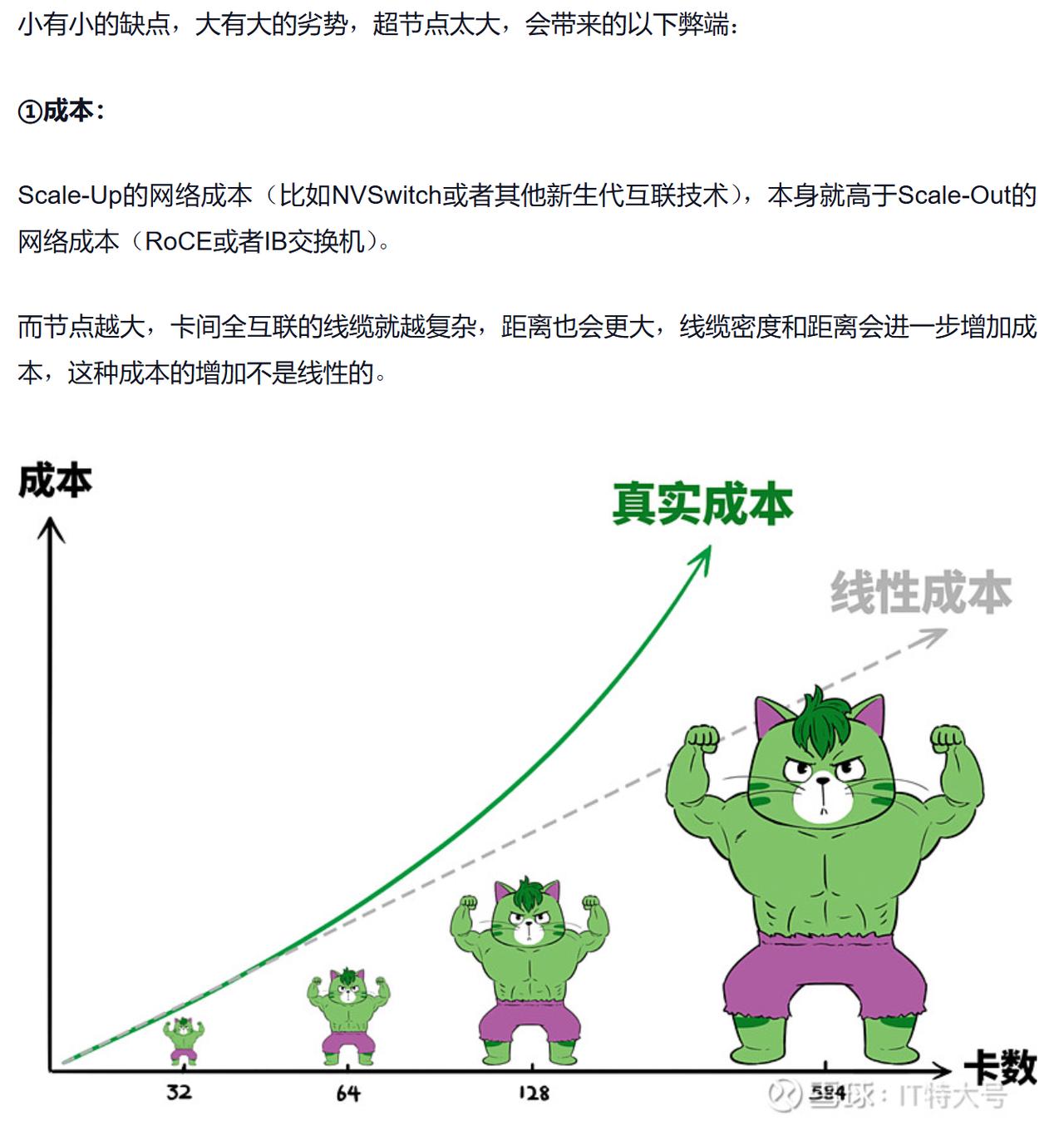
超节点到底该多大?业内吵翻了,但没人问用户 最近跟几个做AI训练的朋友吃饭,聊到一个怪现象:现在一说超节点,大家都往大了吹,好像不上千卡都不好意思打招呼。厂商发布新品,动不动就“总算力刷新”、“训练速度破纪录”,听着一个比一个猛。 但冷静下来想想:这些千卡超节点,到底谁在用? 头部大厂确实需要,万亿参数模型,规模本身就是门槛。可除了那几家,剩下几万家做AI应用、做垂直模型、做行业落地的企业,真用得上千卡吗? 现实是,更多企业卡在中间:8卡跑不动千亿参数模型,64卡又不知道选谁家的,上千卡?机房塞不下、预算批不了、运维跟不上。 更魔幻的是,很多智算中心建了上千卡,结果因为架构老旧、生态封闭,主流框架跑不了,利用率不到30%。钱花了,卡堆了,企业却用不起来。 政协委员郭御风说“重建设、轻应用”,就是这个理。大家光顾着比规模,忘了问一句:用户到底需要什么? 对万亿参数训练,384卡、768卡叫超节点;但对更广大的企业,32卡、64卡能跑起来、能兼容现有代码、能塞进现有机房,成本可控、开箱即用——这种配置,凭什么不叫超节点? 所以别被厂商的“标准答案”框死了。真正的超节点,不应该由某一家厂商说了算,能满足企业高速高性能AI算力的真实需求,就是“好猫”。 超节点 GTC大会 国产算力