[LG]《Metacognitive Reuse: Turning Recurring LLM Reasoning Into Concise Behaviors》A Didolkar, N Ballas, S Arora, A Goyal [Meta] (2025)
大语言模型(LLM)推理效率的关键突破:将重复的多步推理抽象为“行为”以实现快速复用。
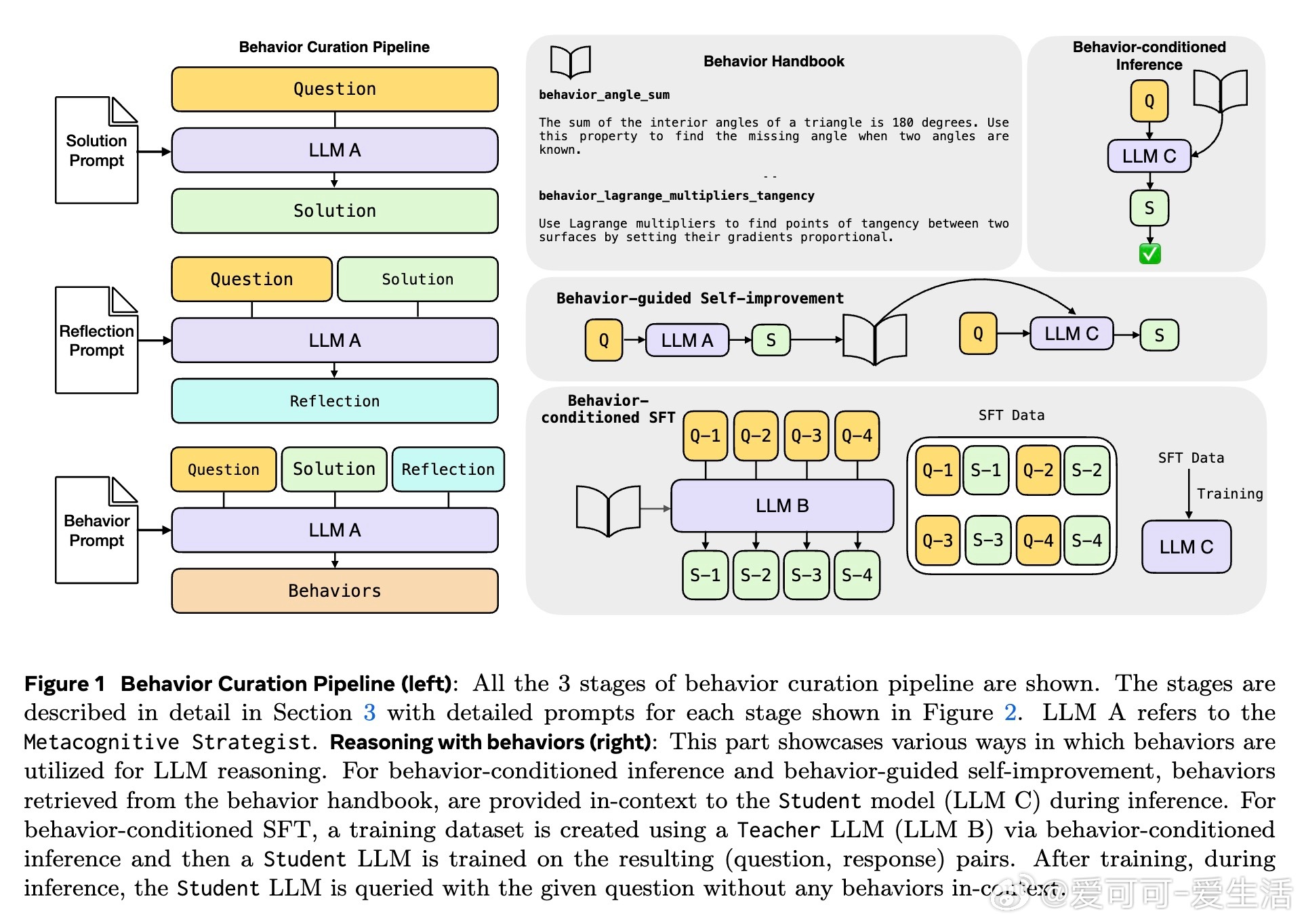
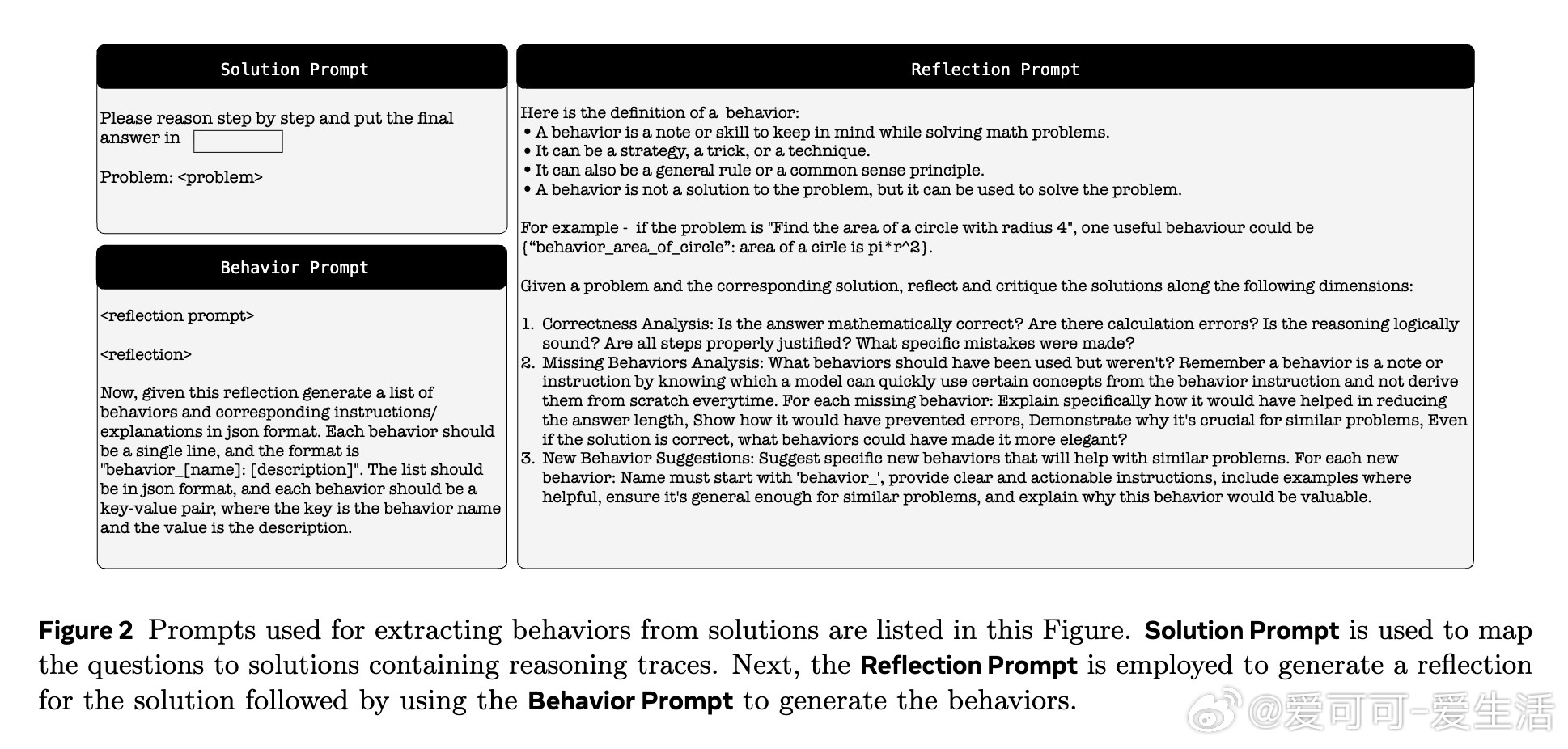
• 通过模型自我反思链式推理过程,提炼出具名且精简的“行为”(行为名+具体操作指令),构建“行为手册”存储常用推理片段。
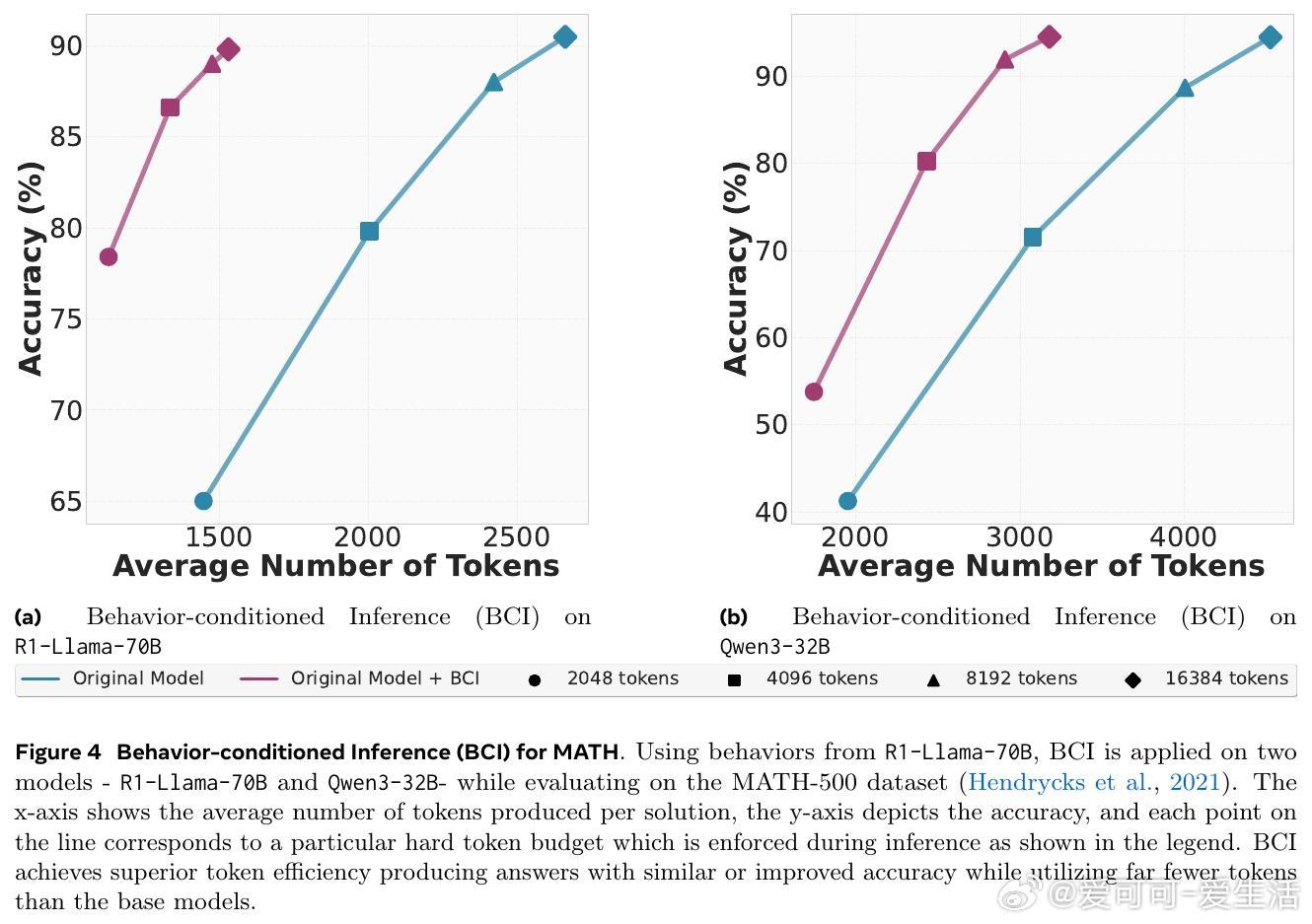
