[LG]《What One Cannot, Two Can: Two-Layer Transformers Provably Represent Induction Heads on Any-Order Markov Chains》C Ekbote, M Bondaschi, N Rajaraman, J D. Lee... [MIT & EPFL & UC Berkeley] (2025)
两层单头Transformer惊艳展现任意阶Markov链的归纳头表示能力,刷新对模型深度与序列建模关系的理解。
• 传统观点认为,高阶Markov过程至少需三层单头Transformer实现条件k-gram建模,本研究证明两层单头Transformer即可实现任意阶k-gram模型,最紧深度界定。
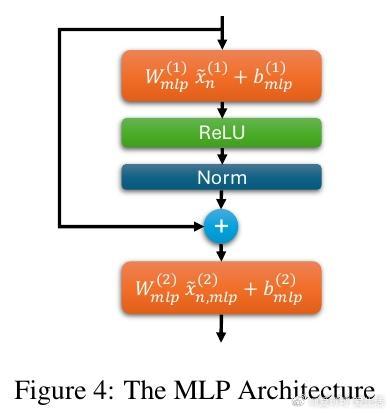
• 关键突破在于巧妙利用MLP中的非线性激活(ReLU)和层归一化,成功从注意力机制中抽取并重构关键上下文信息,补足单头数量不足。
