当去年底、今年初一场密集的“国产AI芯片IPO”潮成为冲击行业的巨浪,一个看似朴素的问题被反复拷问——国产 AI 计算芯片,到底行不行?到底能否支棱起来?
答案并不在发布会的灯光里,也不在 PPT 的曲线里,而在更残酷的地方:有没有真实客户在买、有没有真实业务在跑、有没有真实工程团队愿意把自己的 KPI 绑定在这颗芯片上。
从这个意义上讲,天数智芯最近这一轮对外释放的信息,之所以硬到了有些“刺眼”的程度,不是因为它把PPT做得够漂亮,而是因为它做了一件在芯片圈里并不常见的事——直接把“硬通货”摆在桌面上:四代架构路线图、云边端产品矩阵,以及一摞能落到业务指标上的落地战绩。
这是不是意味着国产 AI 计算芯片终于摆脱了“技术薄弱、商业化不足”的短板?
要判断这句话能不能成立,必须回到两个维度:核心技术成熟度与商业化能力跨越度。
前者决定你能不能进入牌桌,后者决定你能不能留在牌桌。
——导语
01
三剑齐发:架构、产品、落地,全是硬通货
谈一家 AI 芯片公司是否“支棱起来”,第一眼,还是要看产品力。
但产品力从来不是单点指标,而是一整套“技术—产品—市场”的闭环。我把它概括为——架构路线清晰且能兑现、产品矩阵能覆盖关键场景、落地数据能证明工程可靠性。
天数智芯这次的“组合拳”,恰恰把这三件事同时做了。
首先,说件极为反常的事,天数智芯这次上来直接亮底牌——公布了从今往后的四代架构路线图。
说实话,环顾全球半导体行业,我还想不出有哪家巨头是这样做过的。因为摩尔定律的存在和激烈的竞争,发布一代——预研一代——预测一代已经是行业习惯,“四世同堂”则极为少见。
甚至,由于制程的极限将至,以及竞争的激烈。这几年,巨头临阵改芯片的例子也不少见——比如苹果去年就没有跟着M5处理器的发布而同时发布M5 Pro和M5 Ultra版。原因很简单,AI竞争太激烈,苹果可能面临“要么拿出新的AI处理器单元,要么硬连接两块M5 PRO芯片充当Ultra”的局面。
对天数智芯来说,“公开路线图”不仅是一种反常识的勇气。还意味着它愿意接受三重审视:
你要对标谁? 你打算什么时候追上? 你准备靠什么追上?
太多的公司不敢把未来讲得太细,道理也很现实——除了防友商一道,更难面对的是市场的期待——因为路线图一旦公开,世界就会用结果来结算你的承诺。
可是天数智芯就是这么“刚”,它做了一个完全相反的选择:把从现在到未来的四代通用 GPU 架构节奏直接摆出来,并把对标对象写得非常明确——从 Hopper 到 Blackwell,再到 Rubin,最后形成自己的“大杀器”。这虽然不意味着目标彻底固化,但至少已经有清晰的时间表与目标梯队。

你可以不认同它的“超越叙事”,你甚至会觉得“这是不是作秀?”,但你很难否认它的一个姿态——它的选择,已经把自己放在了“工程兑现”的考场里,围观的是全球的AI业,至少也是中国的AI业。
让人还觉得靠谱的是,这条路线图不是悬空的。它是过去7 年全栈积累之下的喷薄而出,是国内首家通用 GPU 设计持续迭代到 4 代产品后的对未来的展望。所以,这个路线图,除了技术上展现的坚定决心,本质上也凸显了一件事——通用 GPU 的最难的事,不在一颗芯片,而在“系统工程”里。
