[LG]《PRISM: Demystifying Retention and Interaction in Mid-Training》B Runwal, A Agrawal, A Roy, R Panda [IBM Research] (2026)
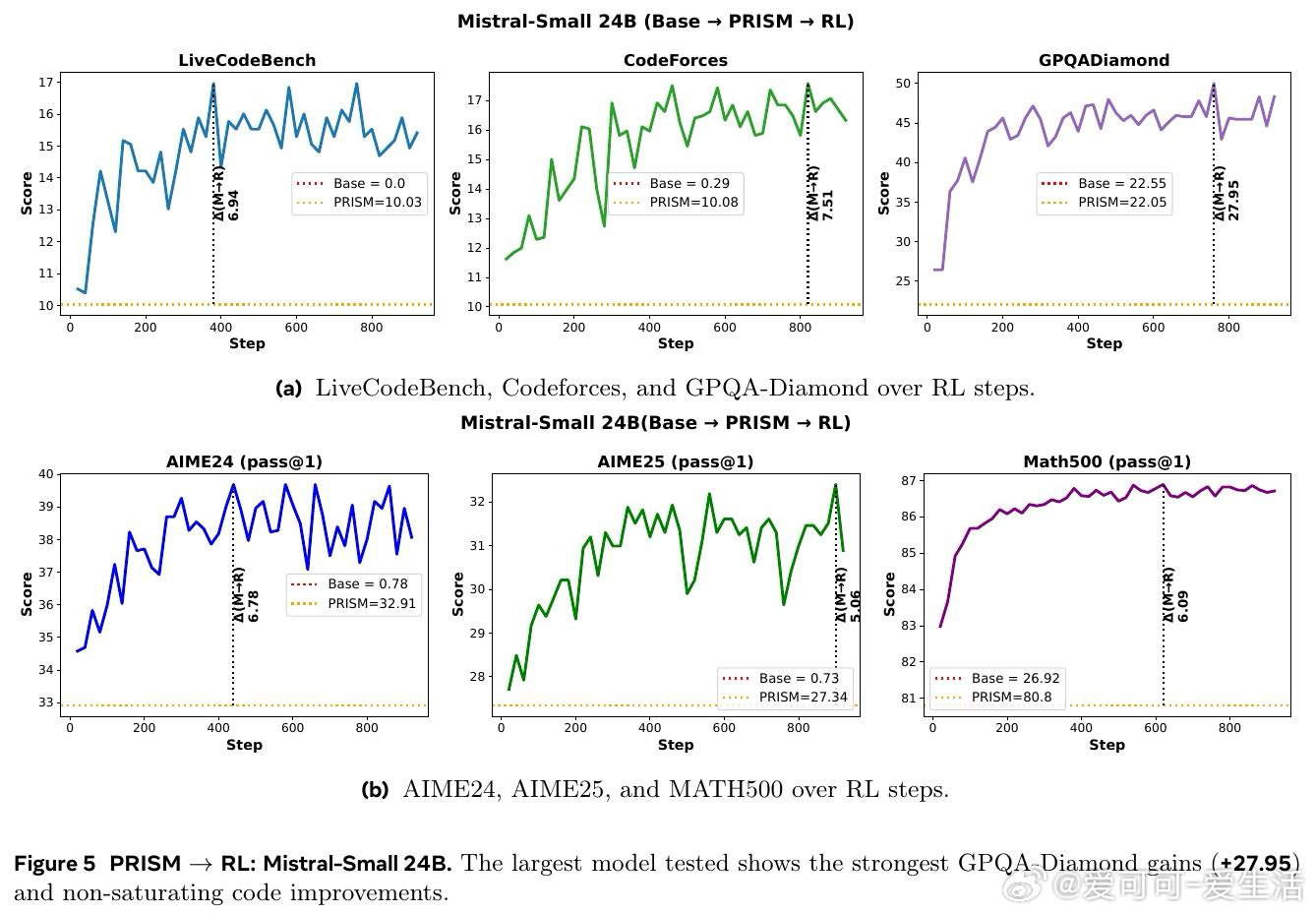
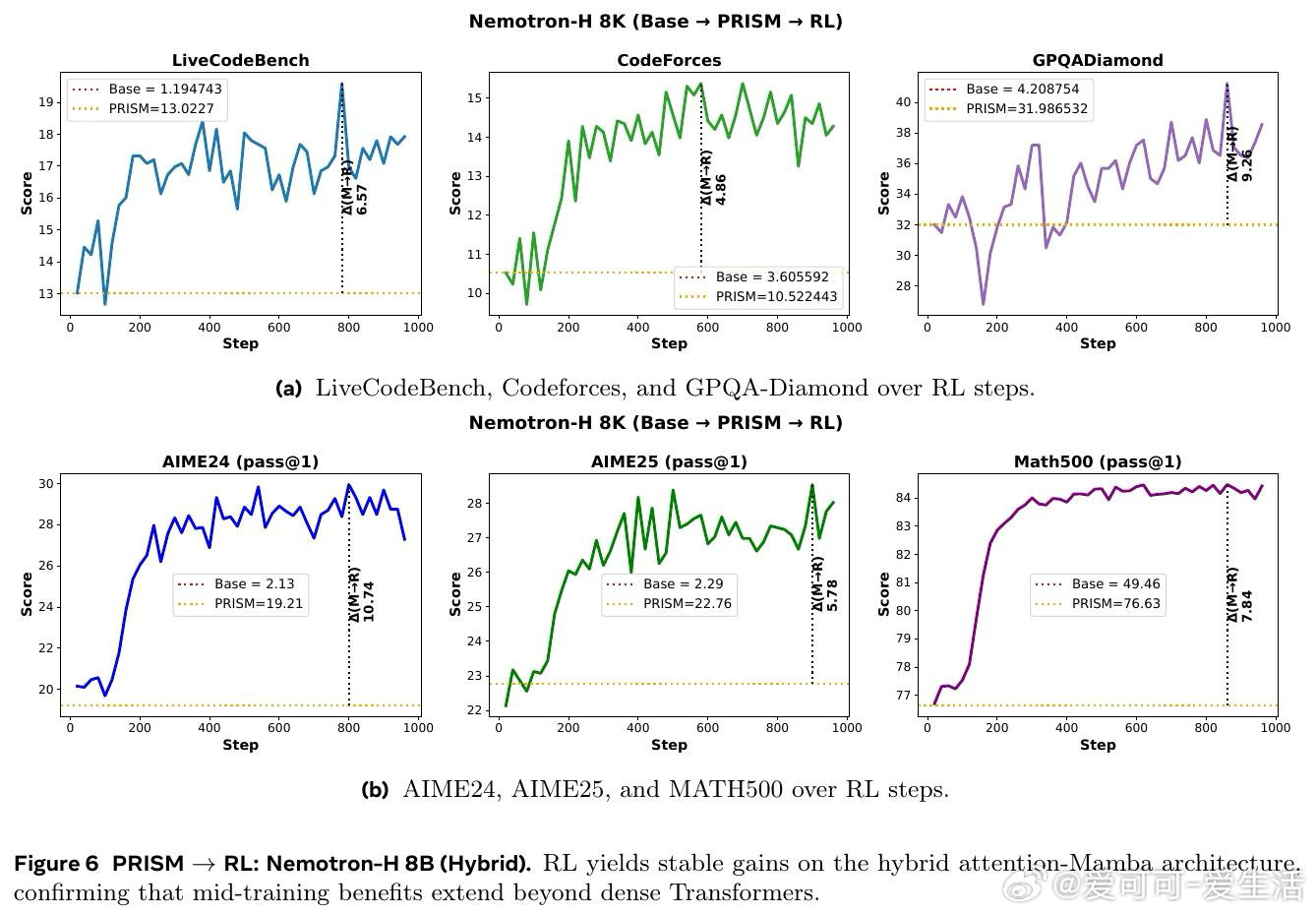
大型语言模型在预训练后,直接接受强化学习(RL)往往收效甚微——AIME数学题的得分接近于零。