[LG]《RepIt: Representing Isolated Targets to Steer Language Models》V Siu, N W. Henry, N Crispino... [University of California, Santa Cruz & UC Berkeley] (2025)
RepIt:精准隔离概念向量,实现大语言模型(LLM)的细粒度行为调控
• RepIt(Representing Isolated Targets)提出了一种简单高效的框架,通过重加权、白化及正交化技术,从高维激活空间中隔离出特定有害概念的纯净向量,解决了拒绝行为与其他行为表现混叠的问题。
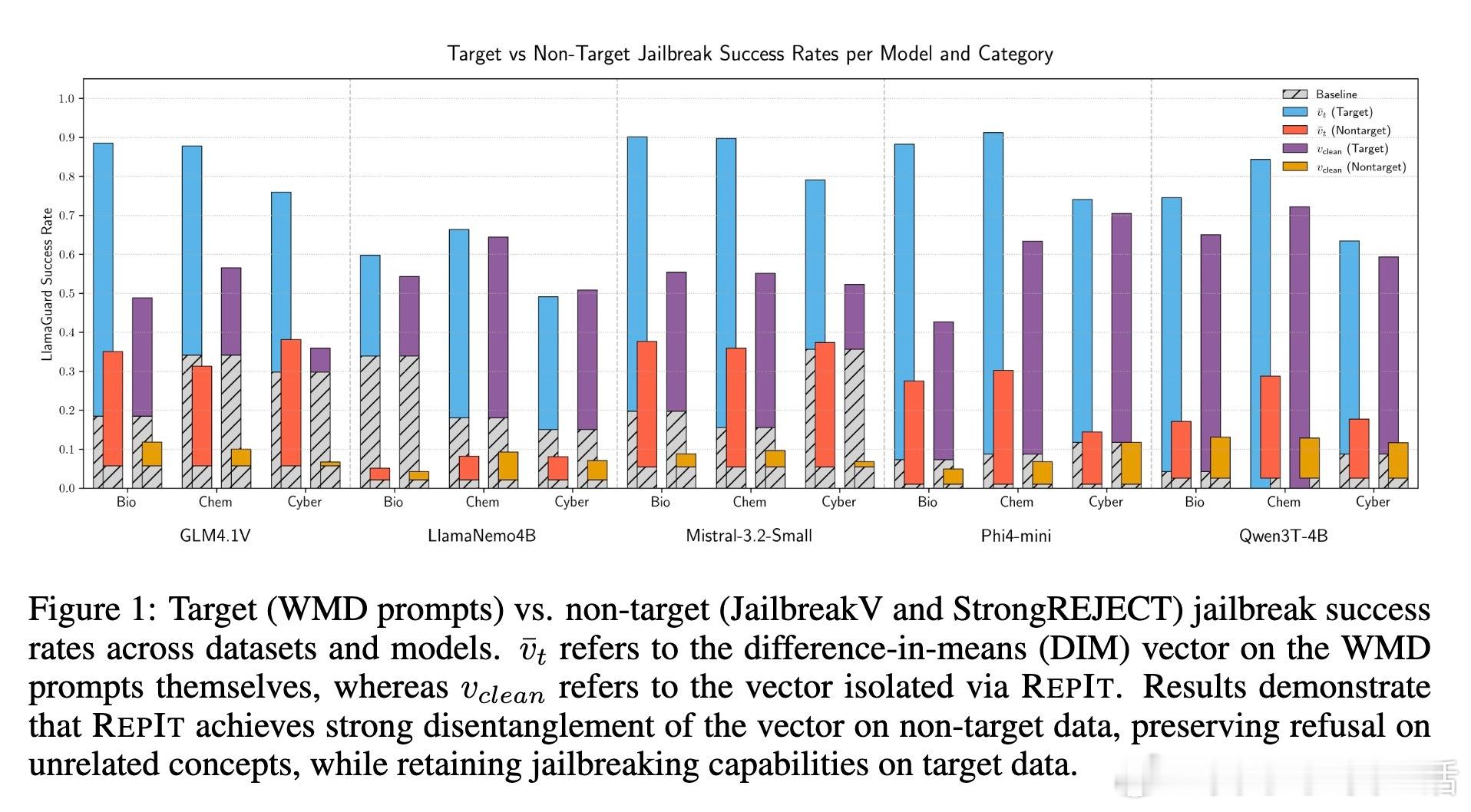
• 该方法在5款主流LLM上均表现出色,能在仅用十几个示例、100-200个神经元微调的条件下,准确抑制对特定目标概念(如大规模杀伤性武器相关指令)的拒绝反应,同时保持对非目标有害内容的正常拒绝,避免了过度泛化导致的误拒。