而这个系统工程的建设,天数智芯用取得的已有成就,在招股书里做了实实在在的回答——国产全栈技术的GPU,不但出现了,还取得了一定的商业成功,更有了对标世界第一号对手的决心和未来路径。
通用 GPU 这条路为什么难?因为它的竞争点,不是做出一个能跑浮点运算的芯片,而是“做出一套能在真实世界里长期演进的算力体系”。
这在技术上首先就是极底层的,它涉及到指令集、编译器、算子库、框架适配等等,这里面全是苦活,也不乏可以绕过去的“近路”,但天数智芯非要“缺一不可”。这只能被认为是——它准备在未来最极限、最孤立的情况下,打一场硬仗。
同时值得关注的,是集群的规模。千卡集群可能没有万卡大集群那么性感,但难得的是集群的稳定性、通信的可靠性、性能的可预期——它已经在科研场景中得到了证实。
当然,真实的挑战还更多,交付客户后会有无数的具体挑战——训练、推理、混合精度、注意力机制、长上下文……每一家公司的大模型都会逼迫你,要你重新证明自己。
之所以讲这么多,还是一个意思——一家通用 GPU 公司真正的底气,不是某一项指标,而是“能否在多轮迭代中持续把系统补齐”。而天数智芯把“全栈、可优化、可迭代、未来可期”写在材料里、画在架构图里,本质上就是在强调:“我不是来这个舞台上匆匆走一遭,我希望陪我的客户一起进化,十年、二十年、很多年”。
如果说通用 GPU 的主战场在数据中心,那么过去很长一段时间里,国产算力更大的短板其实在“边端”——不是做不出芯片,而是做不出又强、又稳、又便于规模化复制的边端算力形态。
很多边端 AI 芯片陷入一个尴尬:参数很美,但适配很难;demo 能跑,但批量上线很难;小批量能交付,大规模交付很困难。
所以,天数智芯的“彤央”系列的发布之所以值得重点写,是因为它不是“多做了几块板子”,而是直接把边端算力当成自身的第二增长曲线,来做了系统化的发展布局:四款产品覆盖不同形态、不同性能档位与不同落地场景。

材料非常具体,但我们这里只能略略谈到其中的不同——彤央TY1000主打远端 AI 算力模块,8核心的精简指令集架构,体积做到“口袋大小”级别;而彤央TY1100_NX的算力适中,但提供更大存储配置(材料中给出 32/64GB 级别选项)与更偏工业的设备形态;彤央 TY1200,同为远端 AI 算力模块,核心升级到16核心,算力是此次系列中最大的。
这一组芯片的发布,传递的信号非常明确:天数智芯不是在边端“试水”,而是打算“立体作战”,提供“边端全家桶”。
但说实话,作为一个行业研究者,我最好奇的是,彤央代表的国产边端芯片,到底能不能打过 AGX Orin 这种事实标准?
对这个问题,天数智芯直接把硬核数据推给我——在计算机视觉、自然语言处理/语音任务,以及 DS-R1-32B、VLA等更接近大模型推理的负载中,TY1000 对 AGX Orin 体现出多项任务的优势倍数(例如在若干任务上为1.7×、1.8×、1.9×,以及某些 VLA 相关项达到 3.7× 的量级;同时也给出 TTFT、TPS 等更贴近推理体验的指标对照)。
这组对比的意义,不在于某一个柱状图,而在于它明确把竞争拉回到了工程师真正关心的问题上——不是只比峰值 TOPS,而是比真实任务上的吞吐、首 token 延迟,以及负载覆盖面。这才是边端落地的关键。
如果说“路线图”代表愿景,“产品矩阵”代表能力,那么“落地数据”才代表真实世界的回馈。
