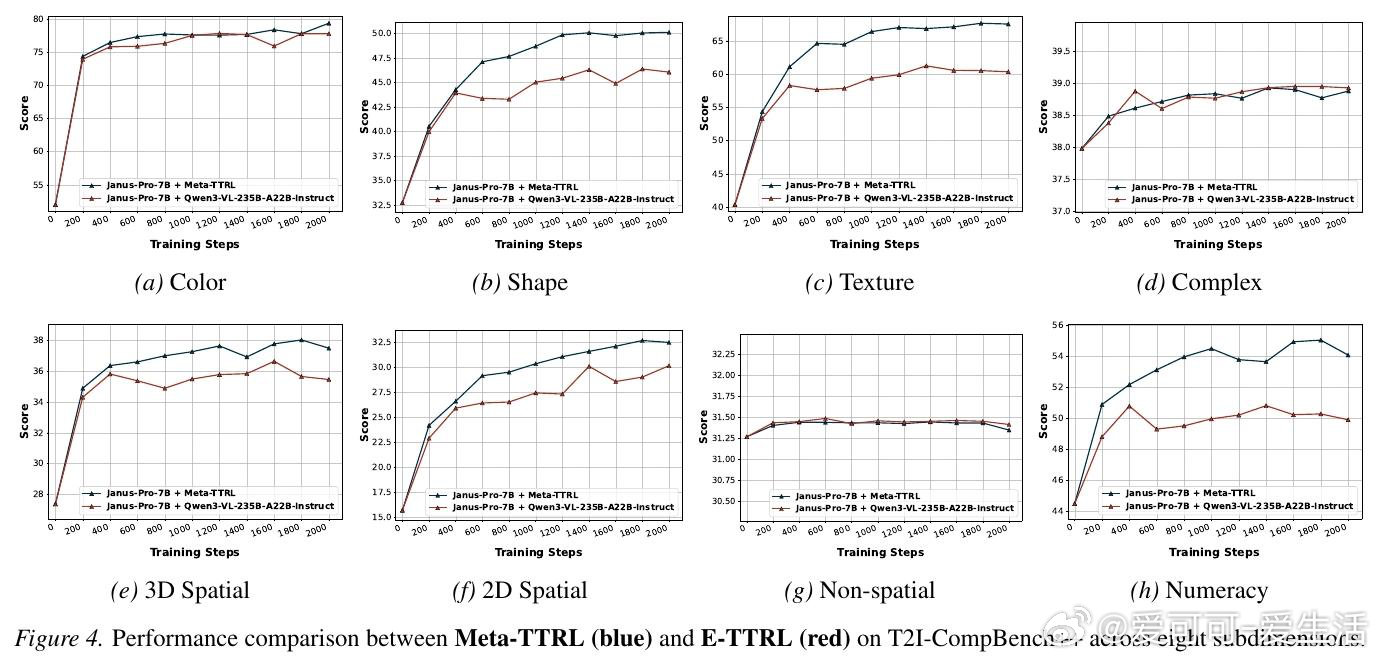
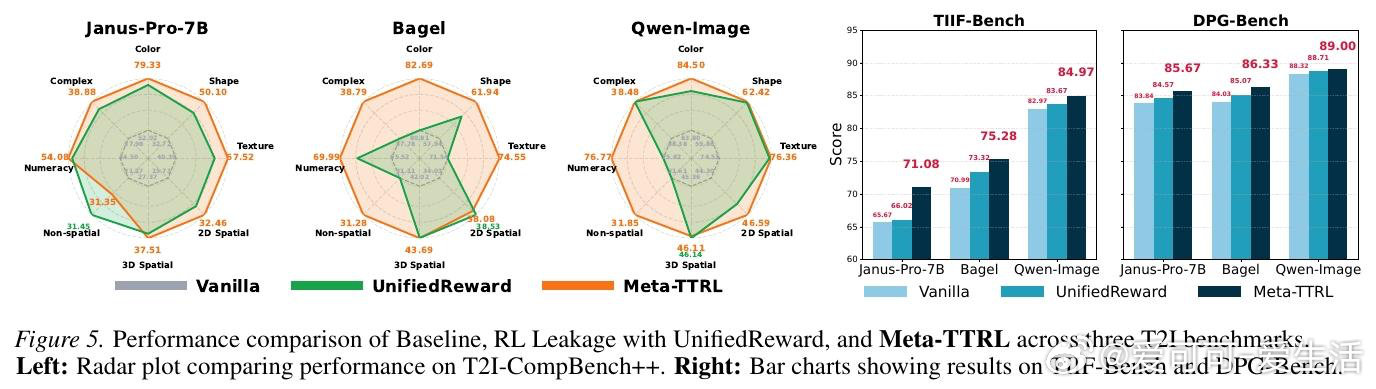
本文的核心洞见是:把模型自身的多模态理解能力重新看作内置的"元认知监考官"。由此,让模型一边生成候选图像,一边用自己的视觉理解能力将提示词分解成可逐项核查的评估细则,再以这份自评分数作为强化学习奖励信号反向更新生成参数——这一"监控—控制"闭环使模型真正从测试经历中学习,性能增益得以在参数层面沉淀下来。
这项工作真正留下的遗产是:证明了模型内生的元知识足以充当奖励信号,无需任何外部评判器即可驱动测试时自我改进,且"信号与模型优化域匹配"比评判器绝对能力更关键。它为后来者打开的新门是:将元认知协同作为设计TTRL系统的核心原则,而非简单堆叠更强的外部奖励模型。但尚未跨过的门槛是:框架依赖模型参数开放可访问,无法适用于闭源系统。
arxiv.org/abs/2603.15724
机器学习 人工智能 论文 AI创造营