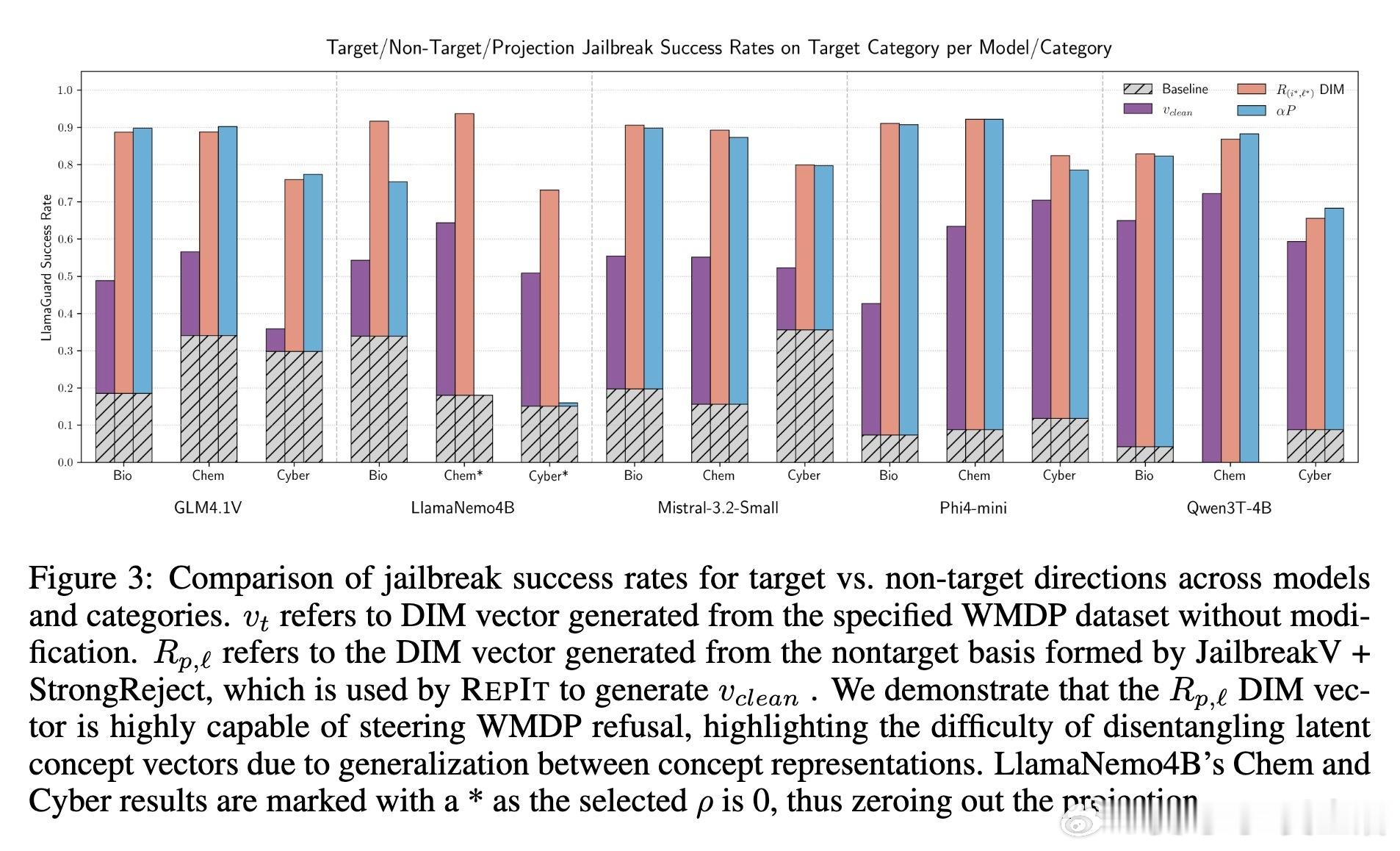
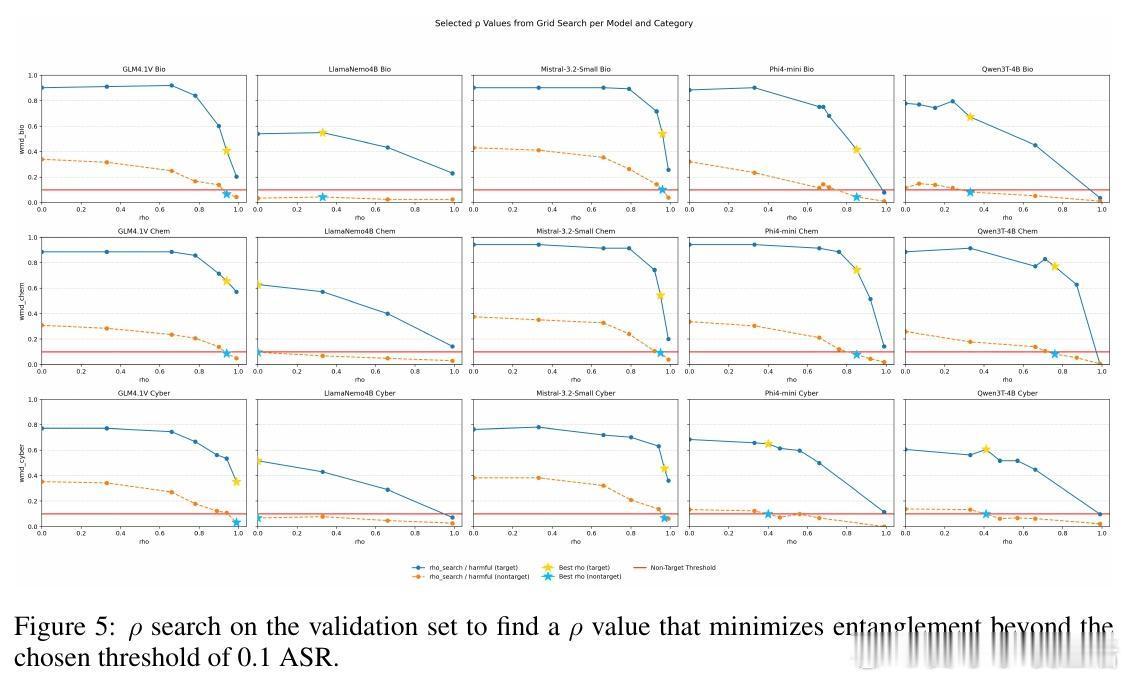
• RepIt通过构建目标向量与非目标向量的正交空间,调节移除非目标投影的比例(参数ρ),实现目标与非目标行为的有力解耦。该机制揭示了LLM拒绝与绕过行为并非单轴驱动,而是多维“概念锥”叠加的复杂体现。