• 进一步,针对一阶Markov链,提出分阶段梯度下降训练算法,理论证明模型能有效学习归纳头,实现近似最优的条件经验分布估计。
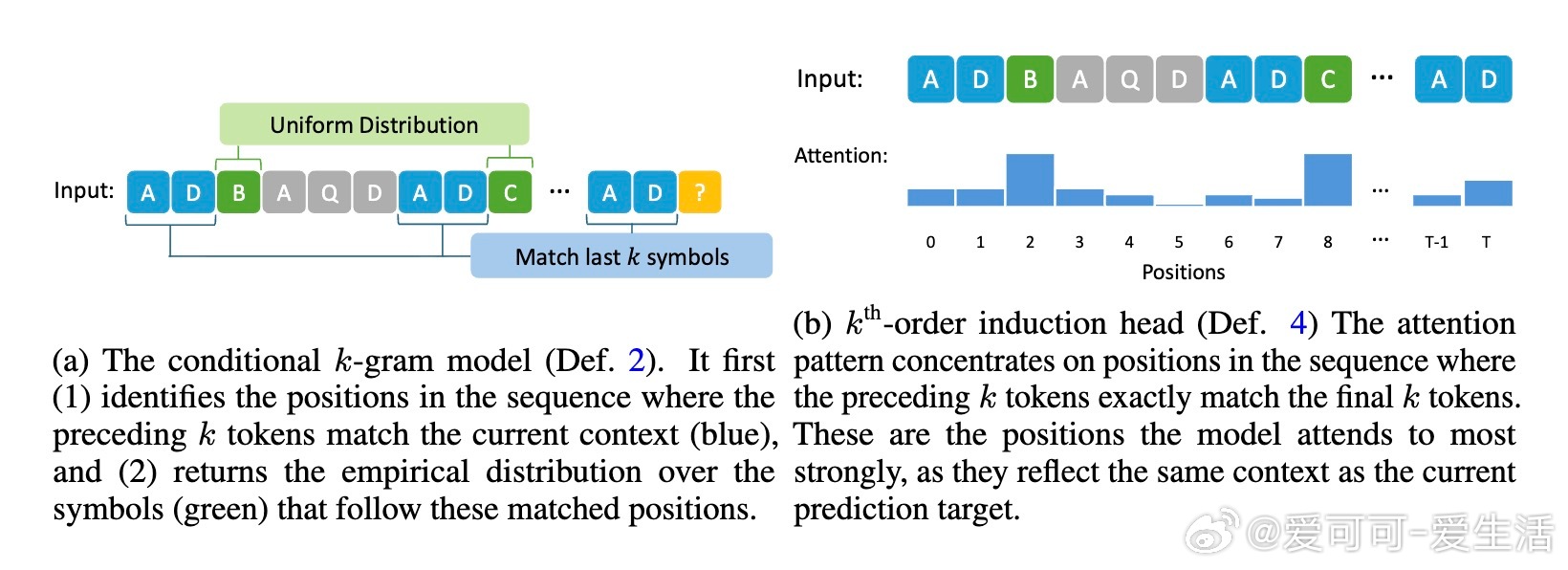
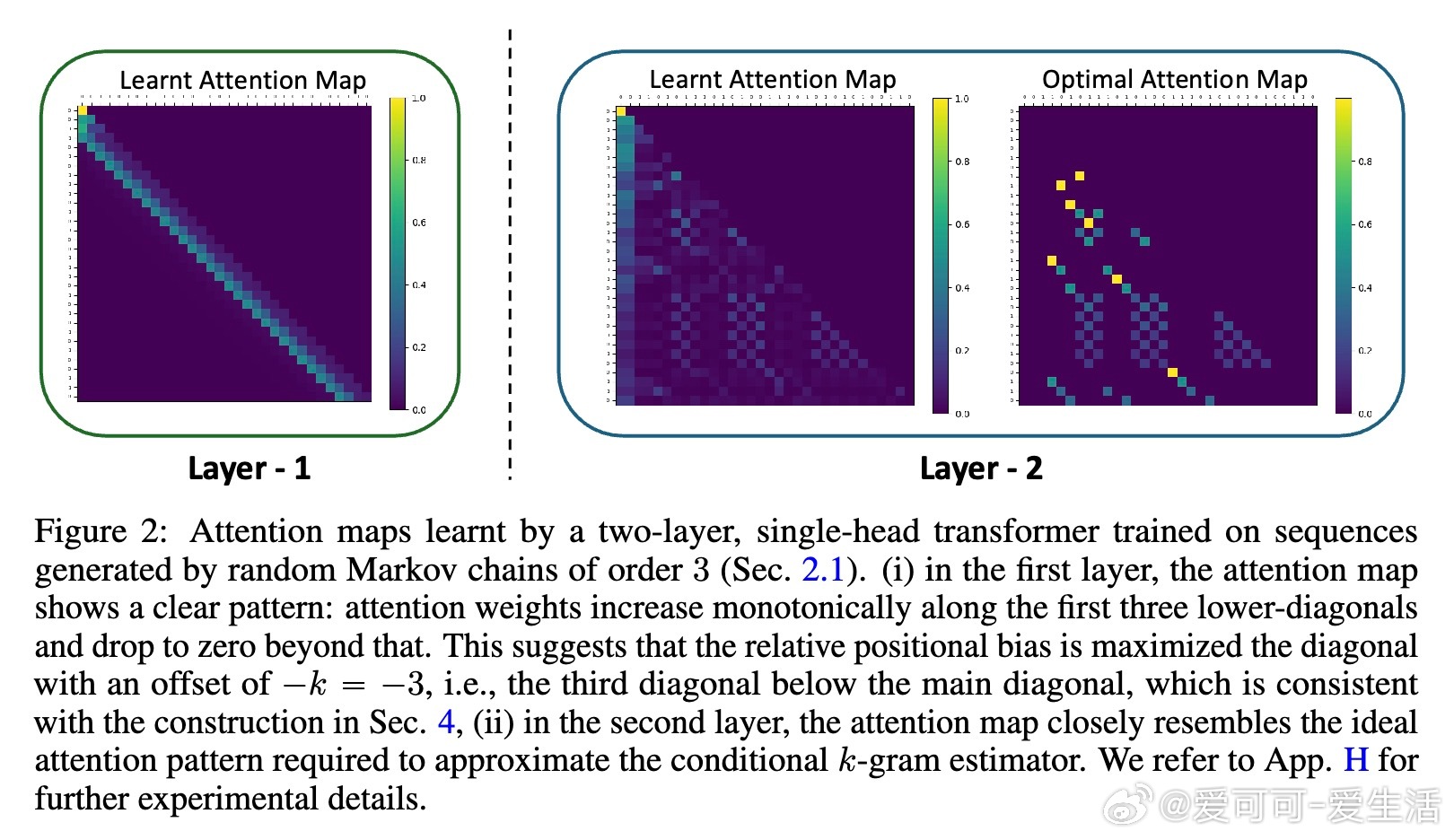
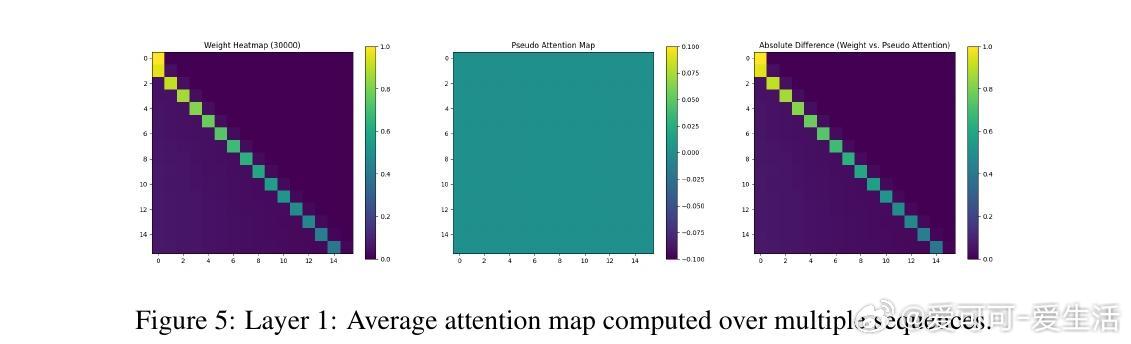
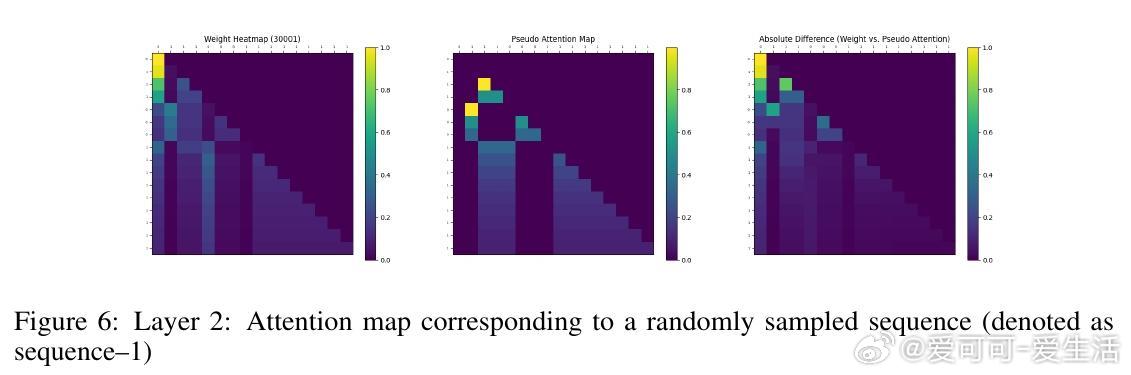