业界普遍在预训练与RL之间插入一个「中间训练」阶段,却缺乏系统性指引:该用什么数据、多少量、在何时介入,以及它究竟如何影响后续RL?根本原因在于,这三个阶段的相互作用从未被跨模型、跨架构地严格对照研究过。
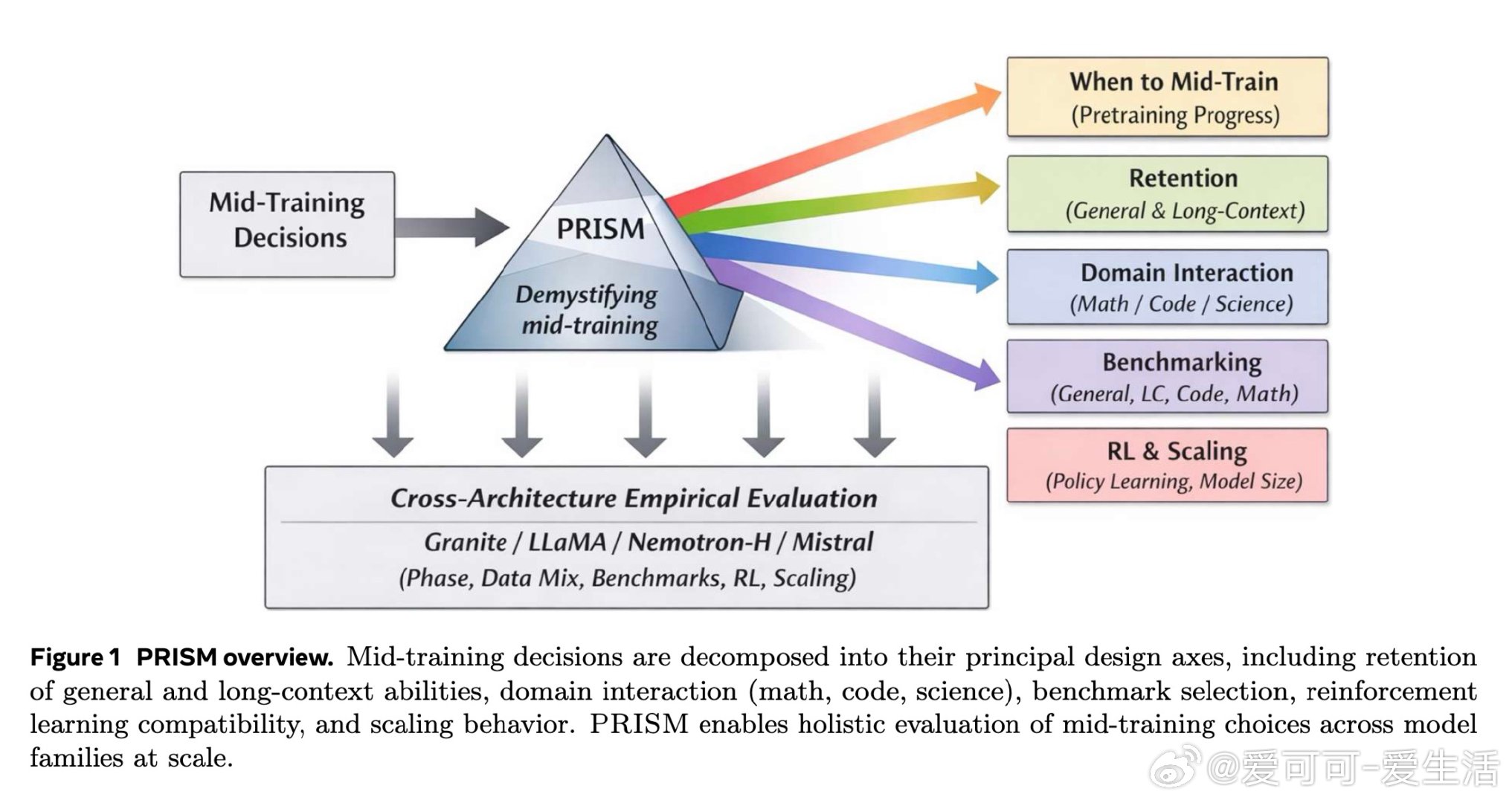