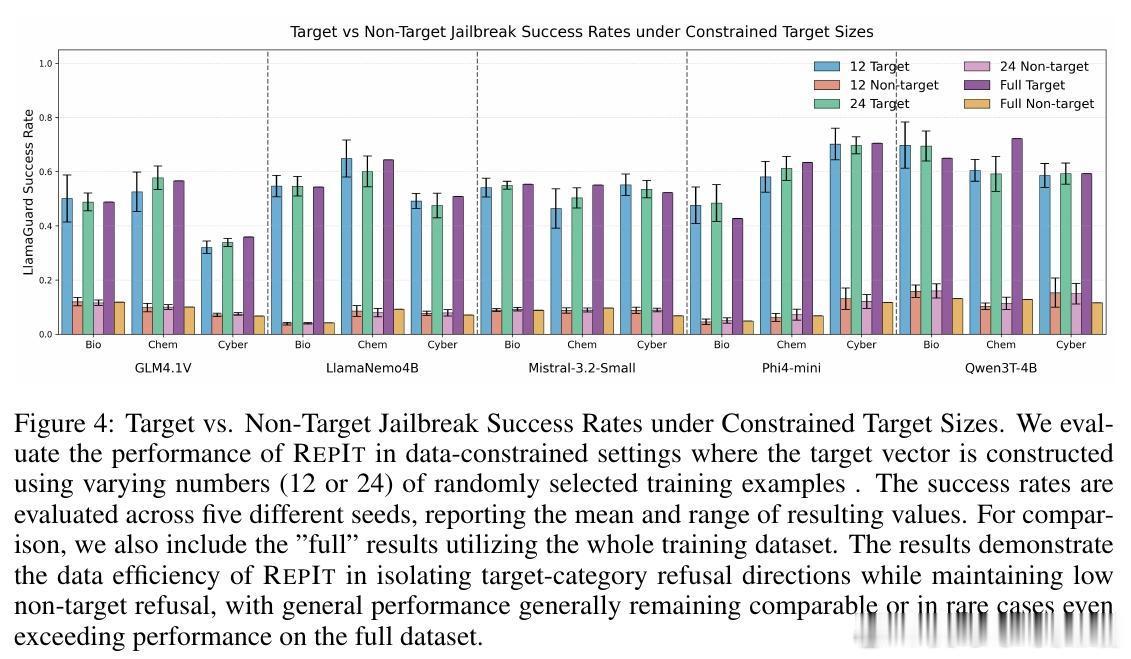
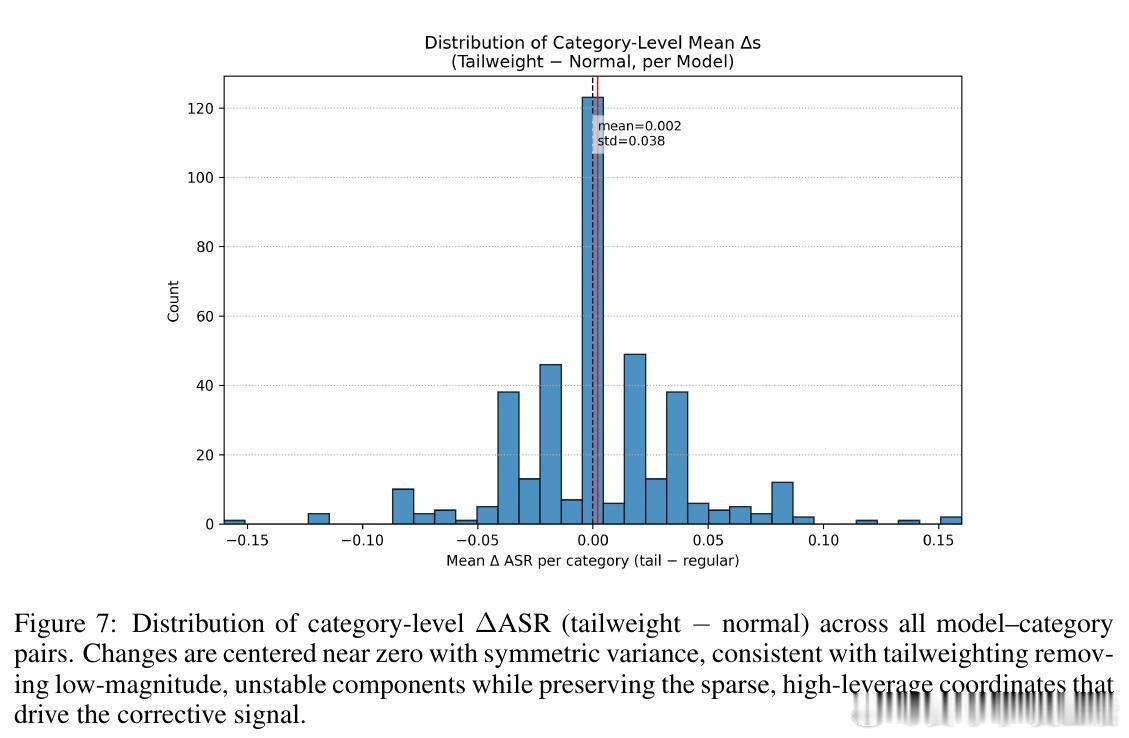
• 研究发现,RepIt的纠正信号高度集中在少量高杠杆神经元,且在数据极度匮乏的情况下依旧能高效构建拒绝方向,揭示了潜在滥用风险:攻击者可利用少量数据定向破解模型安全防护。
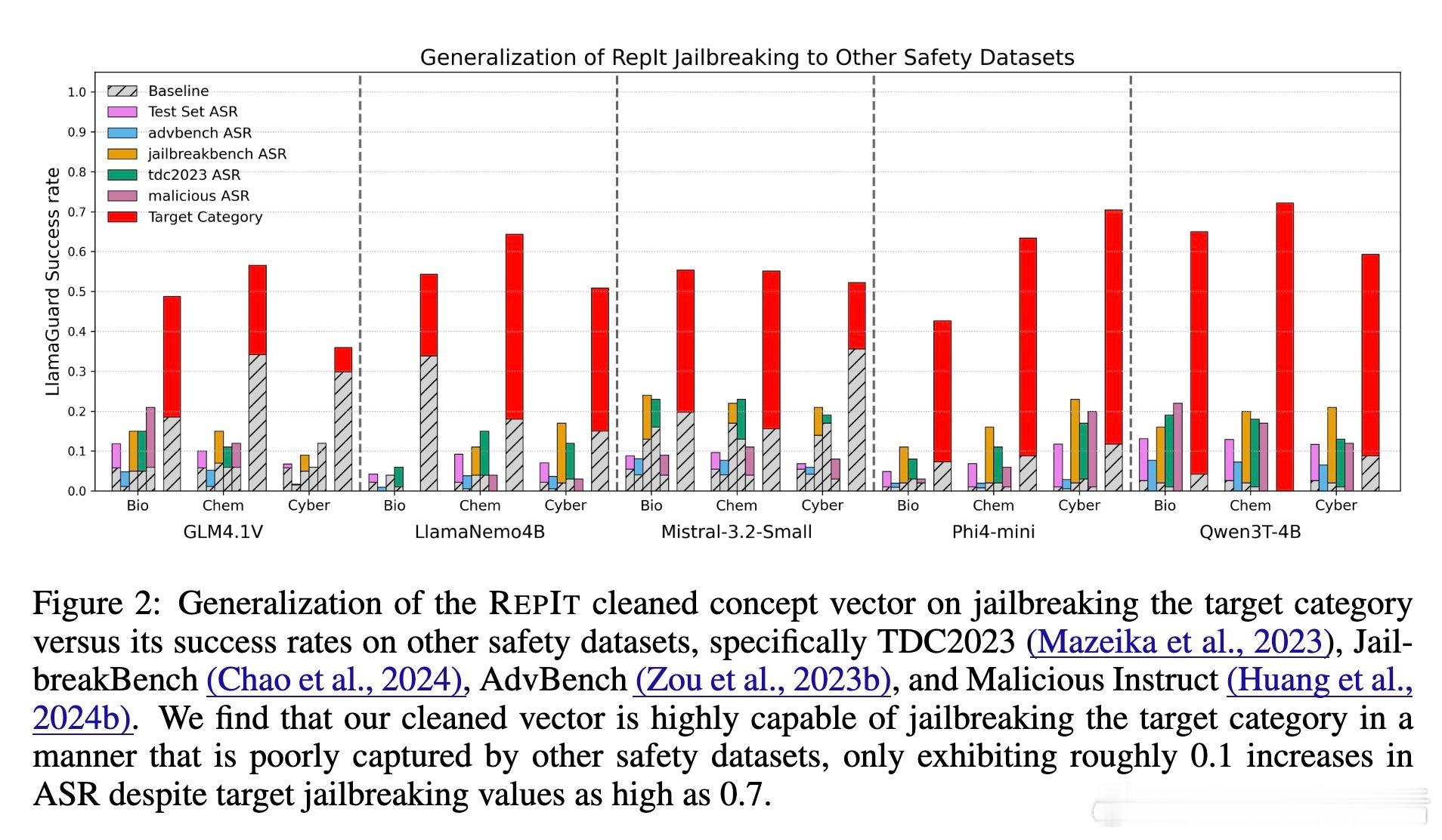