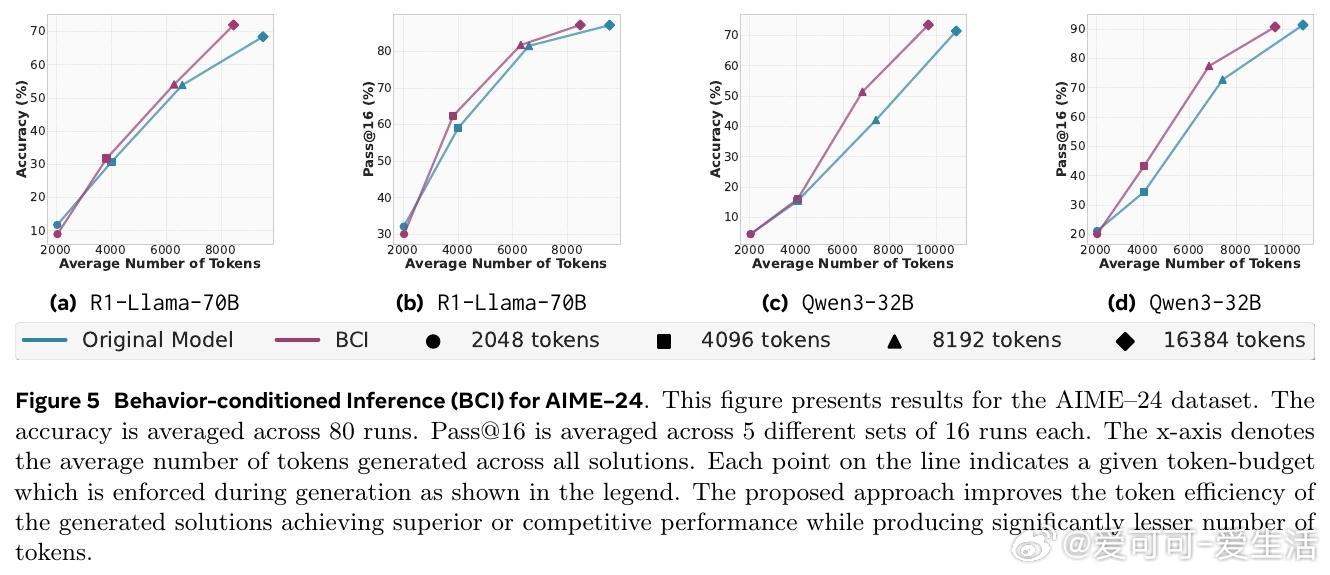
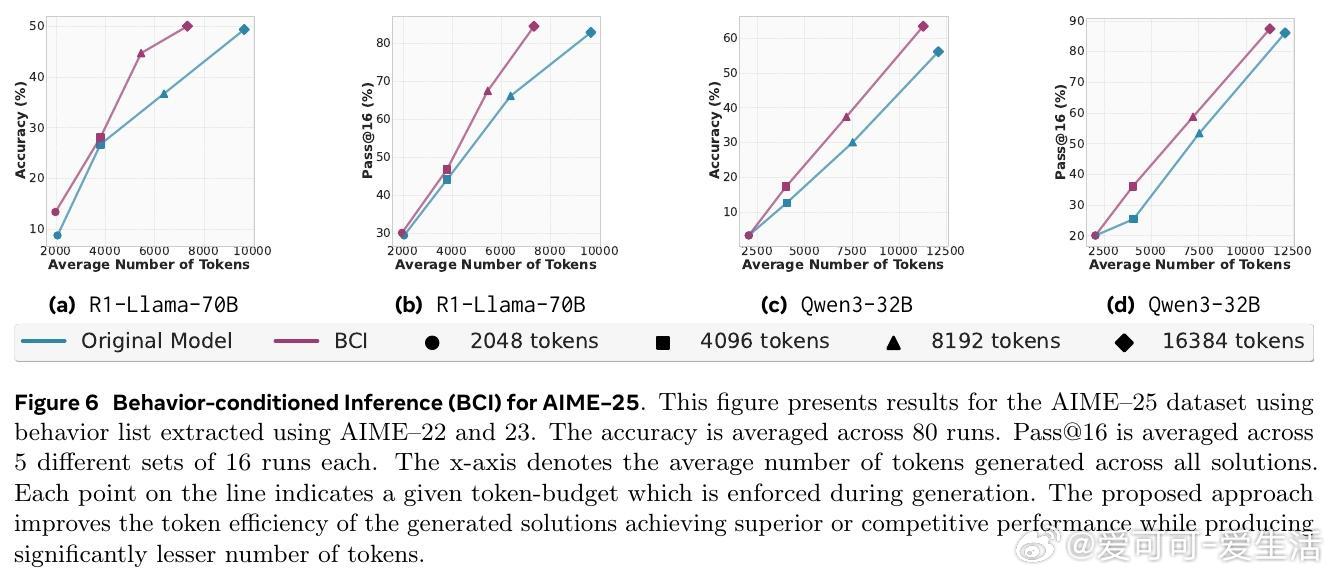
• 行为用于推理时可显著减少冗余推理步骤,行为条件推理(BCI)在MATH与AIME数学竞赛数据集上,推理token数减少46%,准确率保持或提升。