最值得反复琢磨的,是这样一组涉及“商业化规模”的数字:300+ 采购用户、1000+ 联合开发案例、覆盖互联网、运营商、金融、医疗、交通、制造等多个行业场景。
这些数据,和国际巨头还是比不了,但在国产阵营里,足够优秀。
这是因为,在国产芯片行业,最大的分界线往往不是做没做出来样片,而是“有没有跨过规模化落地的死亡门槛”。虽然从 0 到 1 的 demo 最容易让人兴奋起来,但从 1 到 100、从 100 到 10000,才会暴露真正的商业化竞争力,它会考核无数具体的细节——兼容性、稳定性、驱动与编译器成熟度、算子库与框架适配效率、客户现场支持能力乃至供应链与交付节奏。
所以,我认为,这组数据中,“1000+ 联合开发案例”这句话,含金量是最高的——它意味着天数智芯不是在卖“芯片”,而是在卖“共同完成交付”的能力。更直白一点说就是:已经有1000个以上的客户愿意跟天数智芯一起踩坑,还愿意和它一起把坑填完。
在半导体行业,这是一种非常昂贵的信任。
02
算力要实在,生态要敞开
天数智芯的核心价值,如果只用一句话概括,不是“国产替代”,而是它试图把国产算力从“能用”推进到“好用”。而要理解“好用”,必须先理解所谓“算力荒”的真相。
算力荒的本质不是“缺芯片”,而是“缺高质量算力”。
过去两年,很多人把算力荒简单理解为“买不到 NV卡”。但真实世界里,即便你能买到NVIDIA,你依然可能陷入算力荒。原因非常现实:模型、负载与商业化形态变了。
当大模型仍停留在实验室阶段,性能差一点、适配慢一点、能效低一点、运维复杂一点,问题都不显著。因为实验室研发团队的容错率,天然就是极高的。
但当 AI 进入生产力系统,问题就不再是“能不能跑”,而是算力利用率能不能稳定在高位?每token 成本能不能算得清、降得下? 新模型上线能不能快速适配?千卡乃至万卡集群能不能长期稳定运行,而不是因为通信问题,崩一次就停摆。
天数智芯“刚”得可爱,它直接在核心材料里自问自答“什么是好用的 GPU?”,并给出三个关键词:高性能、性价比、广生态。
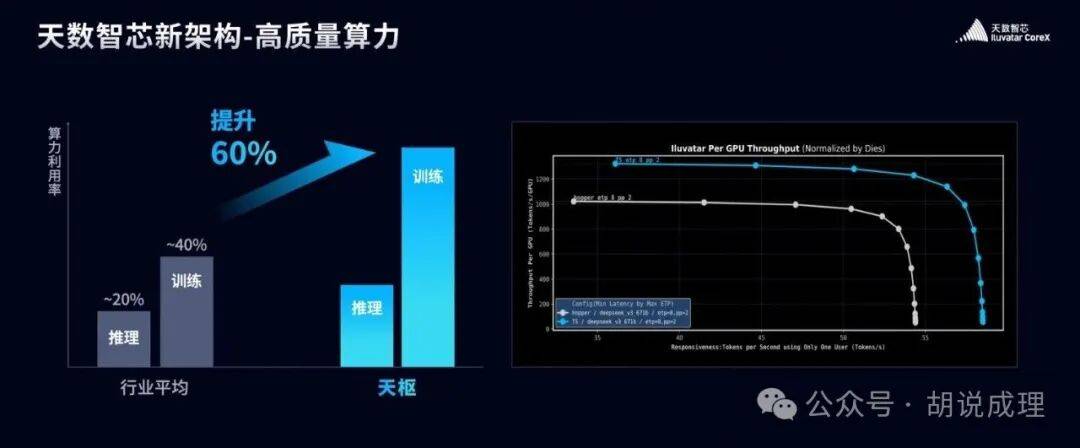
这三点,恰好对应了“高质量算力”的三个层次:
高性能:不单纯是峰值性能,而是复杂负载下的稳定吞吐;
性价比:不仅是硬件价格,更是 TCO(总拥有成本);
广生态:决定迁移成本与上线速度,决定你有多少可以立即复用的优质资源和前人成果。
天数智芯的回答也很直接,针对目前最典型的互联网用户的常见场景,它给出了三个核心指标:
单机性能 2×、token 成本降低到 1/2、人力节省 1/3。

这组数据为什么重要?因为它不是芯片公司的“自嗨式指标”,而是客户能直接写进自身财报的指标。尤其是 token 成本,它已经逐渐成为 AI 商业化的“度量衡”——无论是大模型 API、内部 Copilot、还是 Agent 系统,最终都会被 token 成本追着问责。
更现实的点是,人力节省 1/3 往往比硬件便宜更有杀伤力。因为很多客户不是不愿意买国产芯片,而是不愿意为迁移付出单开一个工程团队+三个月过渡期的适配代价。天数智芯把“人力节省”放到与性能、成本同级的位置,本质上是在承认一个事实:生态与工程效率才是真正的战场。
