【AI 交互升级:文本→Markdown→HTML 的演进逻辑】
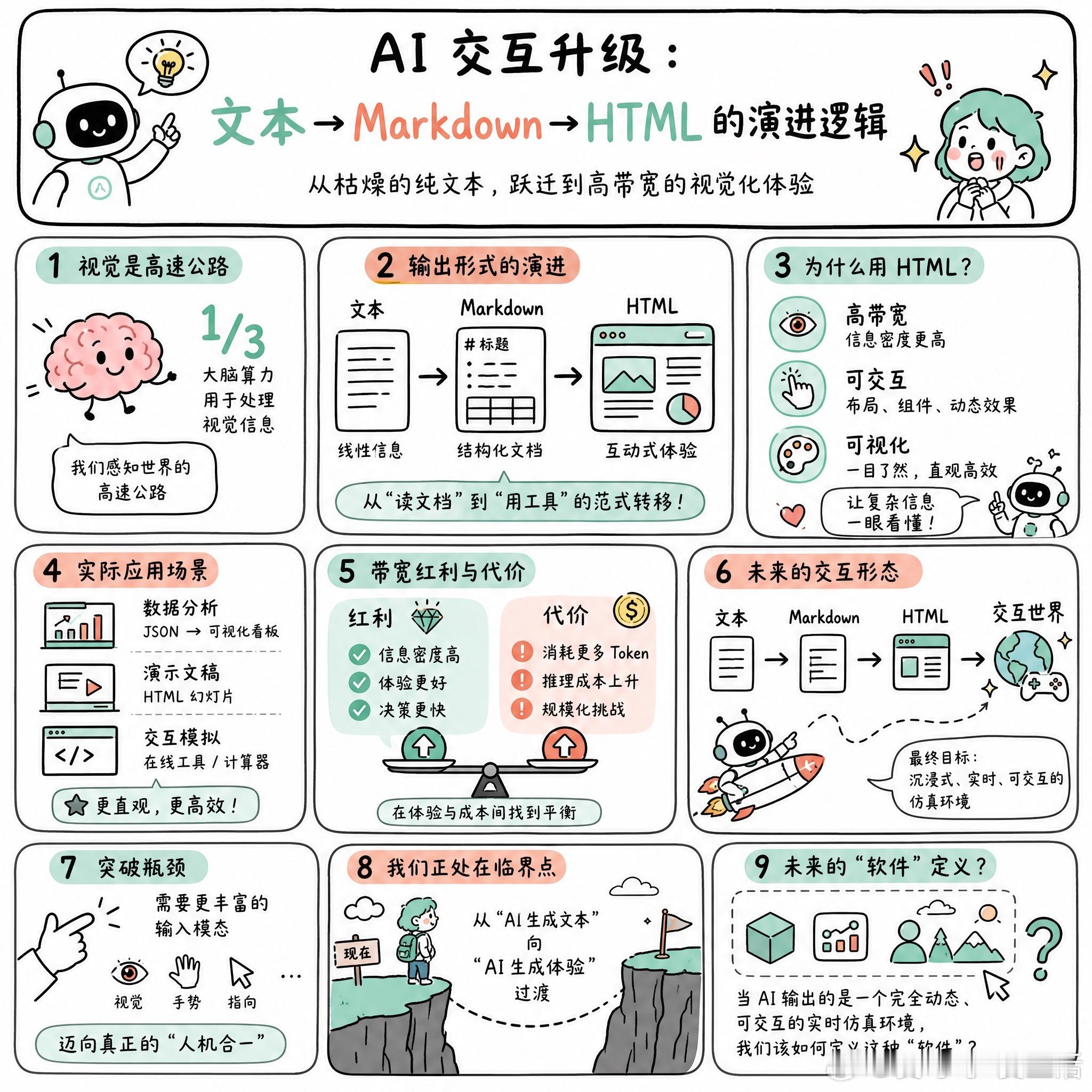
快速阅读:AI 的输出正在从枯燥的纯文本向高带宽的视觉化形式演进。通过要求 LLM 输出 HTML 格式,可以将原本难以消化的信息转化为具备交互性、布局感和视觉直观性的“体验”,完成从“读文档”到“用工具”的范式转移。
人类大脑约有三分之一的算力在处理视觉信息,这是我们感知世界的高速公路。目前的 AI 交互大多停留在 Markdown 阶段,这种方式虽然比纯文本好读,但本质上还是在处理线性逻辑。
有个很有意思的窍门:在提问末尾加一句“请用 HTML 结构化你的回答”,然后直接在浏览器里打开生成的代码。你会发现,原本一堵厚重的文字墙,瞬间变成了带有标题、表格、甚至交互组件的仪表盘。
这种转变不仅仅是视觉上的优化,更是带宽的飞跃。有网友提到,这种方式能让复杂的 JSON 数据分析直接变成一个直观的可视化看板;也有人发现,让 AI 生成 HTML 幻灯片或交互式模拟,比反复阅读说明书要高效得多。
这种演进路径很清晰:从原始文本,到 Markdown,再到 HTML,最终可能会走向由扩散模型驱动的交互式视频或模拟环境。
当然,这种“带宽红利”是有代价的。HTML 会消耗更多的 Token,直接拉高了推理成本。如果单纯为了视觉效果而牺牲经济性,在规模化应用时会面临挑战。
目前的瓶颈在于,我们还需要更丰富的输入模态,比如结合手势或指向性动作,才能实现真正的“人机合一”。我们正处于从“AI 生成文本”向“AI 生成体验”过渡的临界点。
如果未来 AI 输出的是一个完全动态、可交互的实时仿真环境,我们该如何定义这种“软件”?
x.com/karpathy/status/2053872850101285137