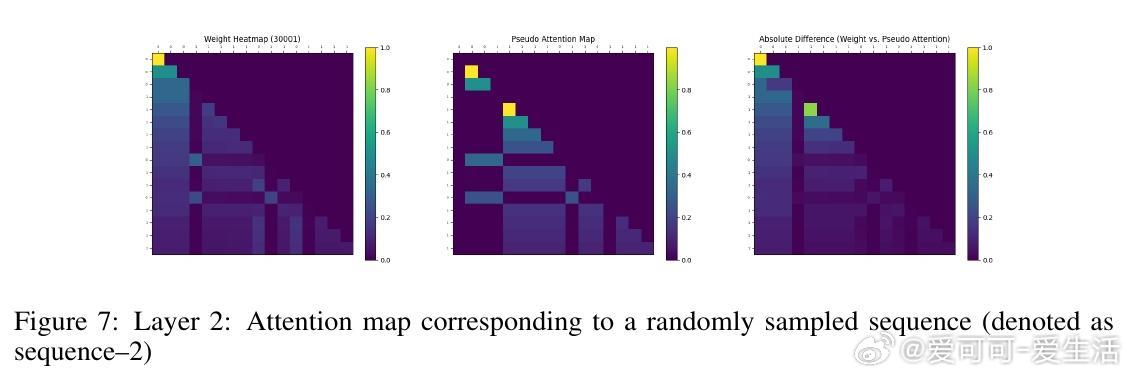
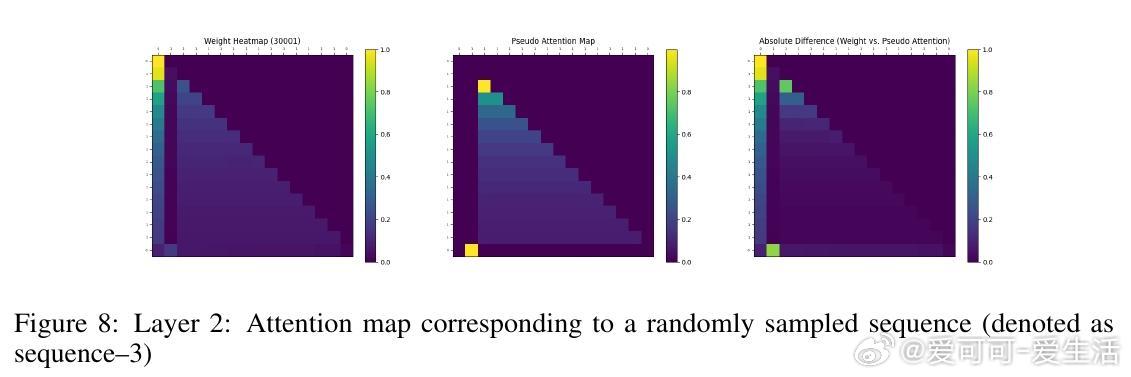
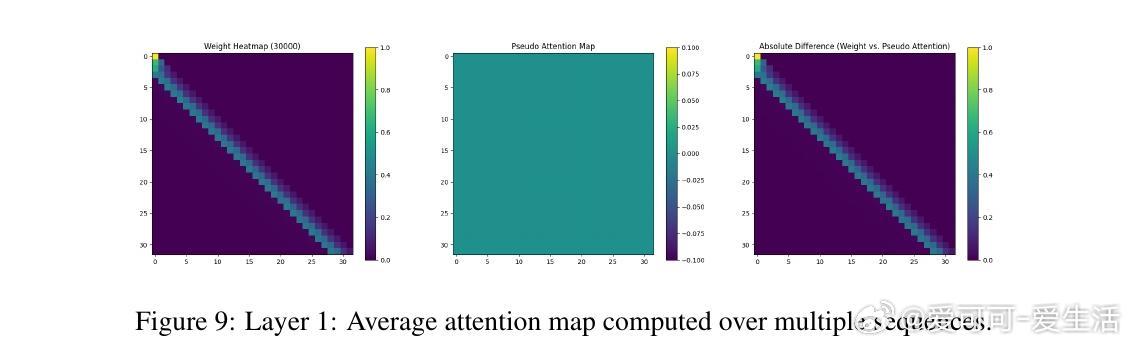
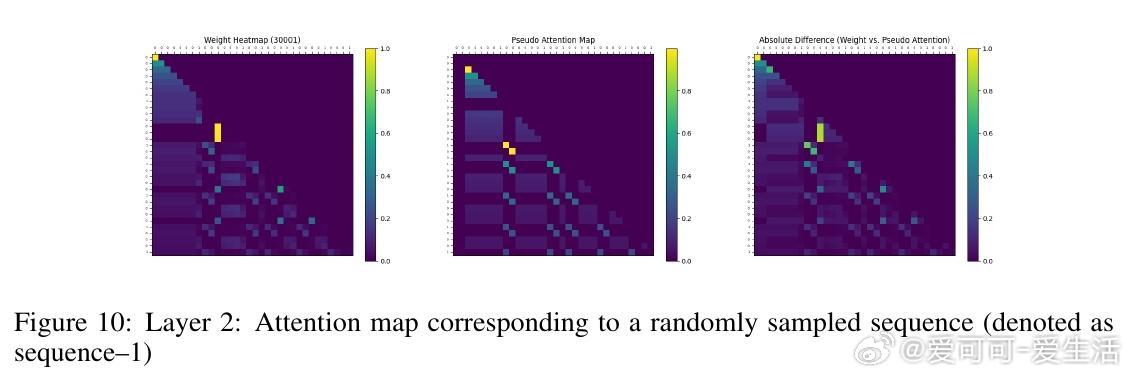
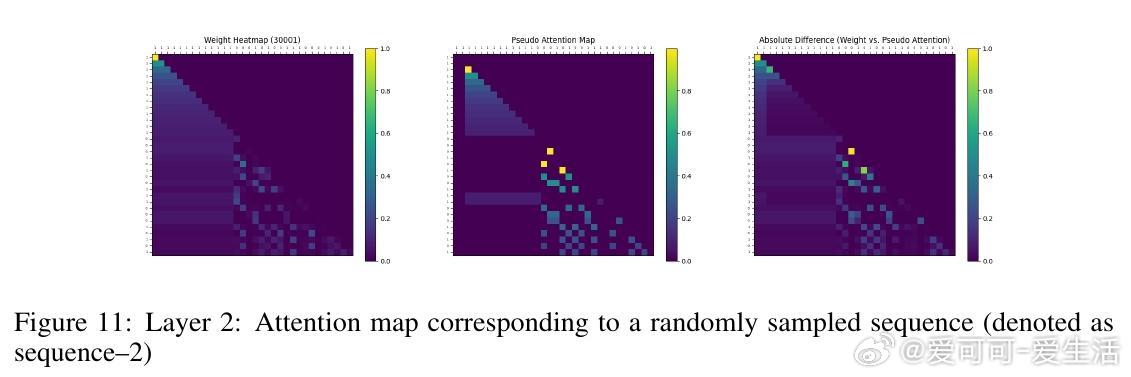
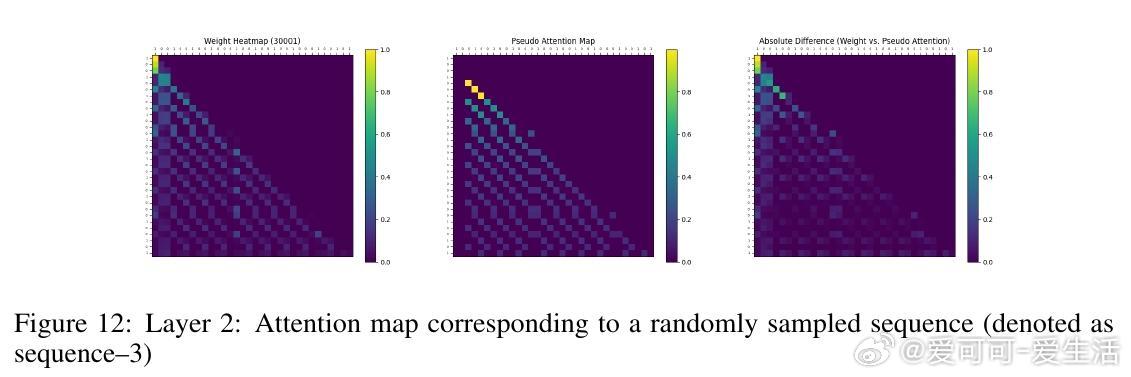
