[AI]《AI Scientist via Synthetic Task Scaling》Z Cai, H Behl [Princeton University & Microsoft Research] (2026)
训练能做研究的AI,卡在没有训练数据这堵墙上。现有智能体系统大多从论文、代码等静态产物中学习,却跳过了真实研究中最关键的过程——调试、失败、迭代修正。LLM空有知识储备,却无法将其转化为有效的多步骤研究行动。
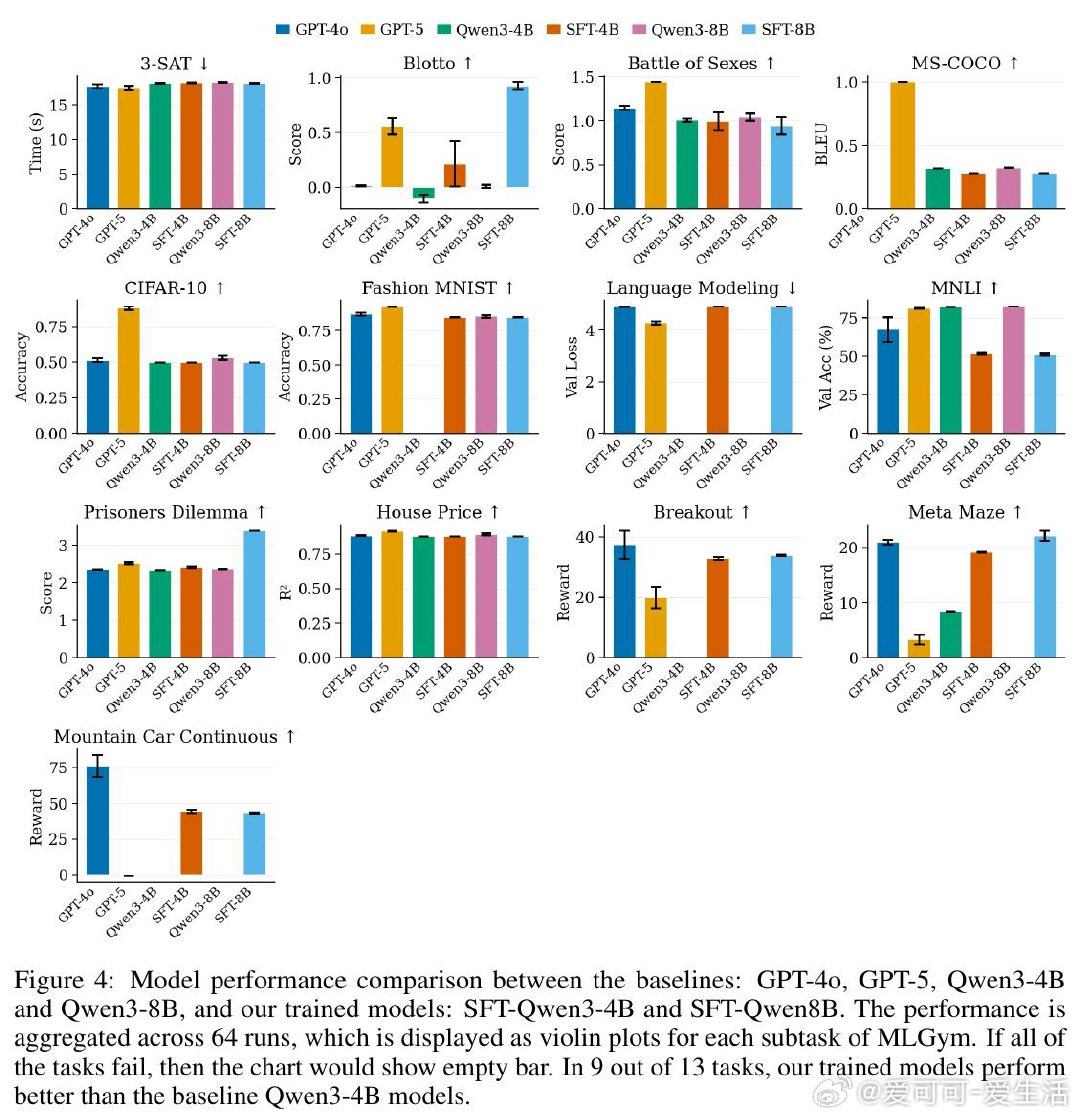
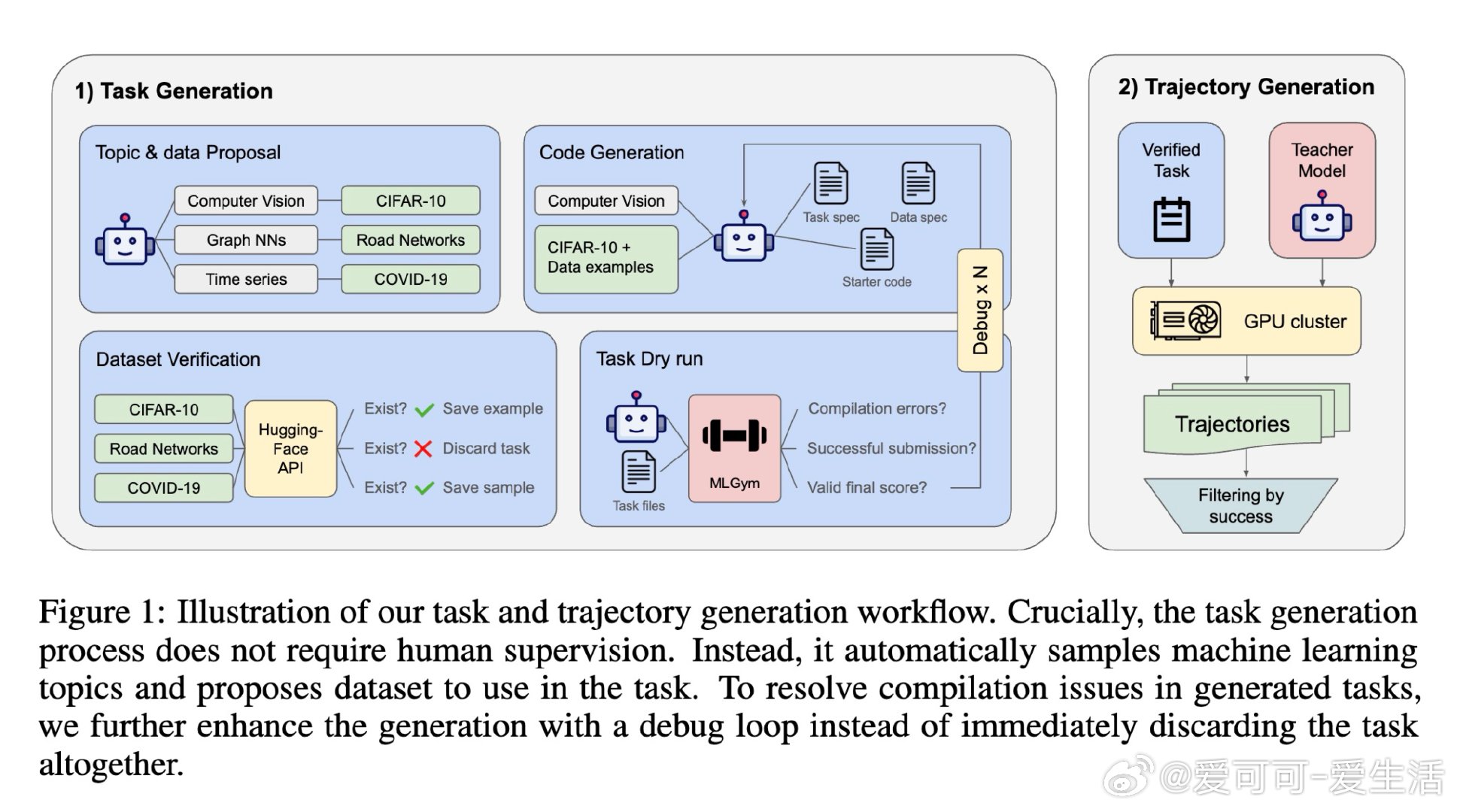