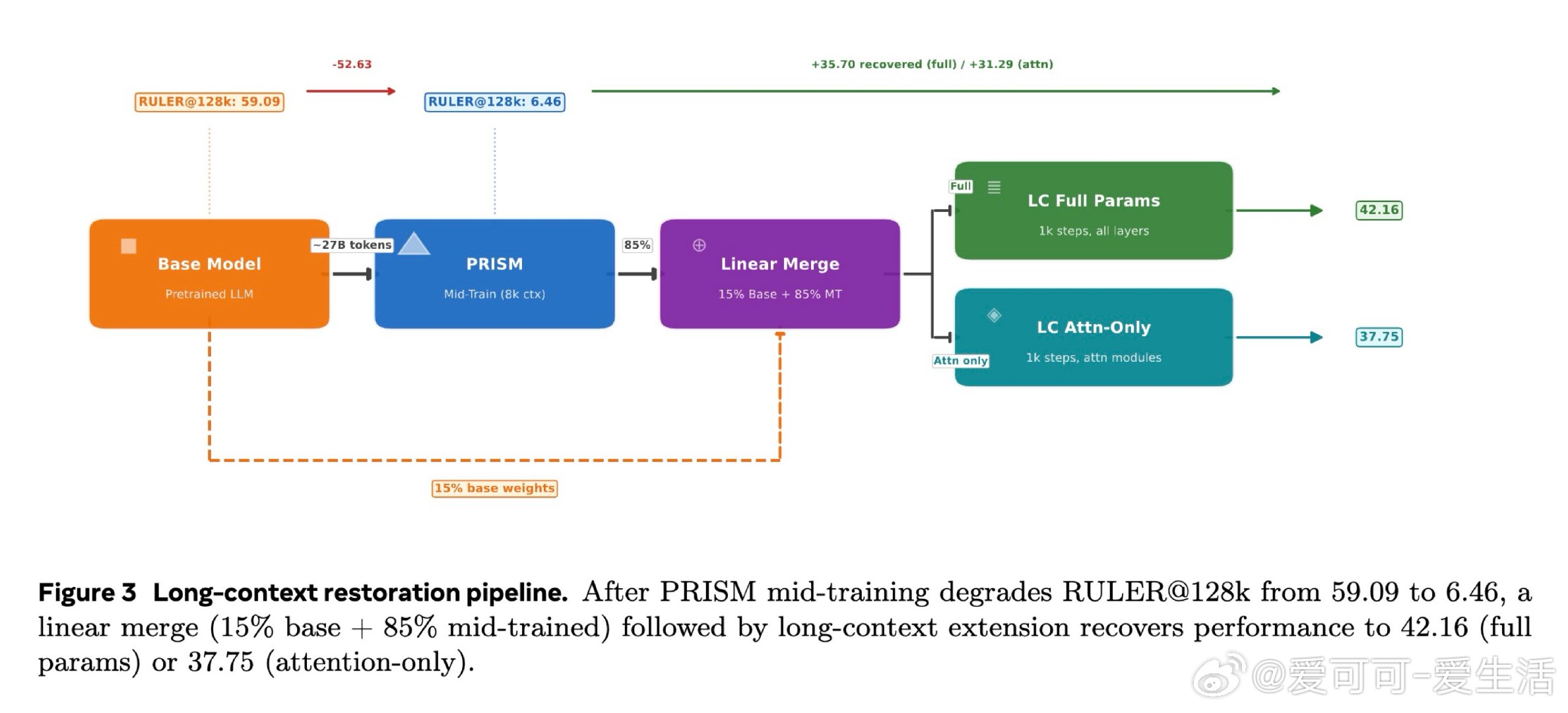
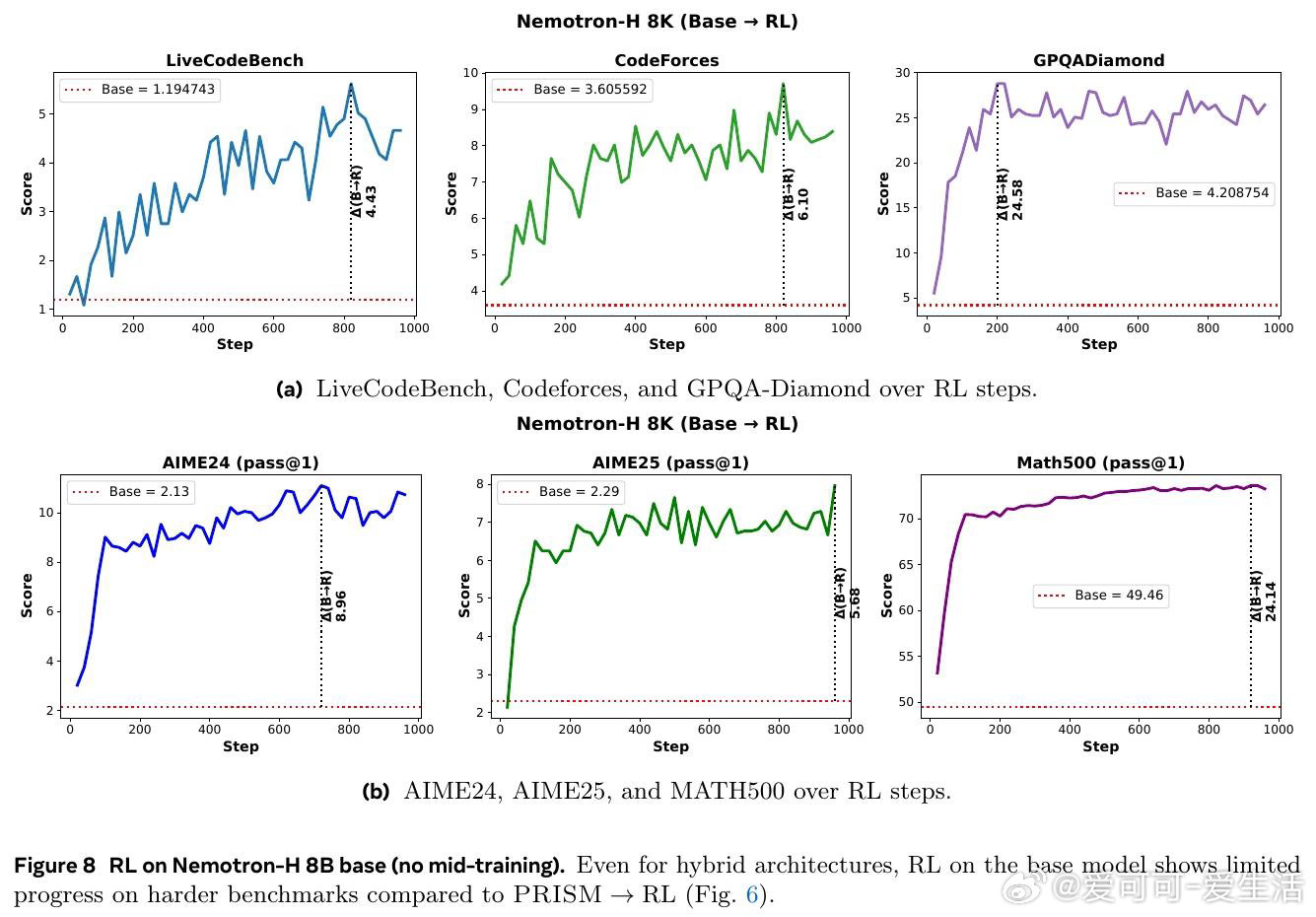
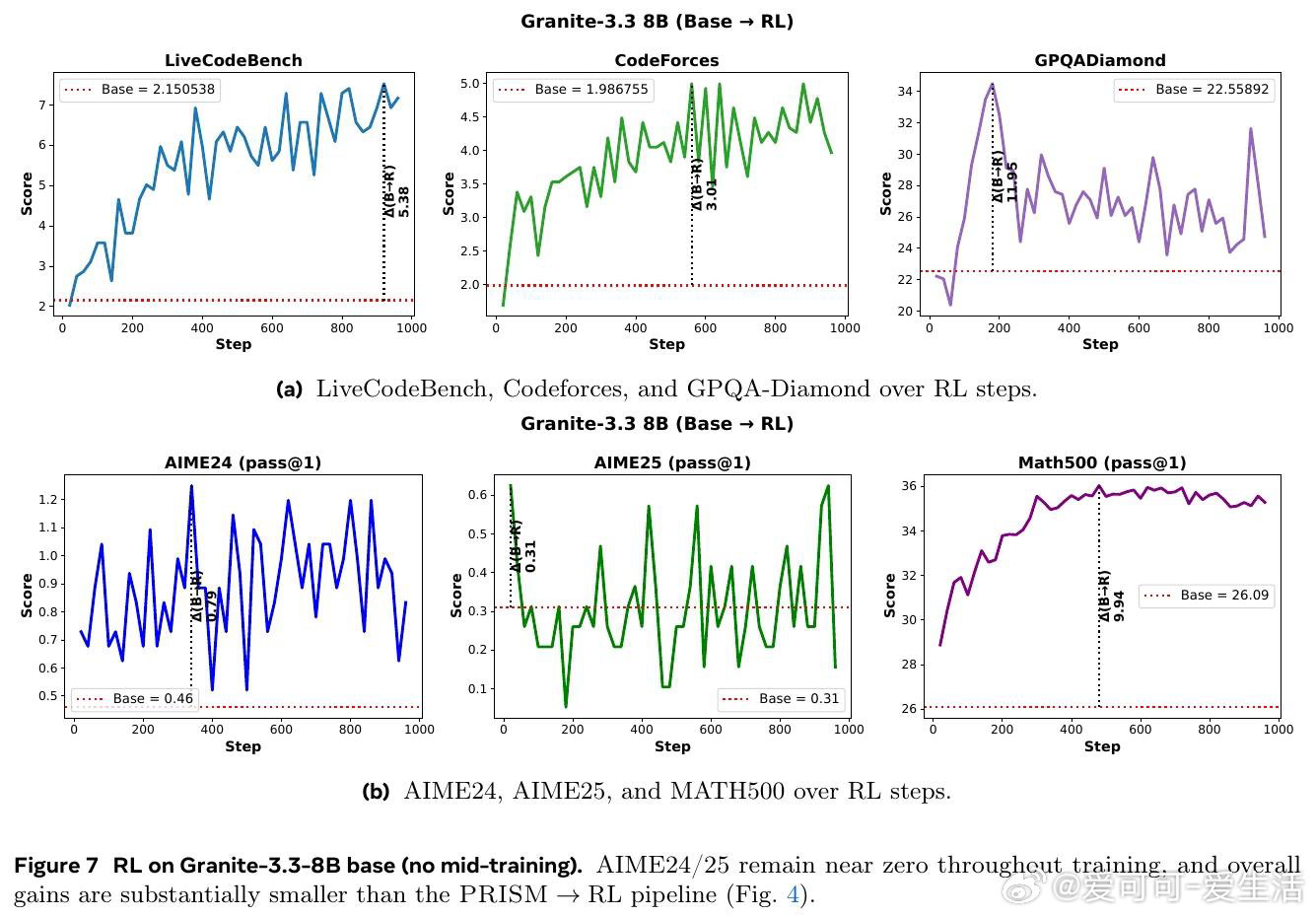
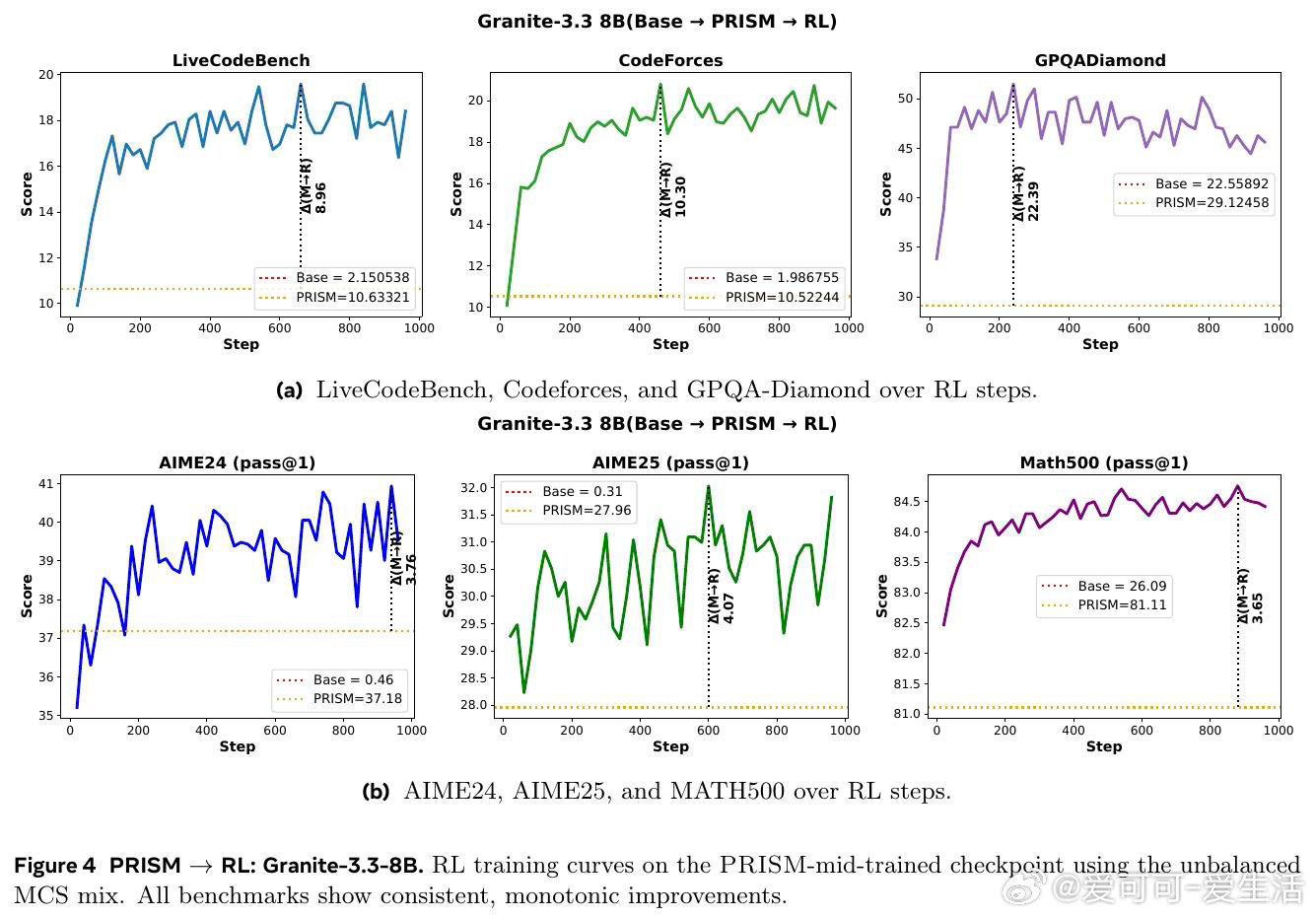
