【大模型遗忘之谜:SFT、RL 与 OPD 的本质差异解析】
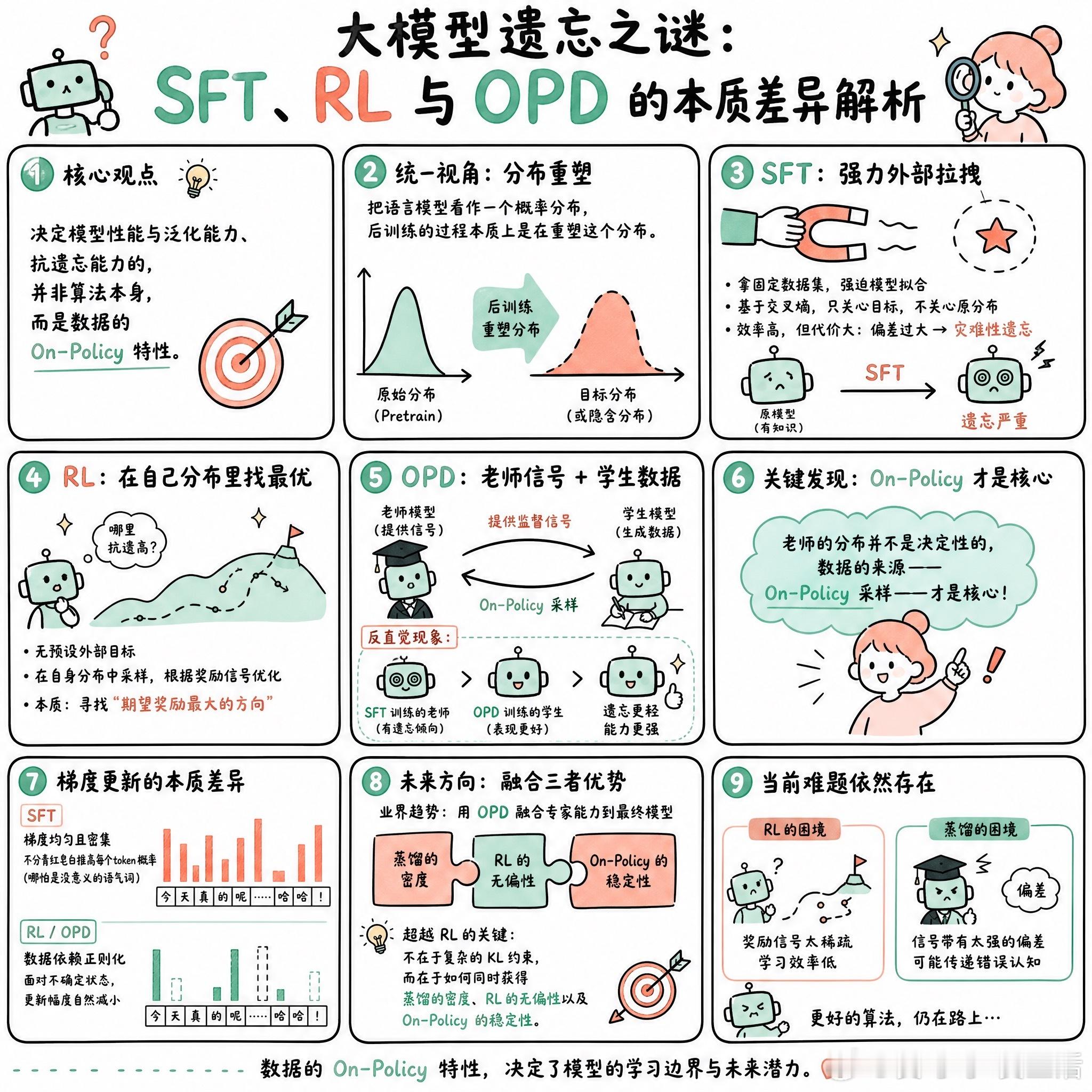
快速阅读:本文通过分布视角重新审视了 SFT、RL 与 On-Policy Distillation (OPD) 的本质区别。核心观点认为,决定模型性能与泛化能力、抗遗忘能力的,并非算法本身,而是数据的 On-Policy 特性。
如果我们把语言模型看作一个概率分布,后训练的过程本质上是在重塑这个分布。
SFT 就像是一个强力的外部拉力。它拿着一份现成的、固定的数据集,强迫模型去拟合。因为它是基于交叉熵的,模型并不关心自己原本的分布是什么,只要目标在那里,它就会拼命往那边靠。这种“直接拉拽”虽然效率高,但代价很大:一旦目标分布与原分布偏差过大,模型就会发生灾难性遗忘,因为它失去了对原有知识的保护。
RL 则完全不同。它没有预设的外部目标,而是让模型在自己的分布里采样,根据奖励函数的方向进行优化。这种方式更像是寻找“期望奖励最大的方向”。
有意思的地方在于 OPD。它处于两者之间:既有老师提供的信号,数据又是学生自己生成的。实验发现一个反直觉的现象:即便老师是用 SFT 练出来的、带有遗忘倾向的模型,通过 OPD 训练出来的学生,竟然比老师本身表现得更好,且遗忘程度更轻。
这说明老师的分布并不是决定性的,数据的来源——即 On-Policy 采样——才是核心。
SFT 的梯度是均匀且密集的,它不分青红皂白地推高每一个 token 的概率,哪怕是那些没意义的语气词。而 RL 或 OPD 具有某种天然的“数据依赖正则化”。当模型面对不确定的状态时,更新幅度会自然减小。
目前业界正趋向于将专家能力通过 OPD 融合进最终模型。如果我们要寻找超越 RL 的更优算法,关键不在于复杂的 KL 约束,而在于如何同时获得蒸馏的密度、RL 的无偏性以及 On-Policy 的稳定性。
目前的难题依然存在:奖励信号要么太稀疏(RL),要么带有太强的偏差(蒸馏)。
x.com/nrehiew_/status/2053482349300797526