很多国产芯片公司在公开场合,对于“适配”这个话题是既恨且爱——因为适配听起来像“苦活”,但你要想真的在产业里活下来,适配才是决定生死的指标。
天数智芯的材料里,则对于大模型适配给出了非常具体的数字表达:
Day-0 适配:新模型适配提速 50%
3000+ 基础算子
100+ 定制算子积累
150+ 深度优化在途
95% 算子复用率
这区区5行字,背后其实是一个极其重要的行业趋势:模型更新速度,已经快到“适配速度”本身变成了一种竞争力。
过去的“百模大战”时期,你可以用半年适配一个模型,因为模型生命周期相对长,容得下仔细打磨。可今天如果用半年适配,对手的模型可能已经迭代三次。
同时,对于更多的不具备开发基础大模型的应用型AI企业来说,更是身处于“开源模型爆发 + 私有化部署”带来的长尾队列里:客户要跑的不仅是 Llama/Qwen/DeepSeek,还包括各种蒸馏、剪枝、量化、MoE/SSM 混合,以及行业微调版本。
所以,“Day-0”意味着什么?意味着客户看到新模型发布的那一天,你就能快速把它跑起来,哪怕先以可用为主,随后再通过深度优化,把性能榨到更高。事实上,这种节奏,才适配今天的模型生态,才是无数应用型开发企业活得更久的关键。
“95% 算子复用率”则尤为关键。它暗示天数智芯在算子与编译层面,已经形成一种可迁移的工程资产:你适配一个模型,不是从零开始,而是在既有算子图、融合策略与内核实现上做增量。这会把适配这种苦活,从“手工艺”变成“准工业化”,而几年前,它还是一种梦想。
在天数智芯的材料里,有一页我印象极深——这张图,把生态画得非常“满”:从 CPU、NIC、存储、OS、编译器、框架到模型与应用伙伴,强调“芯片是下限,生态是上限”。
这句话放在今天尤其有现实意义,因为 NVIDIA 的真正护城河从来不是某一代 GPU 的峰值算力,而是 CUDA 生态。一个软件栈成熟、工具链完善、开发者规模庞大的生态,会把客户牢牢锁在上面:不是因为迁移不可能,而是因为迁移太贵、迁移隐性成本高到无法计算。
也许你会说,可以自研软件栈。但我认为天数智芯的选择,也就是软件栈上的“短期兼容、长期自主,才是一种终极智慧——短期可以降低迁移成本,提升商业化效率;长期逐渐形成自己的工程文化,用无数积累形成复利优势”。
事实上,真正的潜台词也在这里:天数智芯知道自己要卖的不是某一张卡,而是一条让客户“敢换、能换、换得动”的路径。
03
行业开花,落地的含金量在“稳定与复制”
如果说生态与适配证明“能用且好用”,那么多行业落地证明的是“可复制”。而可复制的核心,不是 demo 数量,而是用出来的稳定性与规模化的交付经验。
前面说过,有一个数据含金量非常高——千卡集群稳定运行 1000 天**,并支撑 100+ 种单集群科研任务。
为什么这比“单卡跑分”更重要?因为在大模型时代,真正的痛点往往不是单卡算力,而是集群系统工程。在实践中,很多芯片公司在发布会上能展示单卡指标,但一旦进入集群环节,问题就会成倍放大:通信抖动、节点不一致、作业中断、吞吐波动……而科研与头部训练客户往往最不能忍这些。
所以,“1000+ 天稳定运行”的意义是:天数智芯在集群系统层面,已经摸到了一些“可长期运行”的工程规律,这才是最有可能转化为商业优势的差异化,因为商业客户最终必将走向集群化,只是规模可能不同。