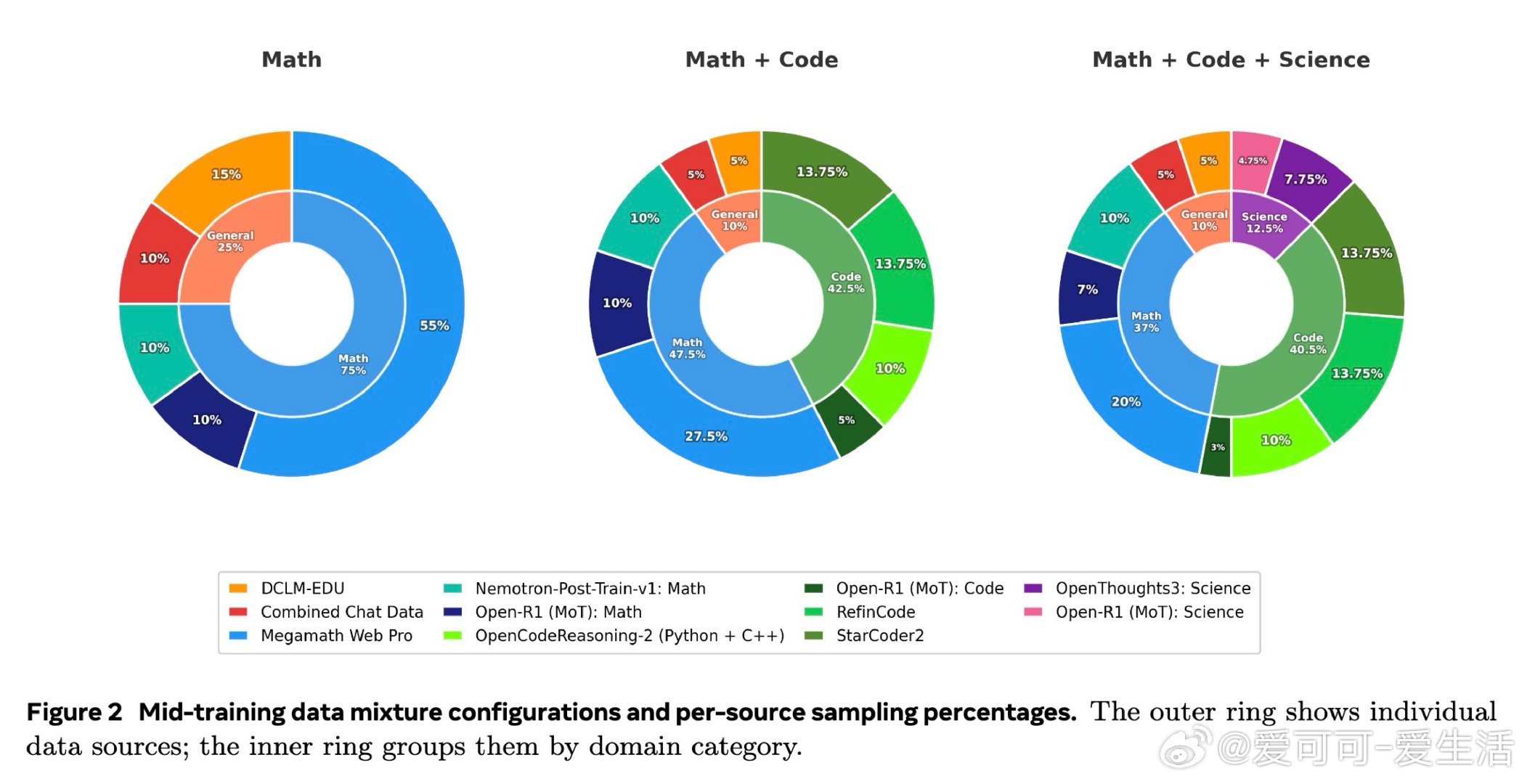
本文的核心洞见是:把中间训练阶段重新看作一次「表征地形塑造」——它不是在微调能力,而是在为RL预先构建一片可供攀登的地形。由此,一个关键发现使问题得以解开:中间训练对超过90%的模型参数进行了大幅重构,而随后的RL仅对约5%的参数做出稀疏调整,且无论是否经历中间训练,RL施加的权重变化模式几乎完全相同——却只有在中间训练之后,RL才真正奏效。数据组合(而非数据量)决定了这片地形的形状:在中间训练时加入科学数据,可在后续RL中额外解锁17至28分的科学推理增益;而仅改变RL阶段的数据配比,差异不足2分。
这项工作真正留下的遗产是:将「中间训练」从一个模糊的工程经验,升格为可被机制性理解和设计的训练阶段。它为后来者打开的新门是:通过中间训练的数据配方来预先规划模型的RL可塑性,以及跨架构(含Mamba混合架构)推广这一范式的可能性。但尚未跨过的门槛是:研究规模仅止步于24B参数,所有RL提示的难度过滤均依赖单一模型完成,距离自适应、模型感知的训练流水线设计仍有距离。
arxiv.org/abs/2603.17074
机器学习 人工智能 论文 AI创造营