[CL]《Jointly Reinforcing Diversity and Quality in Language Model Generations》T Li, Y Zhang, P Yu, S Saha... [Meta FAIR] (2025)
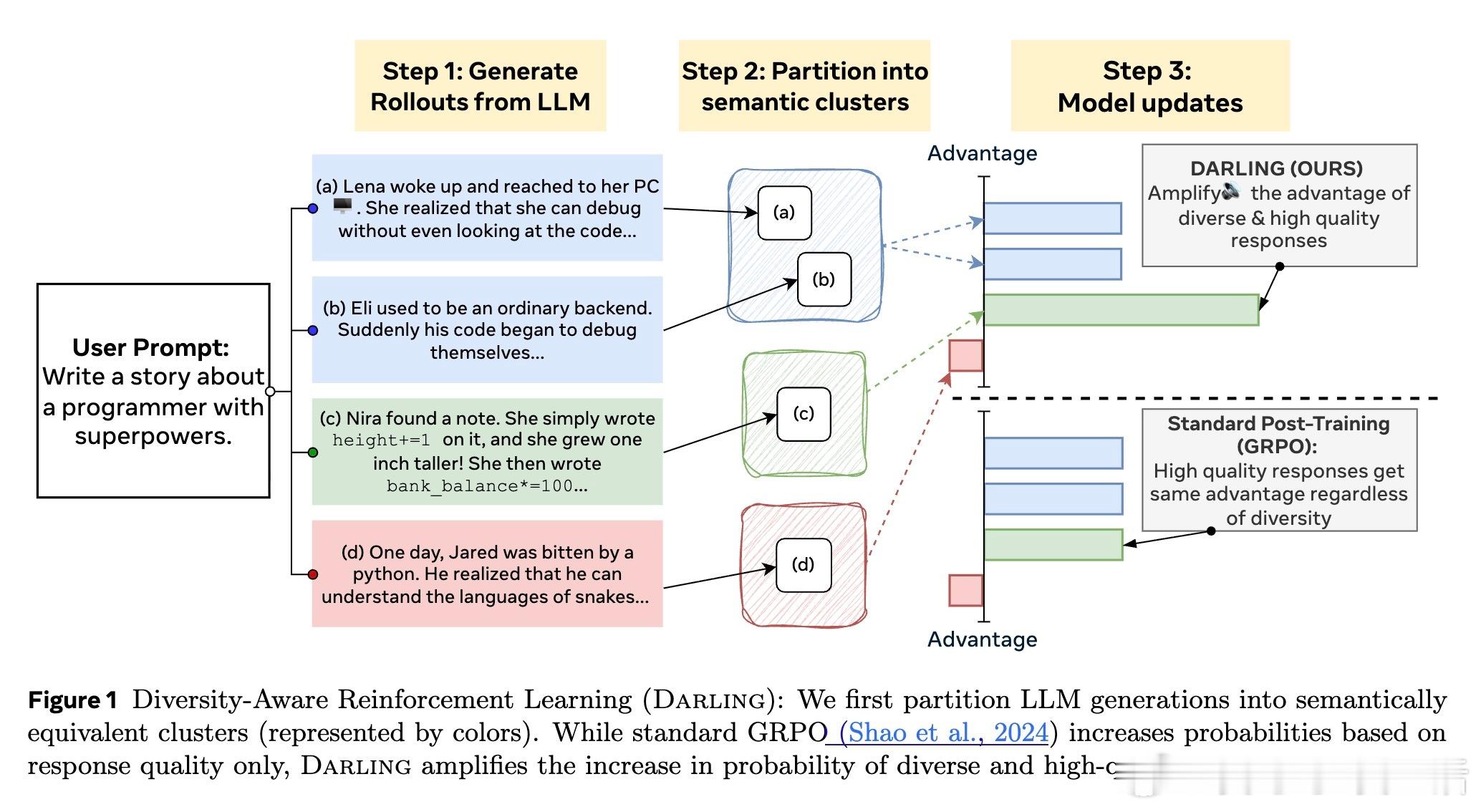
语言模型(LLM)后训练往往在提升准确性和有用性的同时,导致生成结果多样性显著下降,限制了其在创意和探索性任务中的表现。针对这一难题,DARLING(Diversity Aware Reinforcement