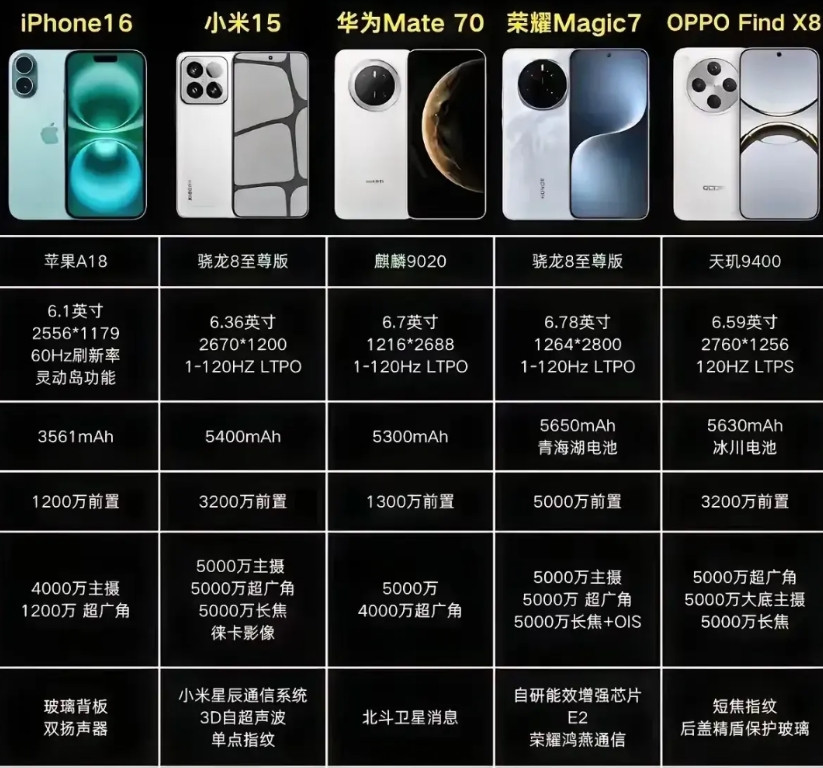
Jupyter Agent Dataset:针对数据分析与代码智能的标杆训练集,基于真实Kaggle笔记本深度加工,助力训练能够理解上下文、执行Python代码并生成逐步推理的智能代理。
• 覆盖51,389个合成笔记本,约20亿训练token,分“thinking”和“non-thinking”两大子集,兼顾不同模型需求。
• 自动去重、多阶段清洗,筛选高教育质量片段,剔除无关代码,确保数据分析相关性与实用性。
• 每条样本包含自然语言问答对、执行轨迹、原笔记本和数据集引用,支持多种Python数据处理库(pandas、numpy、matplotlib)执行。
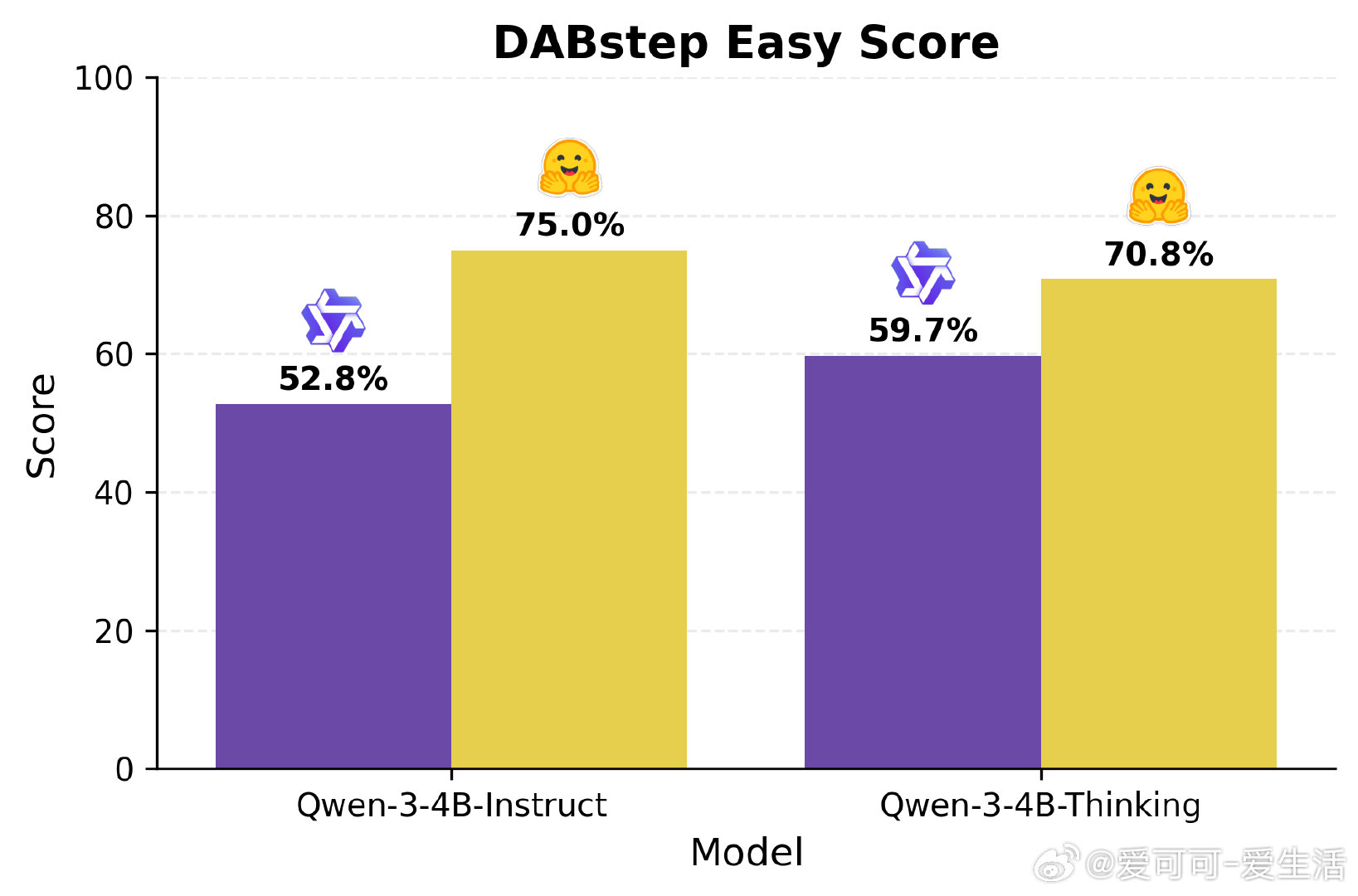
• 结合Qwen-32B评分与Qwen-Coder-480B代码生成,使用E2B沙盒环境保障代码安全可复现,提升模型20% DABstep易用性得分。
• 适合微调面向数据分析、探索性数据分析(EDA)和代码生成的LLM,显著增强复杂问题解决能力。
• 明确授权框架,遵守Kaggle原始数据集与笔记本的许可协议,专注派生QA和执行轨迹,避免数据版权风险。
三点启发🔍
1. 数据质量高于数量,精选代码片段胜过海量无关数据,显著提升模型训练效果。
2. 结构化问答与执行轨迹结合,推动模型理解推理链条而非单纯代码生成。
3. 真实环境执行验证是提升模型鲁棒性和实用性的关键,沙盒执行成为标配。
了解详情👉 huggingface.co/datasets/data-agents/jupyter-agent-dataset
机器学习 数据集 代码智能 人工智能 Python Kaggle




![雷军晒观礼请柬知名数码博主、汽车博主雷军先生[大笑][大笑][大笑]确实排面!](http://image.uczzd.cn/12834090395376637392.jpg?id=0)