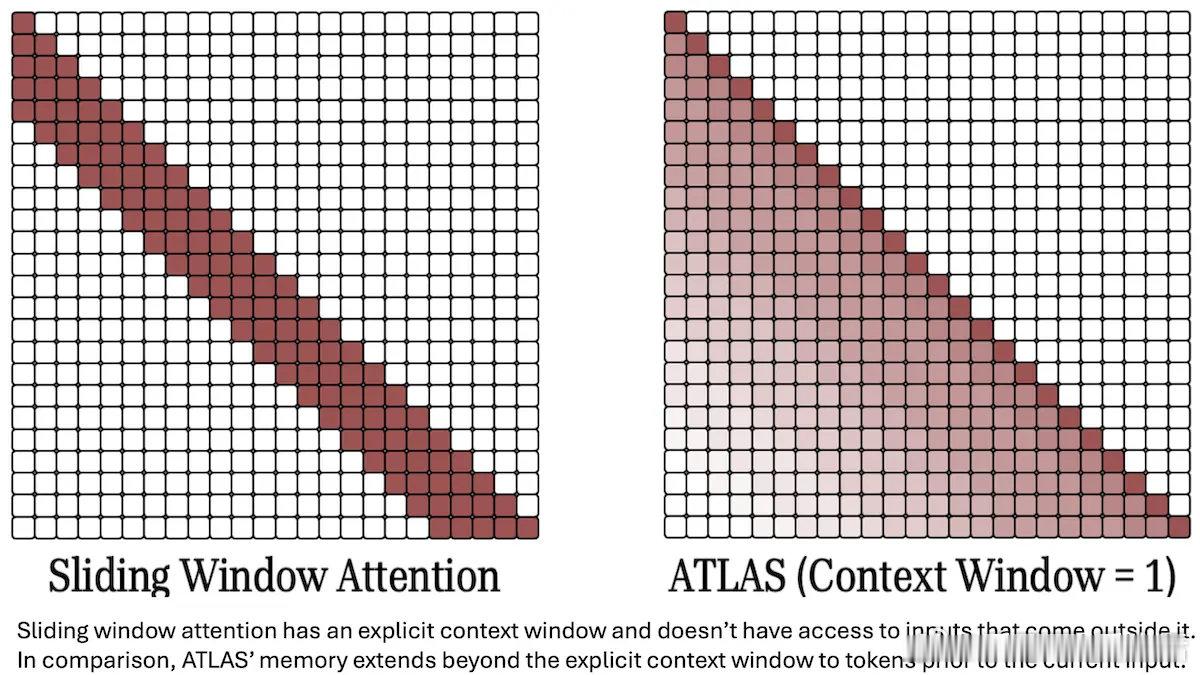
ATLAS 架构实现了超长上下文处理能力,开辟了大规模语言模型的新边界。
• 创新点在于用“可训练记忆模块”替代传统 Transformer 的注意力机制,实现对输入语义内容的存储与检索,支持长达 1000 万 token 的上下文窗口。📚
• 记忆模块通过线性投影生成 key 和 value,动态更新参数以捕捉并利用历史上下文,避免了传统 RNN 信息遗忘和 Transformer 计算资源爆炸的矛盾。
• 在 13 亿参数规模下,ATLAS 在长文本问答任务(BABILong)中达到 80% 准确率,显著优于同规模 Titans(70%)和 GPT-4 在超长输入下的表现下滑。
• 该模型参数在推理时部分可调,具备类似“动态记忆”的能力,突破了当前主流 LLM 约 200 万 token 上下文的限制。
• 未来潜力巨大,适用于视频全分辨率帧率等海量数据输入场景,但大规模扩展表现尚未明朗。
三点启发:
1. 存储与检索结合:将模型参数与动态记忆结合,能更高效管理超长上下文,弱化单一注意力机制的瓶颈。
2. 推理中动态调整权重:打破传统“推理参数冻结”范式,动态更新提升上下文关联理解。
3. 超长上下文的实用价值与评估标准需重构:10M token 以上的上下文处理将引发新的应用场景和性能考核体系,推动模型设计从单纯参数量向结构创新转变。
了解详情🔗 deeplearning.ai/the-batch/atlas-a-transformer-like-architecture-can-process-a-context-window-as-large-as-ten-million-tokens
大规模语言模型 长上下文 Transformer 机器学习 人工智能