Learning)框架通过语义层面的多样性判别与质量奖励的联合优化,实现了生成内容质量与多样性的同步提升。
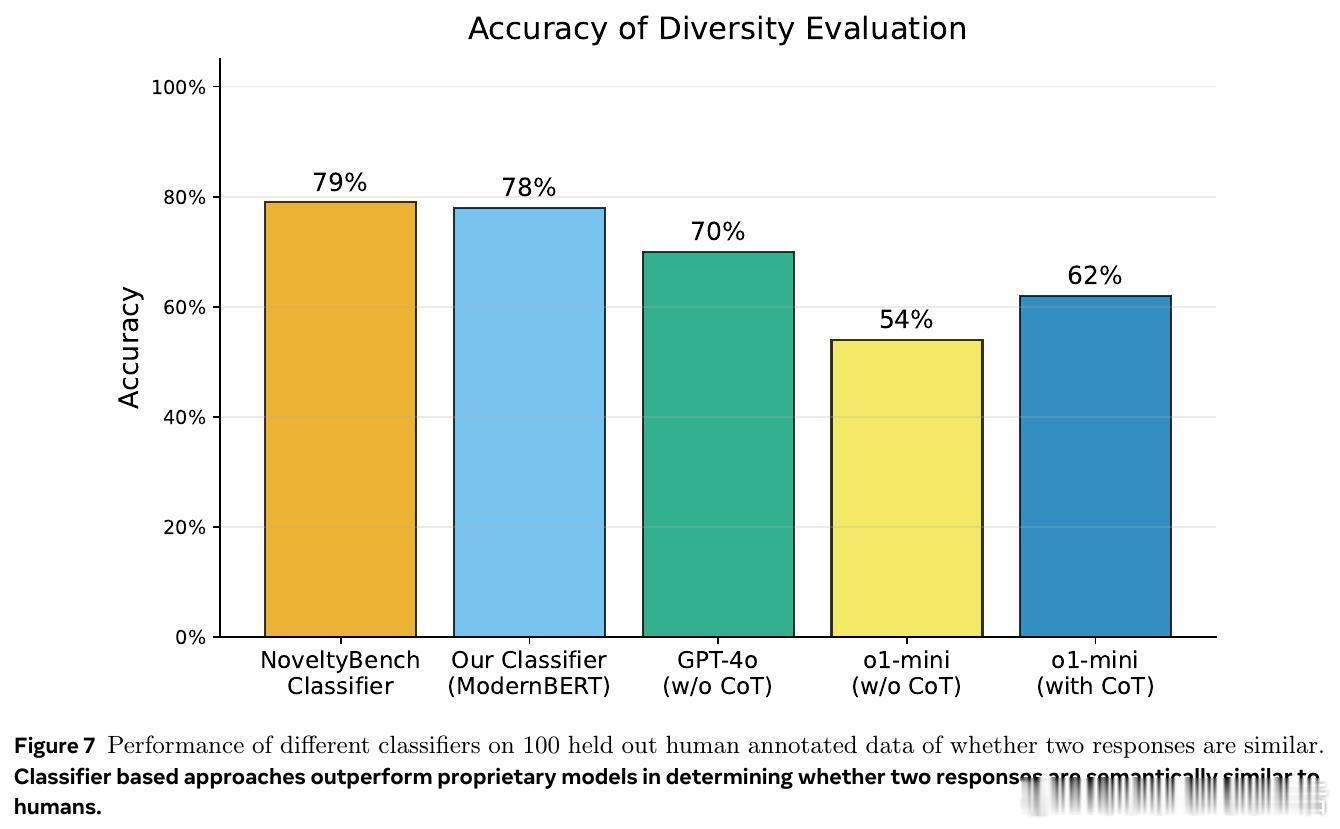
• 语义分区:采用训练得到的语义等价分类器,将模型生成的多条响应划分为语义等价类,突破传统基于词汇表层的多样性度量,捕捉更深层次的语义差异。
• 多样性-质量融合奖励:将语义多样性信号与质量奖励相乘,作为强化学习的目标,强化对“高质量且语义多样”响应的概率提升,避免单纯质量优化导致的多样性崩溃。
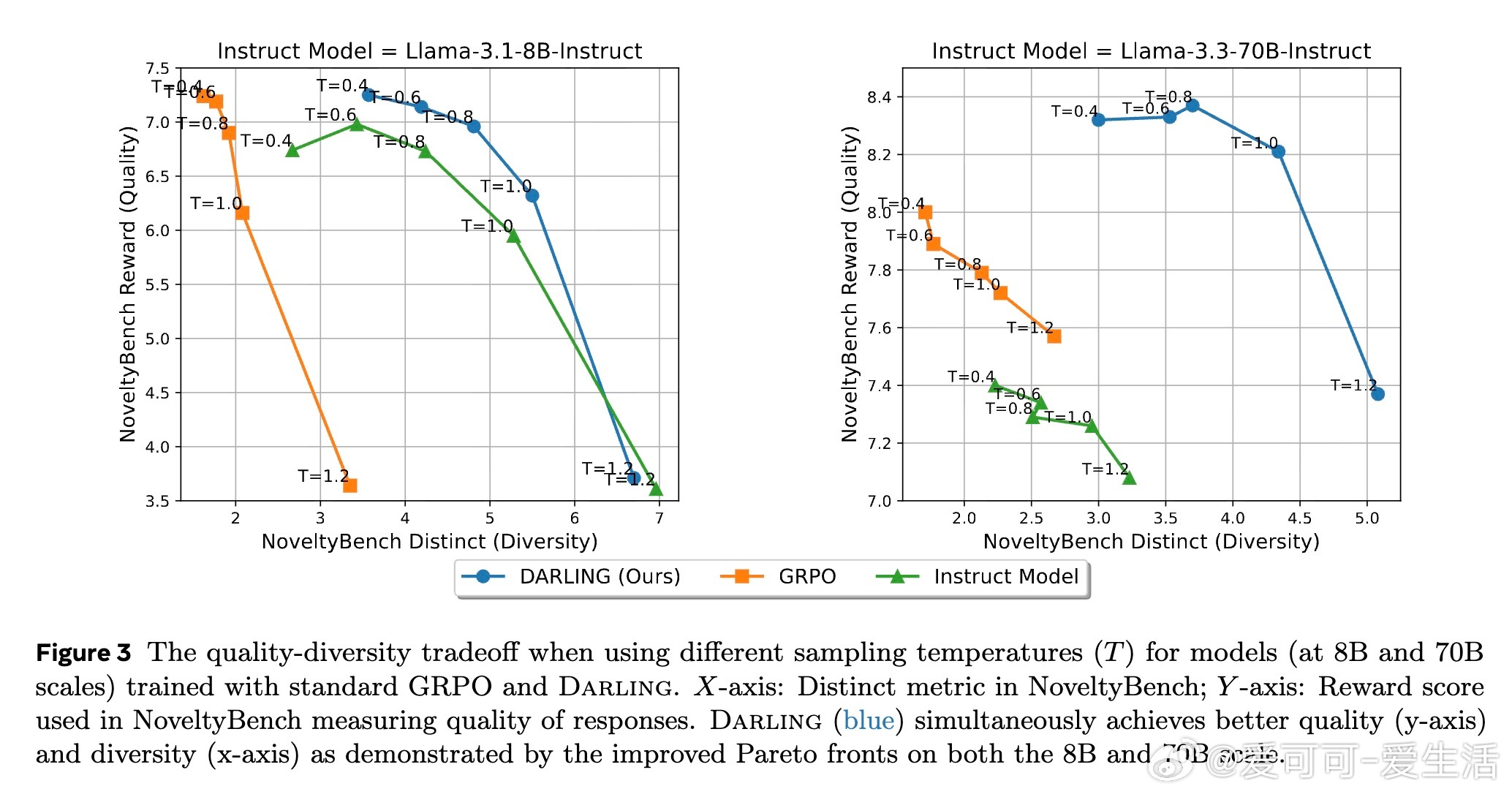
