学习AI模型常常需要翻阅各种教程,有的过于浅显只教调用API,有的学术论文密密麻麻公式看不懂,来回切换效率低下。
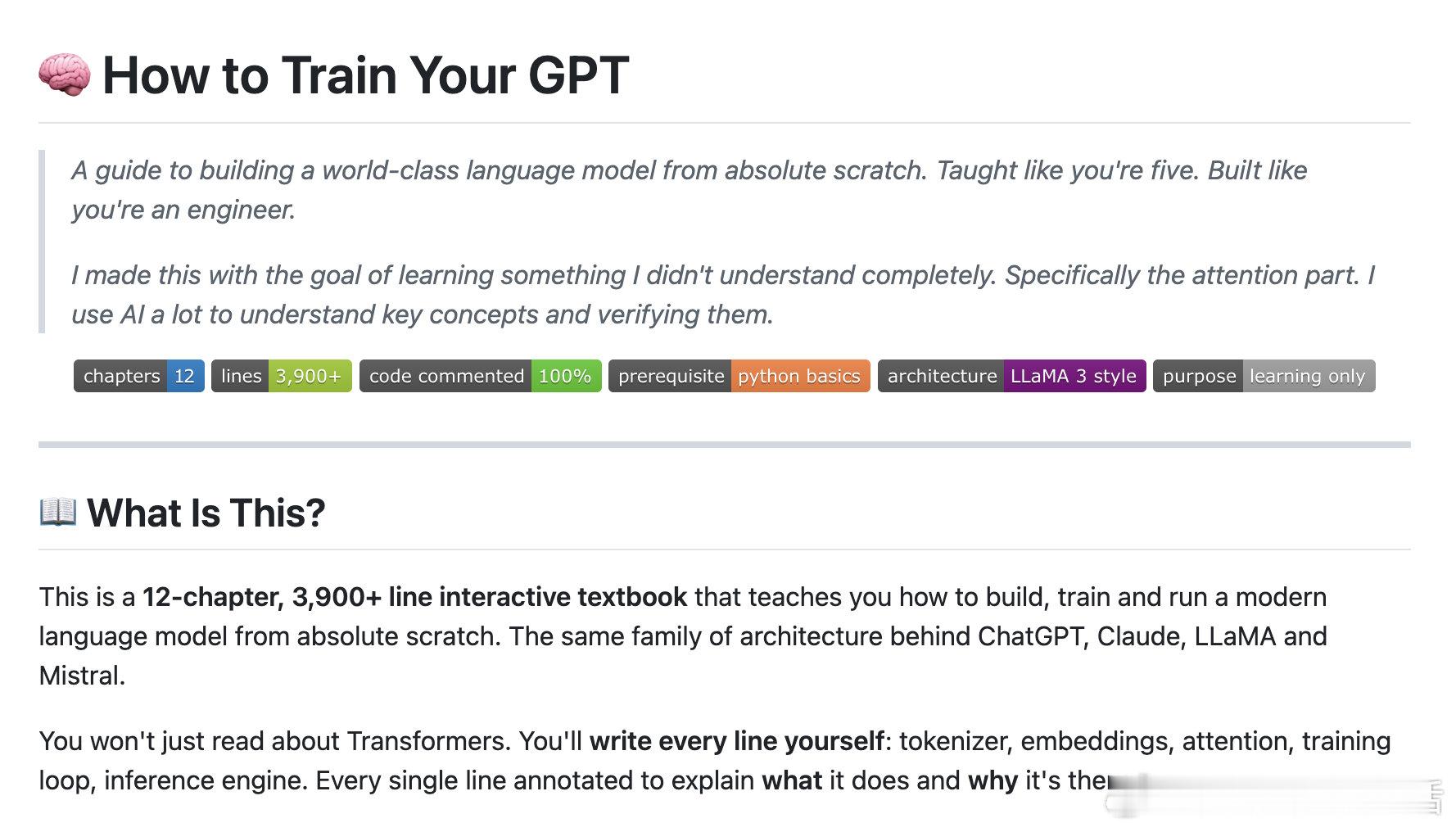
How to Train Your GPT 把从零构建现代LLM的全过程整合到一起,提供了一套零ML基础也能掌握GPT的互动教科书。
不仅有12章逐行注释代码(3900+行),用“五岁小孩”比喻讲解Transformer核心,还包含Jupyter Notebook实时运行、完整训练管道,甚至支持从BPE分词到KV缓存推理的全流程。
GitHub:github.com/raiyanyahya/how-to-train-your-gpt
主要功能:
- 零基础互动教程,支持BPE分词、嵌入、RoPE位置编码、注意力机制等逐行实现;- 完整GPT模型构建(151M参数),采用LLaMA式架构:RMSNorm、SwiGLU、Pre-Norm;- 自定义训练管道,包括AdamW优化器、余弦预热、混合精度和梯度累积;- 高级推理引擎,支持KV缓存、温度采样、top-k/p、beam search和重复惩罚;- 配套Jupyter Notebook,每章独立运行,CPU几分钟看模型训练全过程;- 支持实验扩展,如Flash Attention、LoRA微调、MoE等生产级优化。
支持Python环境快速启动(pip install torch tiktoken),Web阅读章节+本地运行Notebook,适合Python开发者、学生和工程师自学LLM原理。
AI创造营大语言模型Transformer