[CL]《How do LLMs Compute Verbal Confidence》D Kumaran, A Conmy, F Barbero, S Osindero… [Google DeepMind] (2026)
在语言模型置信度领域,一个悬而未决的难题是:当模型被要求口头报告自信程度时,这个数字究竟从何而来?过去的研究停留在行为层面,无法区分模型是实时拼凑置信度,还是早已悄悄算好、等待被调取——更无从判断它究竟在读取生成流畅度,还是在进行更深层的自我评估。
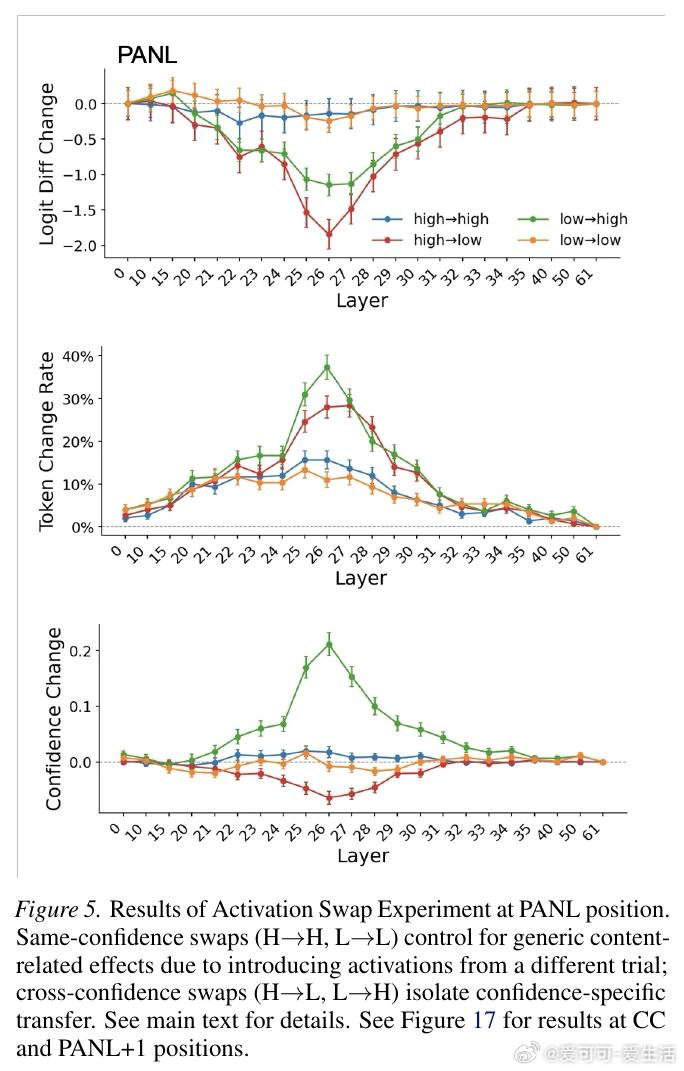
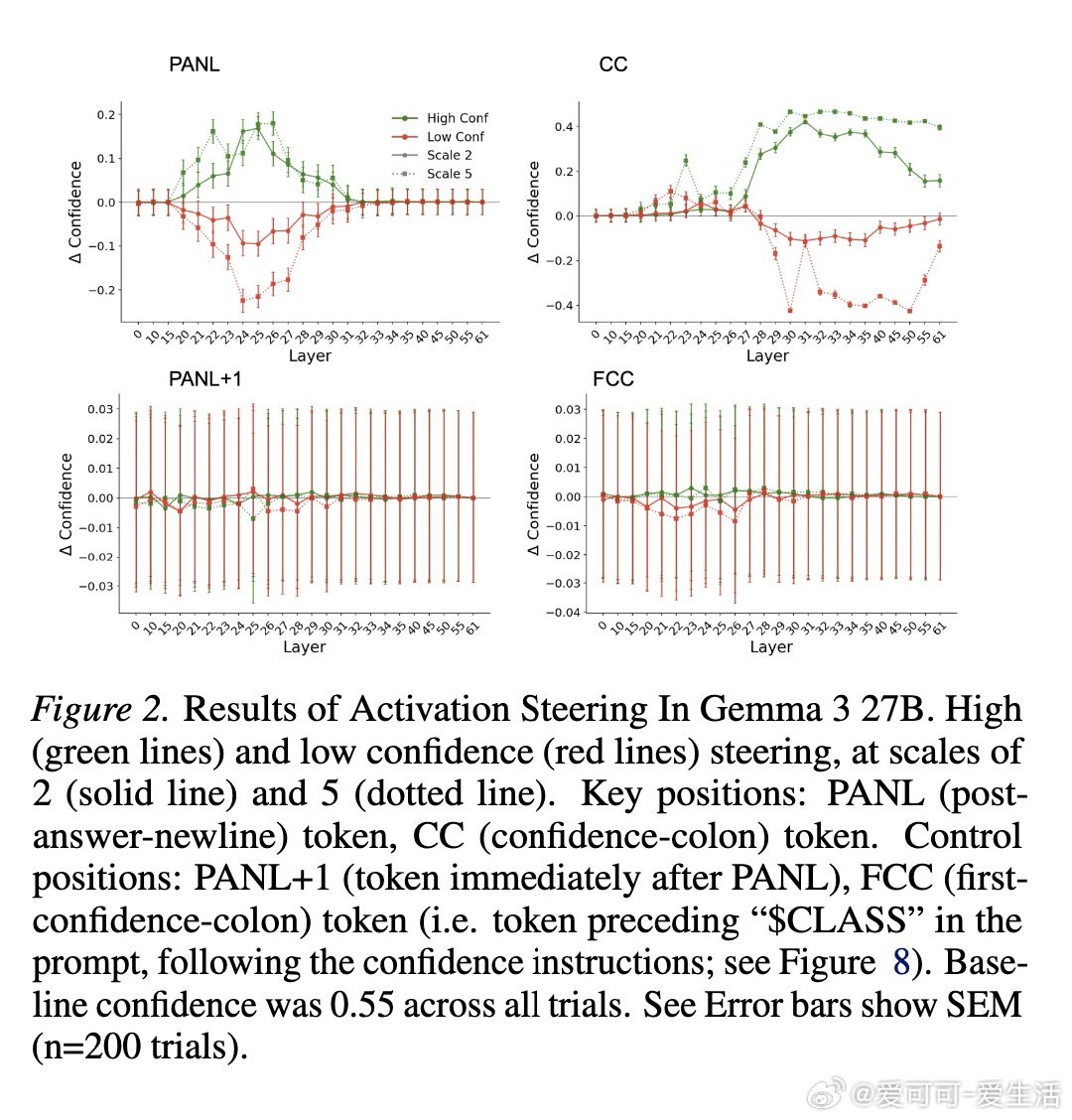
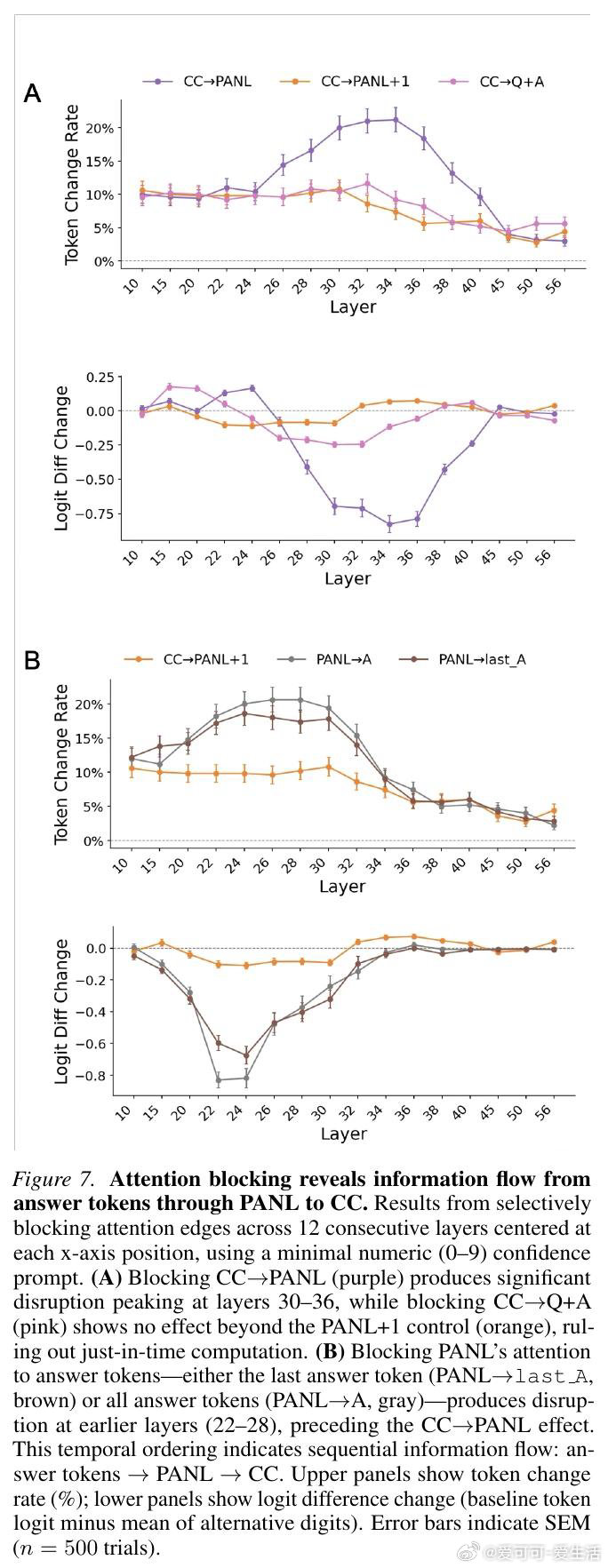
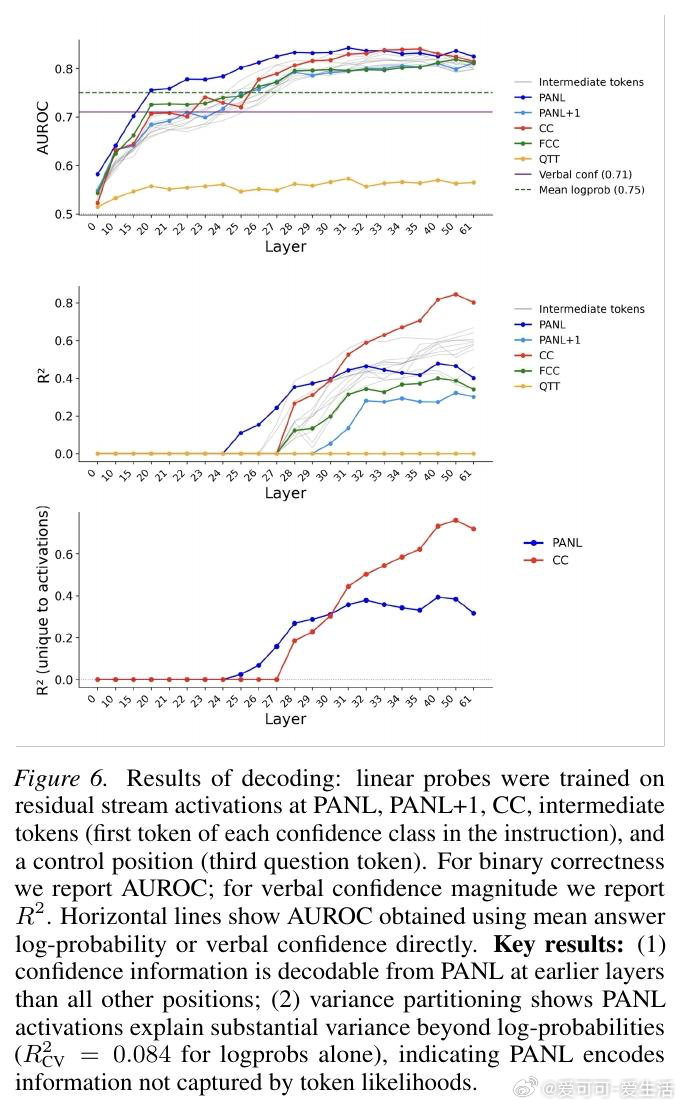
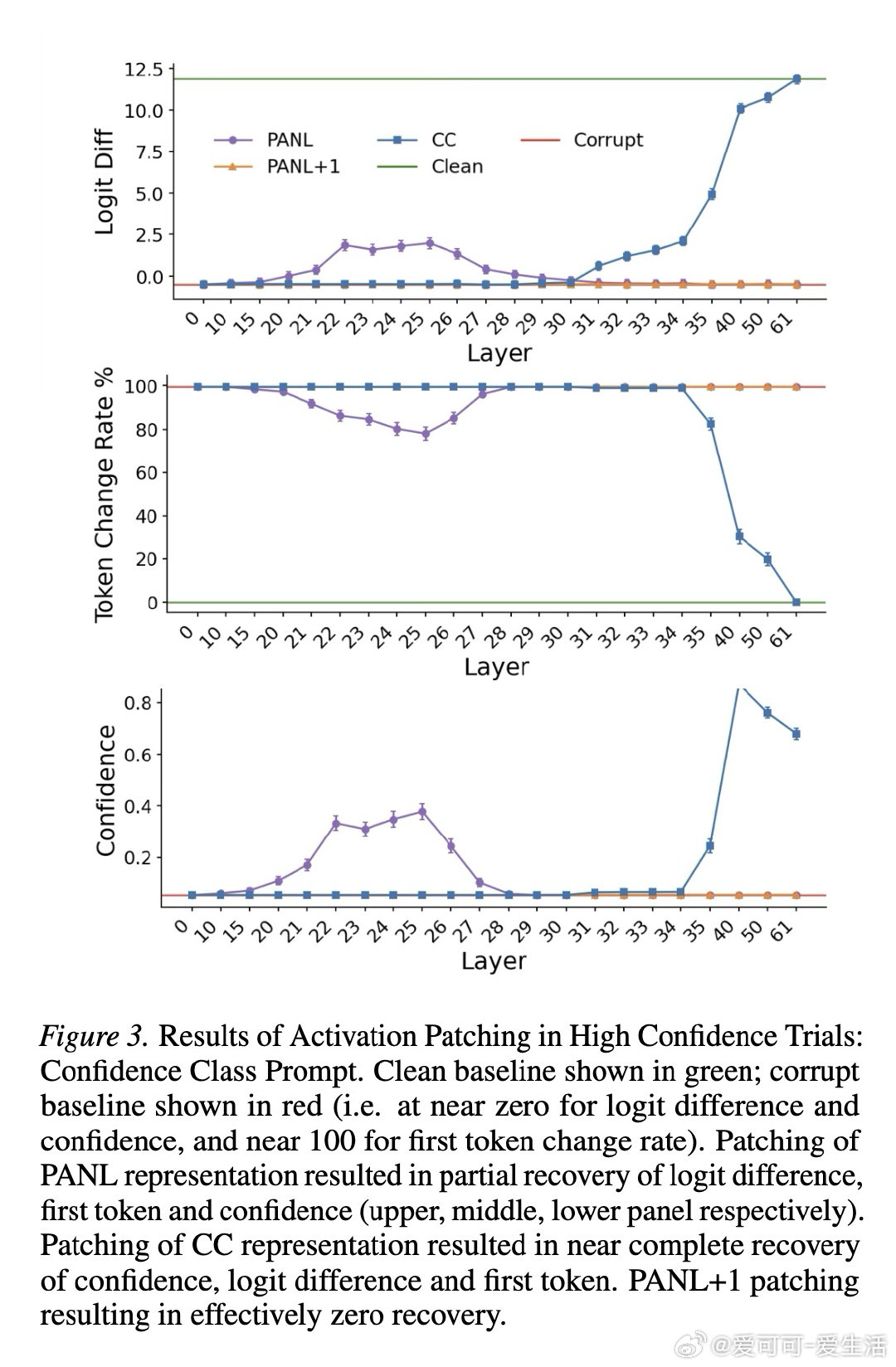