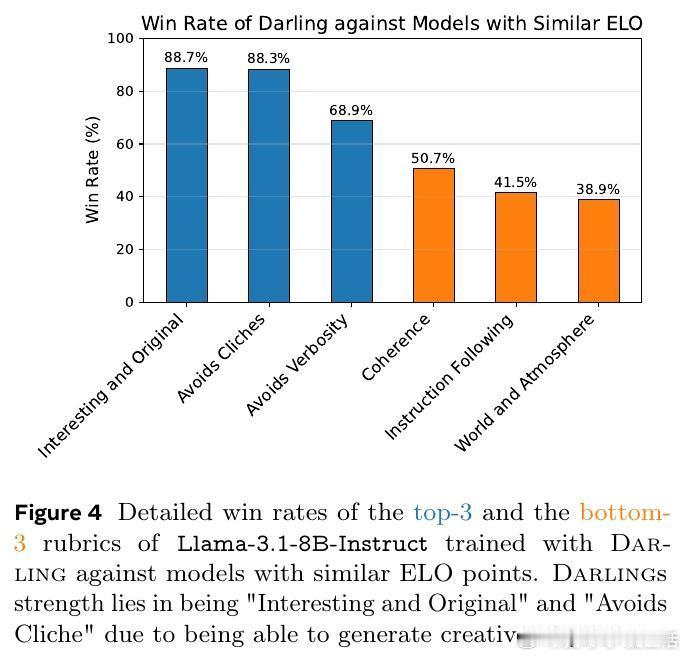
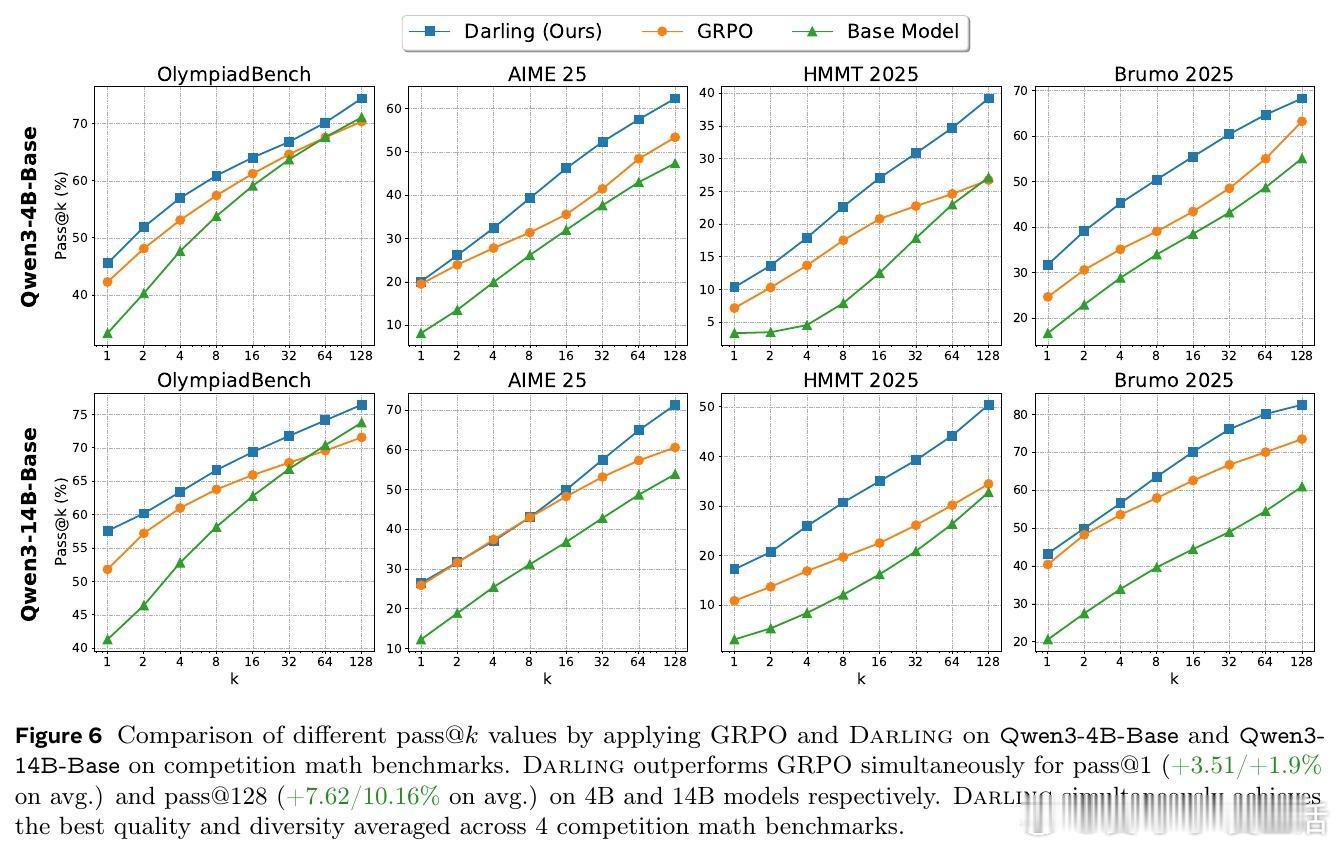
• 广泛验证:在非可验证任务(如指令跟随、创意写作)和可验证任务(数学竞赛题)上均表现优异,显著提升多样性指标(NoveltyBench Distinct)和质量指标(AlpacaEval、pass• 多样性促进探索:显式激励多样性反而促进了在线RL中的探索,进一步提升了生成质量,打破“多样性与质量难以兼得”的传统认知。
• 设计细节与消融实验:验证乘法融合优于加法、语义分类器优于简单词汇n-gram多样性、以及在密集噪声奖励场景下去除标准差归一化有助提升性能。
心得:
1. 语义层面衡量多样性有效解决了“表面多样化”难题,为多样性优化提供了更具代表性的信号。
2. 多样性与质量的乘法融合机制自然平衡了两者权重,避免了超参数调节的复杂性。
3. 多样性的提升不仅是输出多样化,更是激发模型探索行为,从而带来整体性能的协同增强。
DARLING为语言模型后训练提供了可扩展、通用且高效的多样性质量共进机制,推动了生成模型在创意、推理等多领域的实用性和创新能力。
详见🔗arxiv.org/abs/2509.02534
语言模型强化学习多样性生成模型自然语言处理