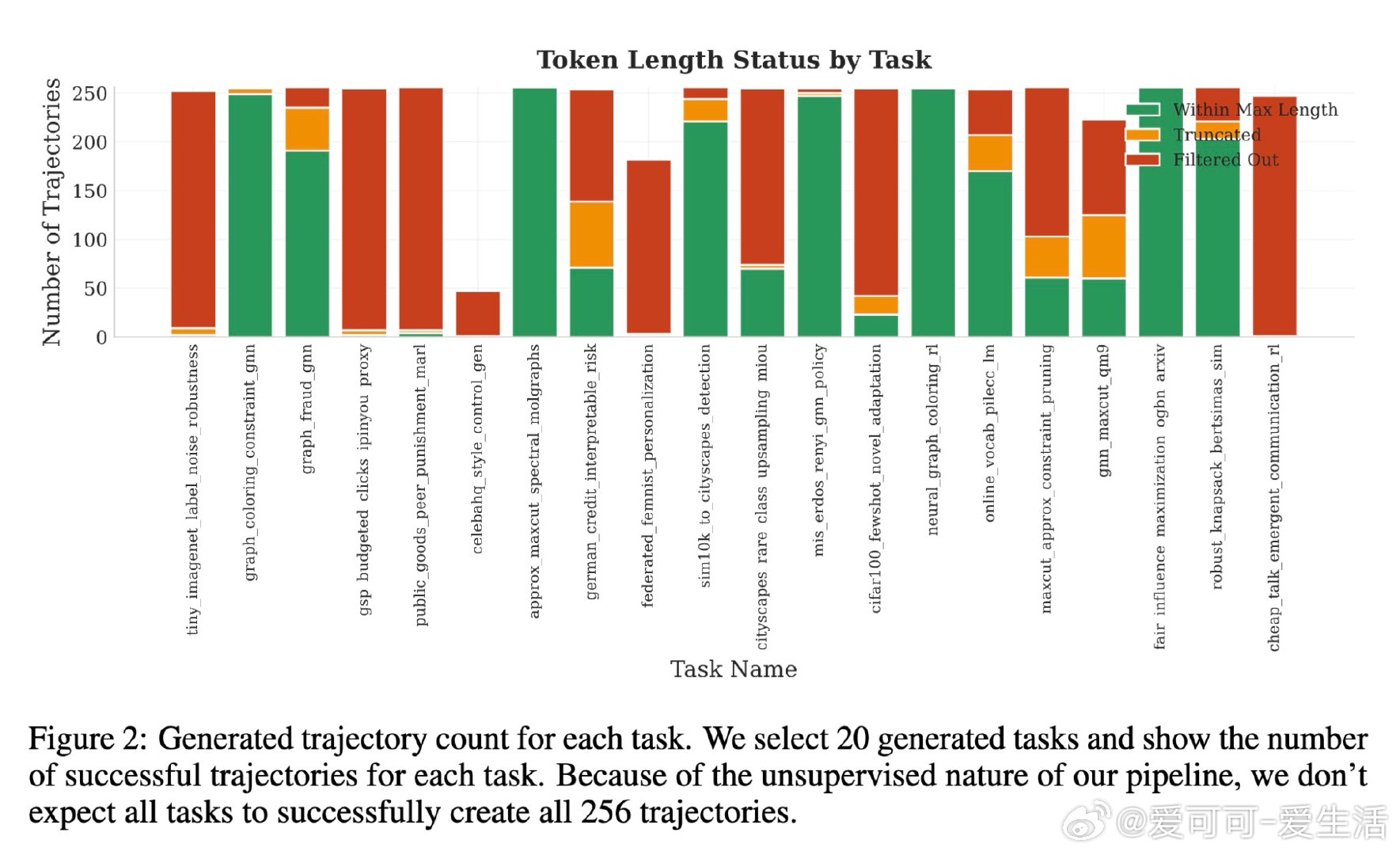
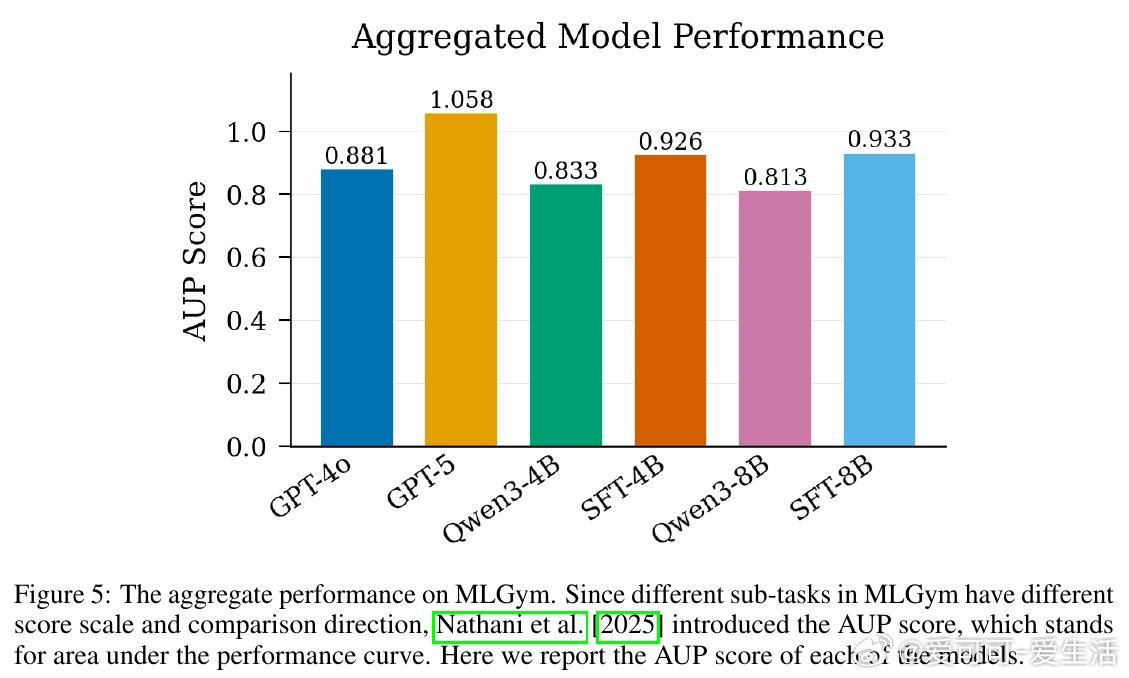
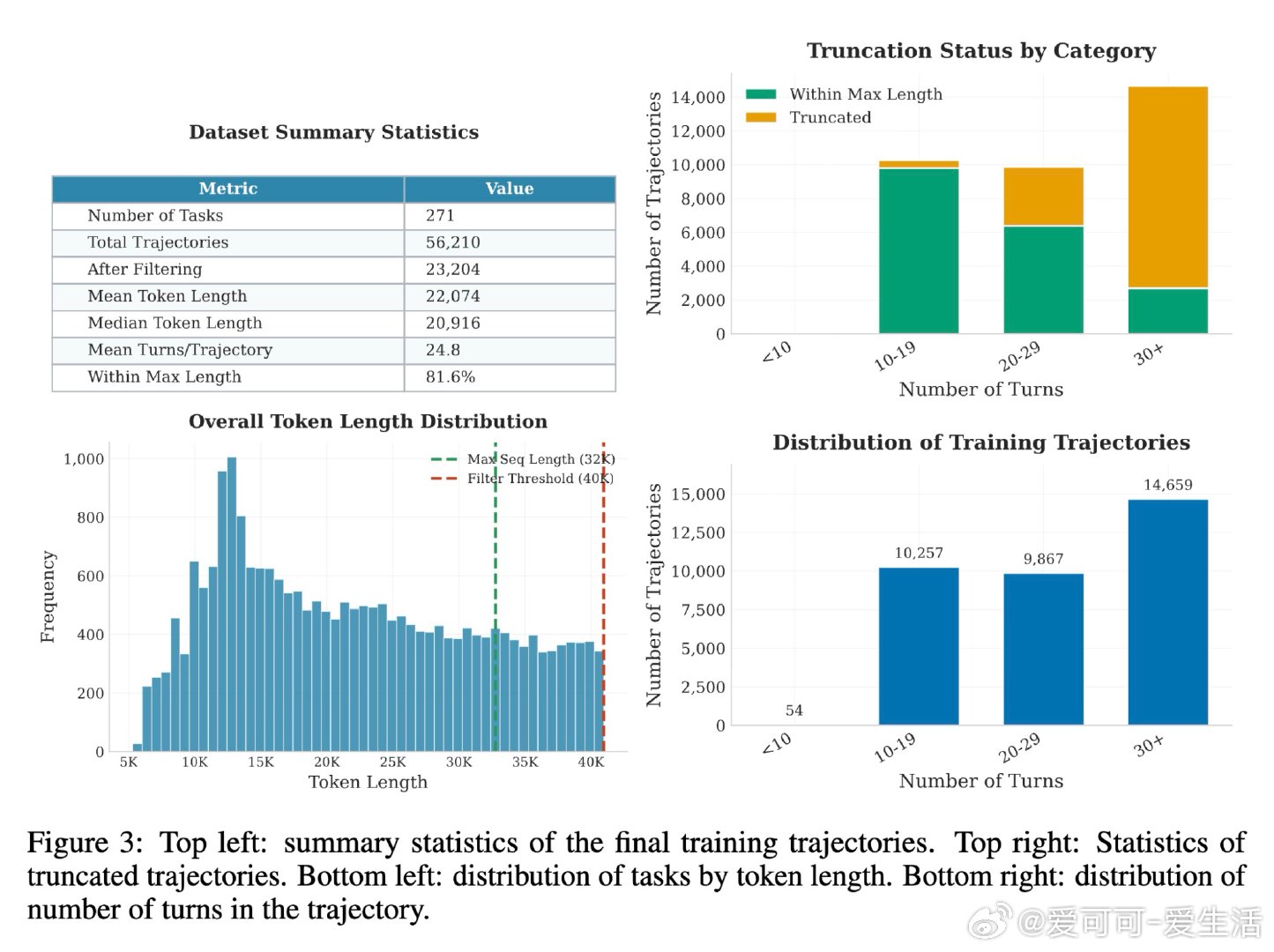
本文的核心洞见是:把"如何获得训练数据"这个问题,重新看作"如何自动制造训练环境"。以GPT-5为教师,全自动生成500个机器学习任务(从主题采样到HuggingFace数据集验证,再到可运行代码),用自调试循环淘汰破损任务,最终蒸馏出3万条真实操作轨迹。Qwen3-4B与8B在MLGym基准上分别提升9%和12%。
这项工作真正留下的遗产是:一条无需人工标注、可大规模扩展的智能体训练范式——用可执行环境替代静态语料。它为后来者打开的新门是将此框架接入强化学习,让奖励信号直接来自任务得分,驱动真正的探索与发现。但尚未跨过的门槛是:当前证据仅限于MLGym单一基准,格式熟悉度与真实能力提升仍无法区分,教师模型的盲区也直接成为学生的天花板。
arxiv.org/abs/2603.17216
机器学习 人工智能 论文 AI创造营