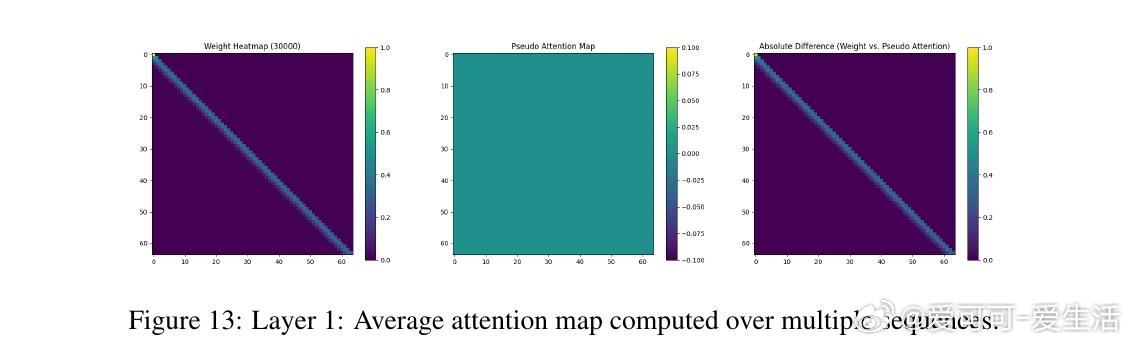
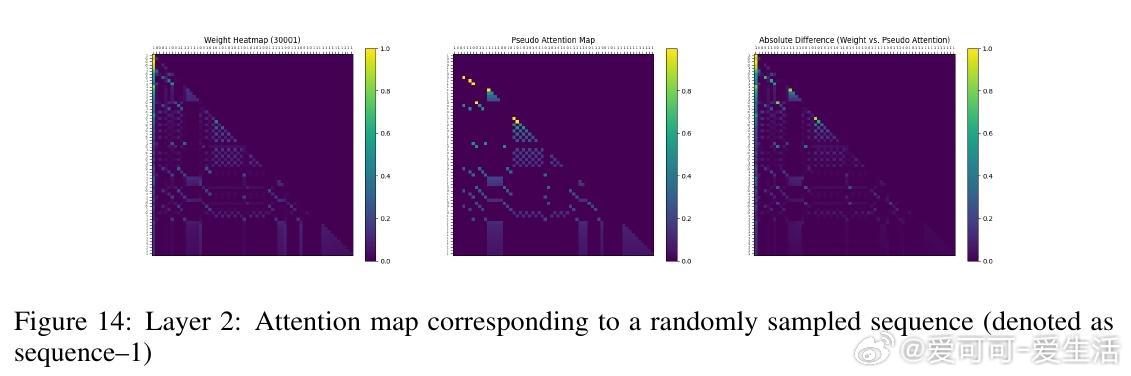
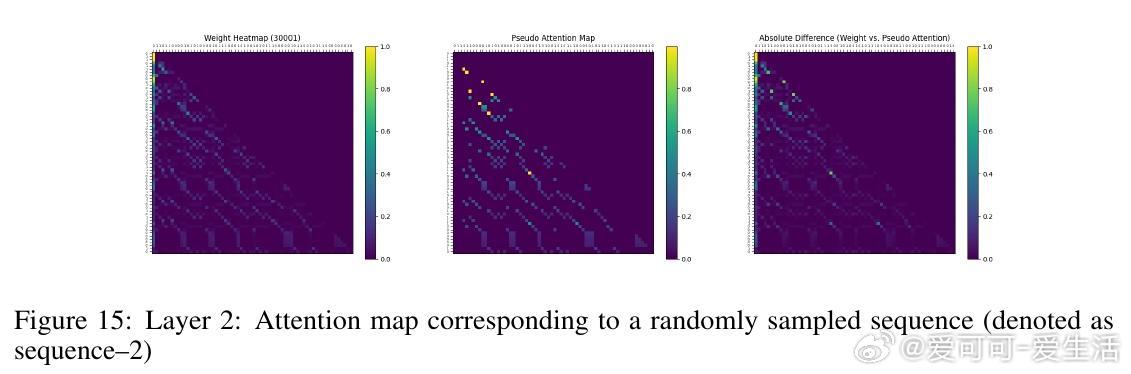
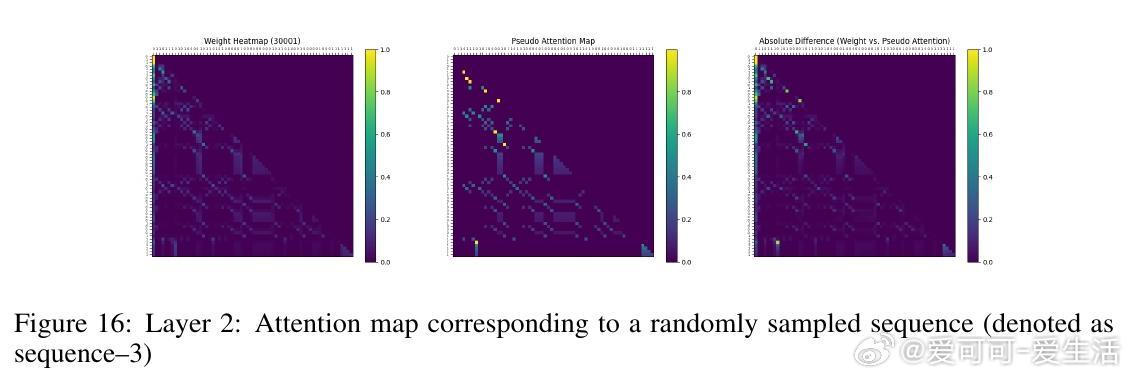
• 实验覆盖一至三阶Markov链,注意力图清晰反映模型对上下文匹配位置的聚焦,验证理论构建的有效性与泛化能力。
• 深刻揭示注意力深度与宽度的权衡:两层双头架构等价于三层单头设计,提示未来Transformer设计中非线性组件与层数的协同优化潜力。
• 研究为理解Transformer中上下文内学习(ICL)的基本限制提供了理论基础,指明了高效且紧凑模型架构的设计方向。
详见论文🔗 arxiv.org/abs/2508.07208,代码开源助力复现与扩展。
Transformer理论归纳头Markov链序列建模机器学习基础深度学习注意力机制