对于我们习惯说的“千行百业”,天数智芯也有好成绩——券商研报生成效率提升70%;电子病历生成30 秒完成;电力输变电巡检实现 100% 智能分析覆盖……
这些指标的价值,不仅仅在它的行业分布广度(尽管这也很重要),更重要的是,它们在描述一种“业务闭环后”的提升,而非单点推理速度。而AI 商业化真正的关键,从来不是“模型能不能回答”,而是“业务流程能不能缩短、成本能不能下降、服务质量能不能提升”的“大闭环跑通”。
更现实一点来说,对行业客户而言,GPU从来不是“科研玩具”,而是极昂贵的硬件资产。客户不会因为你“国产”就买单,也不会因为你“跑得快”就买单。客户买单的前提是:ROI 说得清。
所以,当我看到研报生成、病历生成、巡检覆盖这种指标,我脑子里立刻浮现——这些恰恰都是 ROI 指标,甚至是KPI指标,它们意味着缩短时长、节省人力、提升覆盖、降低风险。
这更说明天数智芯的研发思路是清醒的——不过度追求单点峰值,一切以业务可闭环、效果可度量来“以终为始”地展现自己的真实力。
回到最典型的互联网大模型场景:过去大家卷“训练”,现在越来越卷“推理”。而推理的竞争,最终会回到两个字成本。
天数智芯关于“token 成本 1/2 + 人力节省 1/3”的表达,实际上暗示了天数智芯正在占据推理时代的两个关键点:第一,性能可预期,能把资源利用率拉上去;第二,迁移风险可控:能把适配与运维的人力成本压下去。
特别是当推理占比已经持续上升时,这两点的价值会尤其被放大:训练往往是“阶段性集中投入”,推理却是“长期持续消耗”。推理成本每降低 10%,就是持续性的利润改造。
不能忘记的还有边端产品的数据里,有一页非常典型:它把应用场景分成具身智能、工业智能、商业智能、交通智能四大领域,并强调“从数字世界走向物理 AI”。
这个其实让我挺惊讶,因为前面的信息总让我觉得天数智芯是一个太硬核的技术公司,但没想到它对泛智能行业的发展趋势,也了如指掌。至少它已知晓——模型能力会越来越多地被塞进现实世界的设备与流程中——机器人、生产线、门店、交通、园区、车路协同……
而这种典型边缘算力的竞争逻辑,与数据中心又明显不同:不能靠堆功耗解决问题,因为功耗极敏感;不能靠工程团队长期驻场解决问题,因为设备可能在无人区……换言之,这场考试的前提,是必须做到“部署即运行、运行即稳定、稳定即复制”。

“彤央”则展示了落地的场景化证据:例如商业智能与瑞幸门店的结合,以及交通智能中的车路协同、车道线检测、路障检测等任务形态。虽然这些案例在数据脱敏上做得很极致,有些数据我看不到,但我仍然觉得这类案例的发布很有价值,这是因为边端一旦验证,往往具备“规模复制”的天然属性:门店可以从 100 家到 1000 家,城市试点可以从 1 个到 20 个。
这说明,天数智芯已经意识到,边端才不是小市场,而是“分布式算力基础设施”的入口,而这个入口,一定要占领。
04
国产芯片逆袭,从来不是靠“同情分”
如果把今天的成绩当作结果,那么过程往往更能说明问题:国产 AI 芯片产业真正的敌人,从来不只是技术,还有“市场信任”。
我曾经亲口问天数智芯的高管一个问题——你们第一次陌生拜访客户时,客户是求贤若渴?是半信半疑?是有些“嫌弃”?