• 利用行为指导模型自我改进,反馈历史行为辅助新推理,精准度较传统批判-修正提升10%,且更好利用增长的token预算。
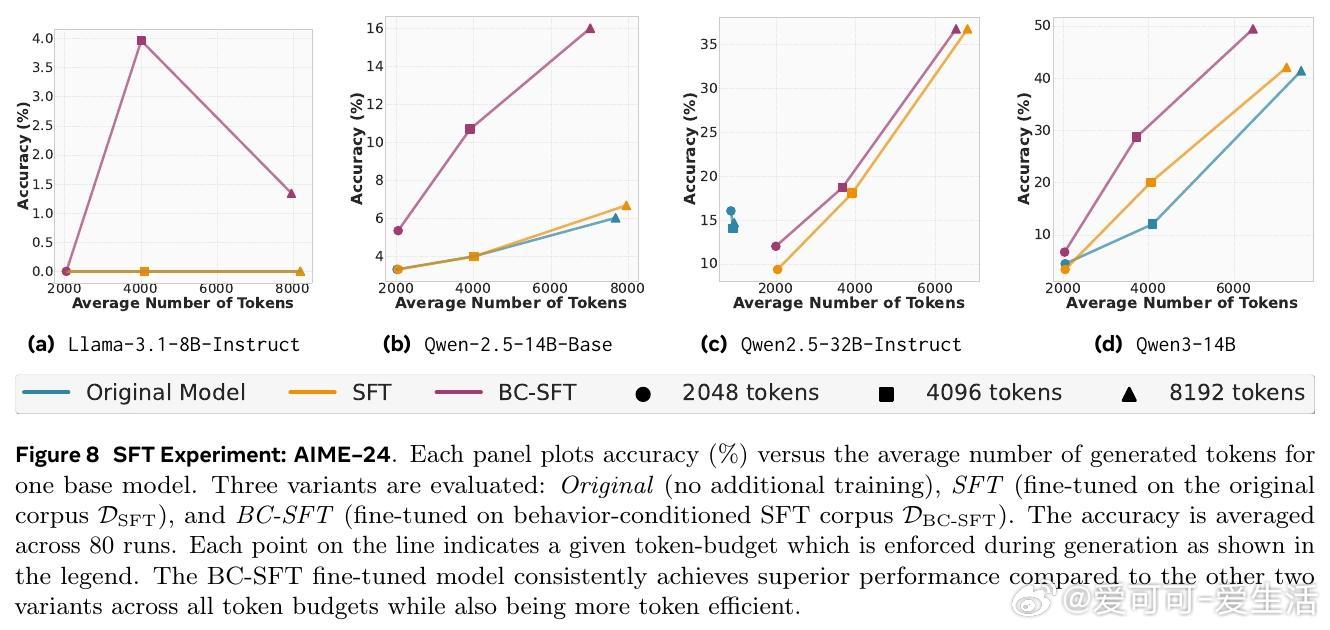
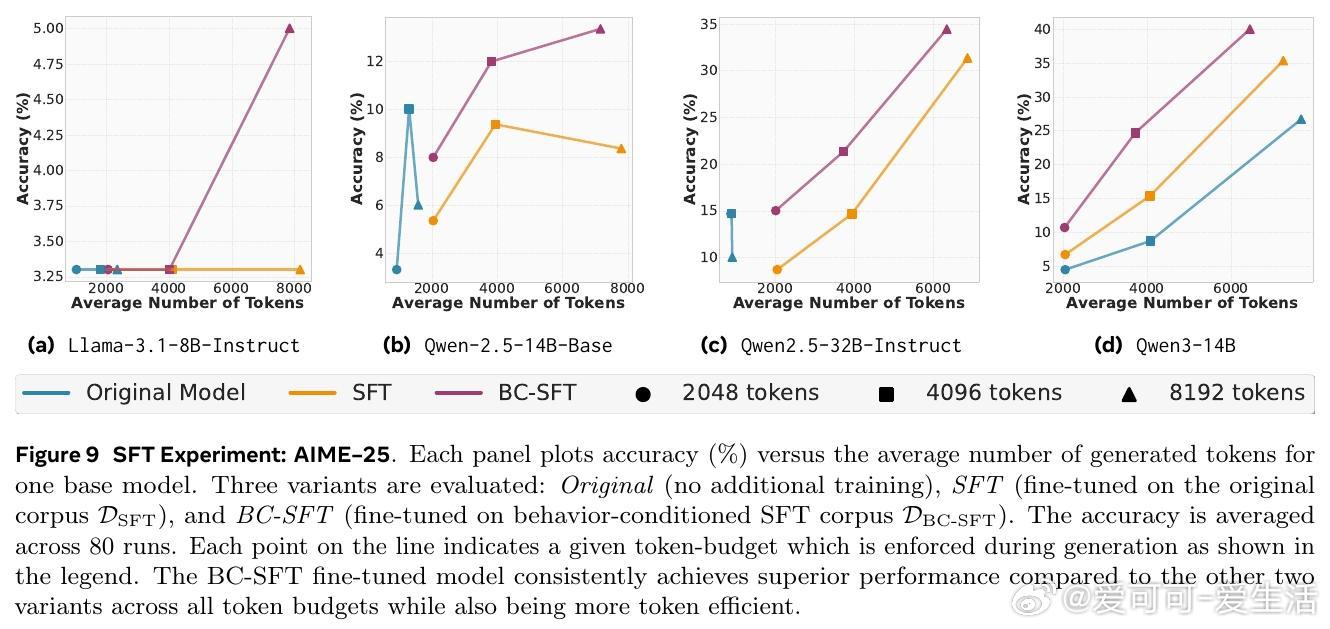
• 通过行为条件监督微调(BC-SFT),将行为知识内化于模型参数,显著提升非推理模型的多步推理能力与token效率,优于普通监督微调。
• 行为手册区别于传统基于事实检索的记忆,聚焦“如何思考”的程序化知识,开辟LLM长期积累推理方法的新路径。
• 目前行为检索为静态加载,未来可望实现动态按需调用,支持跨领域扩展,推动数学、编程、定理证明等复杂任务的高效智能推理。
心得:
1. 抽象重复推理步骤为操作性行为,突破传统长链思维中token膨胀的瓶颈,体现了“记忆如何推理”胜过“记忆结论”的理念。
2. 自我反思机制赋能模型自我学习与迭代提升,展示生成模型内生演化推理策略的可能性,突破纯监督和单次推理限制。
3. 结合行为知识进行微调,促使模型在参数空间内形成高效推理套路,开启了从“思考长链”向“思考捷径”的转变。
更多详情🔗 arxiv.org/abs/2509.13237
大语言模型多步推理元认知机器学习算法优化