[LG]《Teaching LLMs to Plan: Logical Chain-of-Thought Instruction Tuning for Symbolic Planning》P Verma, N La, A Favier, S Mishra... [MIT CSAIL] (2025)
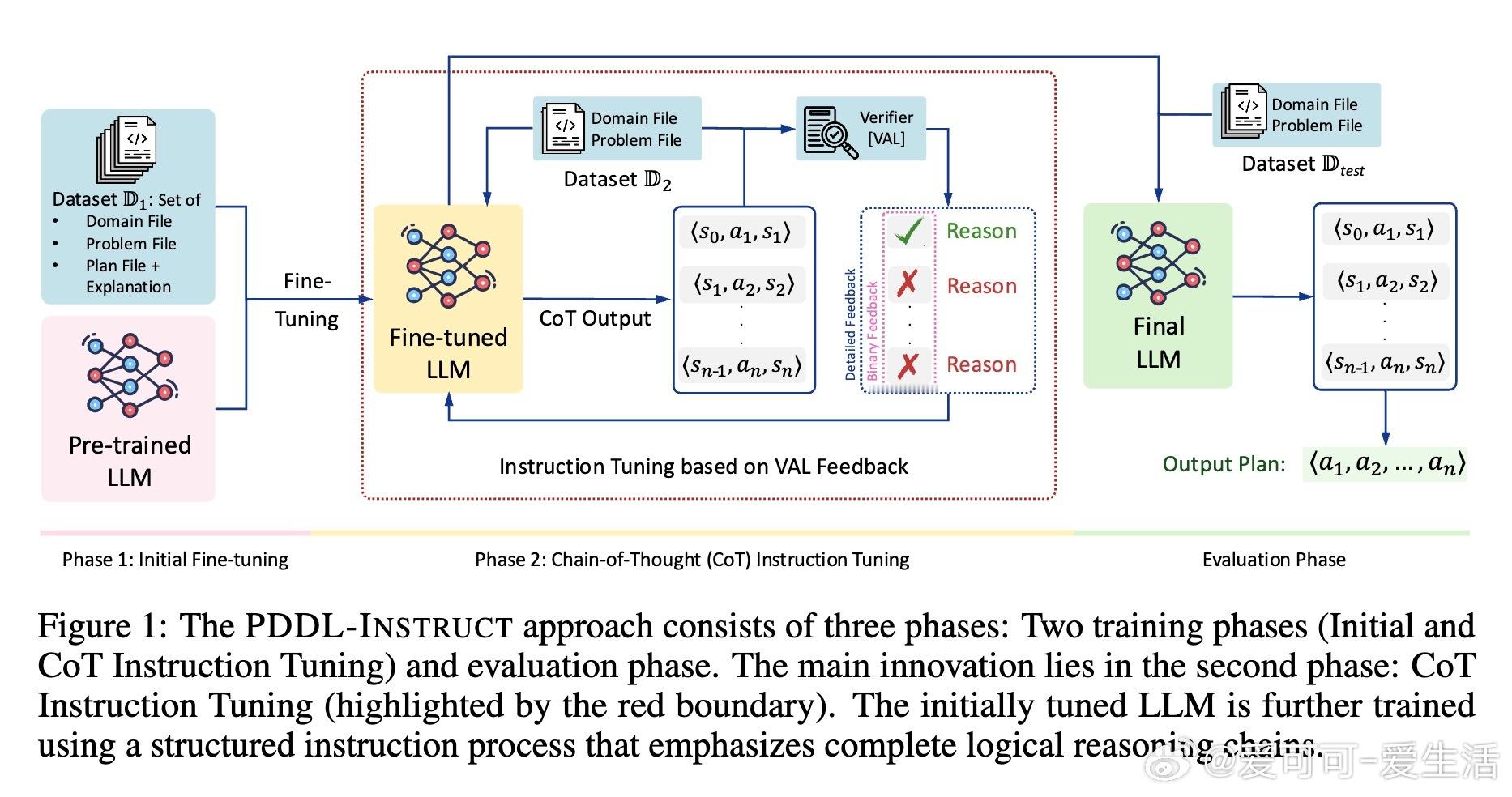
大型语言模型(LLMs)在符号规划领域的能力长期受限,PDDL-INSTRUCT框架通过逻辑链式思维(CoT)指令微调显著提升了这一能力。
• 两阶段训练:初始指令微调阶段融合正确与错误计划样例,教模型识别动作前提及效果逻辑;CoT指令微调阶段强调逐步状态-动作-状态推理链,结合外部验证器VAL提供细粒度反馈,促进模型自我校正。
• 逻辑链式推理:将规划分解为前提验证、效果应用和不变量维护的原子推理步骤,确保每一步状态转换均符合法规,提升生成计划的可靠性和透明度。
• 实验实证:在Blocksworld、Mystery Blocksworld及Logistics三大规划域上,PDDL-INSTRUCT使Llama-3与GPT-4的规划准确率分别提升至最高94%和91%,相较基础模型提升超过60个百分点,且详细反馈显著优于二元反馈。
• 泛化与挑战:方法在多域均表现优异,尤其在语义混淆的复杂域中体现巨大优势,表明逻辑推理框架具备跨场景迁移能力。当前仍集中于满足性规划,未来可扩展至最优规划与更复杂PDDL特性。
• 价值与风险:该方案加强了LLMs的结构化推理和可验证决策能力,对自动驾驶、医疗机器人等安全关键领域具有深远影响,但需防范过度依赖及潜在误用风险。
心得:
1. 明确分解复杂规划任务为可验证的逻辑步骤,极大提升了LLMs在符号推理中的可靠性与准确性。
2. 结合外部形式验证反馈,避免了LLMs内部链式推理可能出现的自洽性缺陷,打造了更稳健的自我纠错机制。
3. 详细错误反馈比简单二元评价更有效,有助模型深入理解规划失败原因,显著加快学习收敛和性能提升。
详见🔗arxiv.org/abs/2509.13351
大语言模型符号规划链式思维指令微调自动规划人工智能