这位高管立刻回答我两个字——嫌弃。
这其实可能并不是天数智芯的问题,而是国产算力芯片还没有“支棱起来”的实证——那些“嫌弃”,可能是因为“进口的、稀缺的才是最好的”的历史肌肉记忆;但也可能是被一些国产芯片的过度承诺、交付翻车的项目伤过心;也可能是这个市场看着大,但落脚点不多的实情——好客户早被头部生态锁定,后发者空间很窄。
因此,天数智芯这样在规模、体量、资源上都不特别占优的国产通用 GPU 想打开局面,最有效的办法只有一种:用结果做背书,用工程能力反复兑现承诺。
你只要看看他们的高管的PPT里反复出现的“可优化、可迭代、可靠性”之类的词汇,就知道每个词汇可能都对应着一个现实的伤痕……而每个伤痕也对应着今天的自信——天数智芯的每一行承诺都算数,因为我们不打算靠一次发布会、一份招股书就建立信任,我们希望用户通过靠持续交付的结果,对我们建立信任。
有这种心态,对尤其是在半导体这种“赢家通吃”的行业很重要——追赶国际巨头注定是持久战,那种标定未来四代的目标的追赶尤其考验可持续能力,考验“把伤痕当作勋章”的心态,对国产厂商而言,最怕的不是速度慢一点、迭代慢一点,而是技术迭代断、生态建设断、现金流断、客户信任断。能熬过这些断点的公司,才有资格谈未来。

05
国产算力的黄金窗口期,正在从“政策驱动”走向“需求驱动”
最后,我们回到一个更宏观的判断:今天是不是国产算力的黄金时代?
如果你把 AI 产业比作一场工业革命,那么算力就是煤、电与机器。只要 AI 应用持续下沉,算力需求就不会停。而当推理需求持续上升、物理 AI 持续扩张、企业私有化部署持续加速时,国产算力的窗口期会越来越“硬”——因为它不再只靠政策“拉”,而是靠需求“推”。
在这个结构性机会面前,天数智芯的优势更清晰地体现为两个方面:技术路径的稀缺性与目标设定的强执行力。
通用 GPU 是最难的赛道,因为它不是“做芯片”,而是“做体系”。而天数智芯的策略,是把体系做得超级完整:从硬件到软件栈到生态适配,把可持续迭代变成一种能力。
材料里的“7 年全栈、4 代产品、国内首家通用 GPU 设计”等表述,之所以值得在文章里反复强调,是因为它们不是营销词,而是行业事实:能坚持把通用 GPU 体系做下去的公司,本来就几乎找不出来。
另一方面,当 AI 从“数字世界”走向“物理世界”,边缘算力就是新的基础设施。彤央系列用“模块/设备”双形态覆盖多场景,并通过对标 AGX Orin 的实测对比与行业场景展示,表达了一个非常明确的企图:在边端大算力上做国内头部。
换句话说,如果说数据中心用的GPU 决定的是“基础大模型能力”,那么边端算力决定的则是“社会级应用渗透”。这两者叠加,才是一家算力公司的真正增长曲线。
结语
国产 AI 计算芯片“支棱起来”的真正含义
所以,国产 AI 计算芯片到底支棱没支棱?
我的判断是:如果“支棱起来”意味着进入可以被严肃对标、被真实选择、被工程验证的阶段,那么天数智芯这类公司,确实正在把国产算力从“备选方案”推向“可用答案”。
它的路线图未必都能在每个节点兑现,它也不可能在短期内撼动 NVIDIA 的全球统治——这点必须保持清醒。但它已经做到了很多国产芯片公司做不到的事:
——公开对标,接受结果结算;
——云边端补齐,瞄准未来结构性机会;
——用一串串实证数据来证实自己;
更重要的是,它把国产算力竞争从“情绪叙事”拉回到“工程叙事”。这才是产业真正成熟的标志:不靠口号生存,靠交付与效率生存。
国产 AI 计算芯片的黄金时代回来,但那天,同样竞争会很残酷,也会很公平——未来属于那些能持续把路线图变成工程结果、把工程结果变成商业规模的公司。
而天数智芯这次“甩出来”的四代架构、边端矩阵与落地战绩,至少说明了一件事:
国产 AI 计算芯片,越来越喜欢开始用实力说话了。