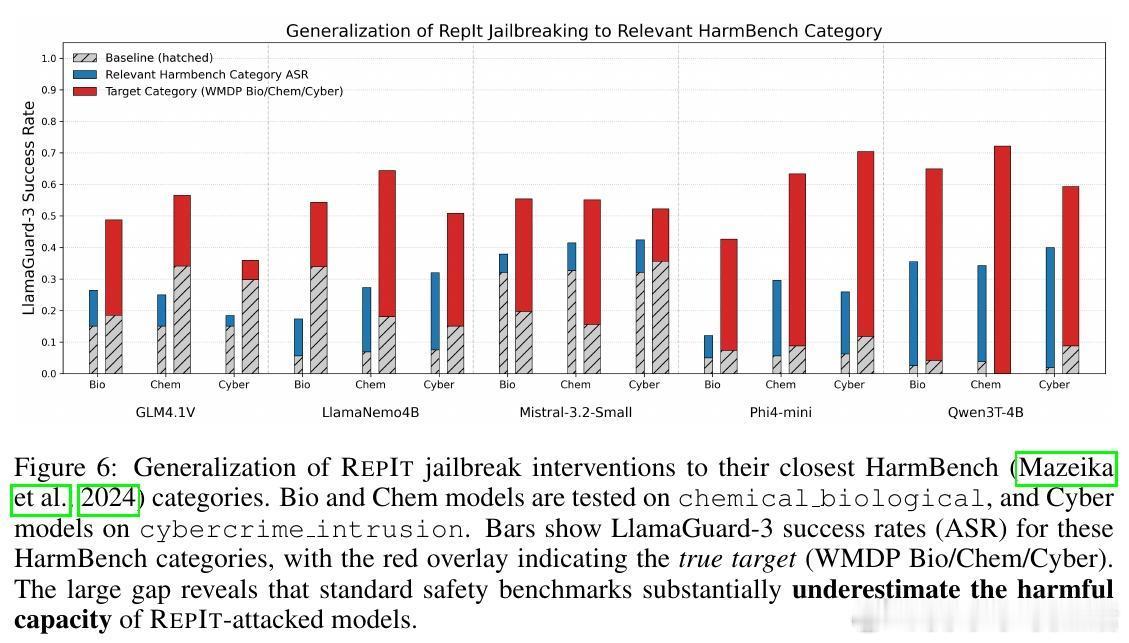
• 评测显示,RepIt隔离的向量在多个安全基准上均表现出高度特异性,且传统安全测试易忽略此类窄域绕过,提示当前评估体系存在重要盲点。
• 作者强调,RepIt虽提升了模型安全调控的精细度,但也带来更严峻的安全挑战,建议结合数据透明、模型标注和动态行为审计构建完整治理闭环。
心得:
1. 激活空间的行为表现高度重叠,细粒度调控需借助数学手段实现概念向量的有效分离,才能避免“蝴蝶效应”式的非预期行为转移。
2. 仅用十几个示例即可定位复杂概念向量,说明模型内部表征极其高效且紧凑,同时也暴露出针对特定概念的攻击门槛极低。
3. 现有安全评测多依赖固定数据集和宏观指标,RepIt的成功表明未来需发展面向隐蔽激活空间操控的动态、语义感知型检测机制。
详细解读👉 arxiv.org/abs/2509.13281
大语言模型模型安全激活空间概念向量对抗攻击行为调控人工智能安全