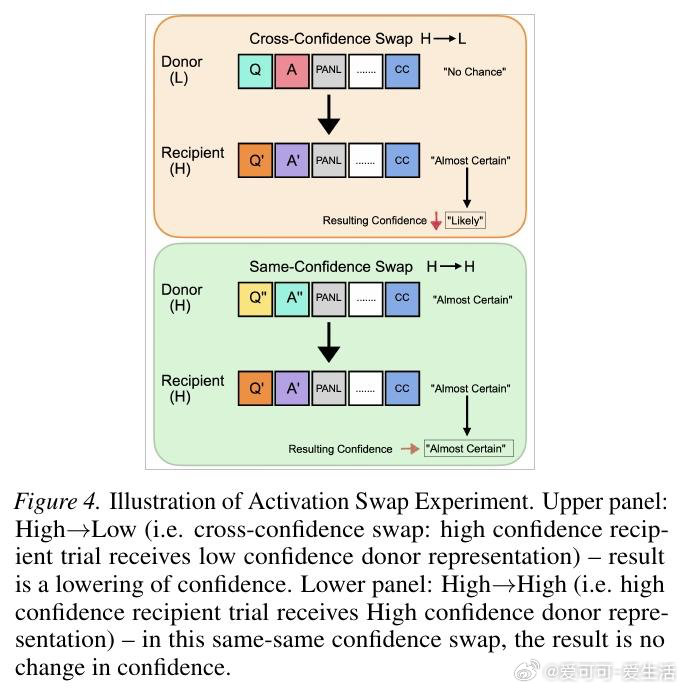
本文的核心洞见是:把置信度的生成重新看作一种自动缓存—检索机制,而非即时计算。由此,通过激活引导、因果修补、注意力阻断等一系列干预实验,研究者追踪到置信度表征在答案结束后的换行符位置(PANL)便已成形,随后被信心冒号位置(CC)调取输出。更关键的是,方差分解显示这些表征所携带的信息,远超token对数概率所能解释的范围。
这项工作真正留下的遗产是:首次用机械可解释性方法,将LLM的元认知能力定位到具体的信息流路径上,为"模型是否真正理解自身的答案质量"提供了肯定性的电路级证据。它为后来者打开的新门是:基于这条缓存路径进行定向干预,有望实现比提示工程更精准的校准优化。但尚未跨过的门槛是:实验仅覆盖事实问答且抑制了思维链,置信度缓存机制在推理模型与开放生成场景中是否同样成立,仍是未解之问。
arxiv.org/abs/2603.17839
机器学习 人工智能 论文 AI创造营