[LG]《Learning to Refine: Self-Refinement of Parallel Reasoning in LLMs》Q Wang, P Zhao, S Huang, F Yang... [Microsoft] (2025)
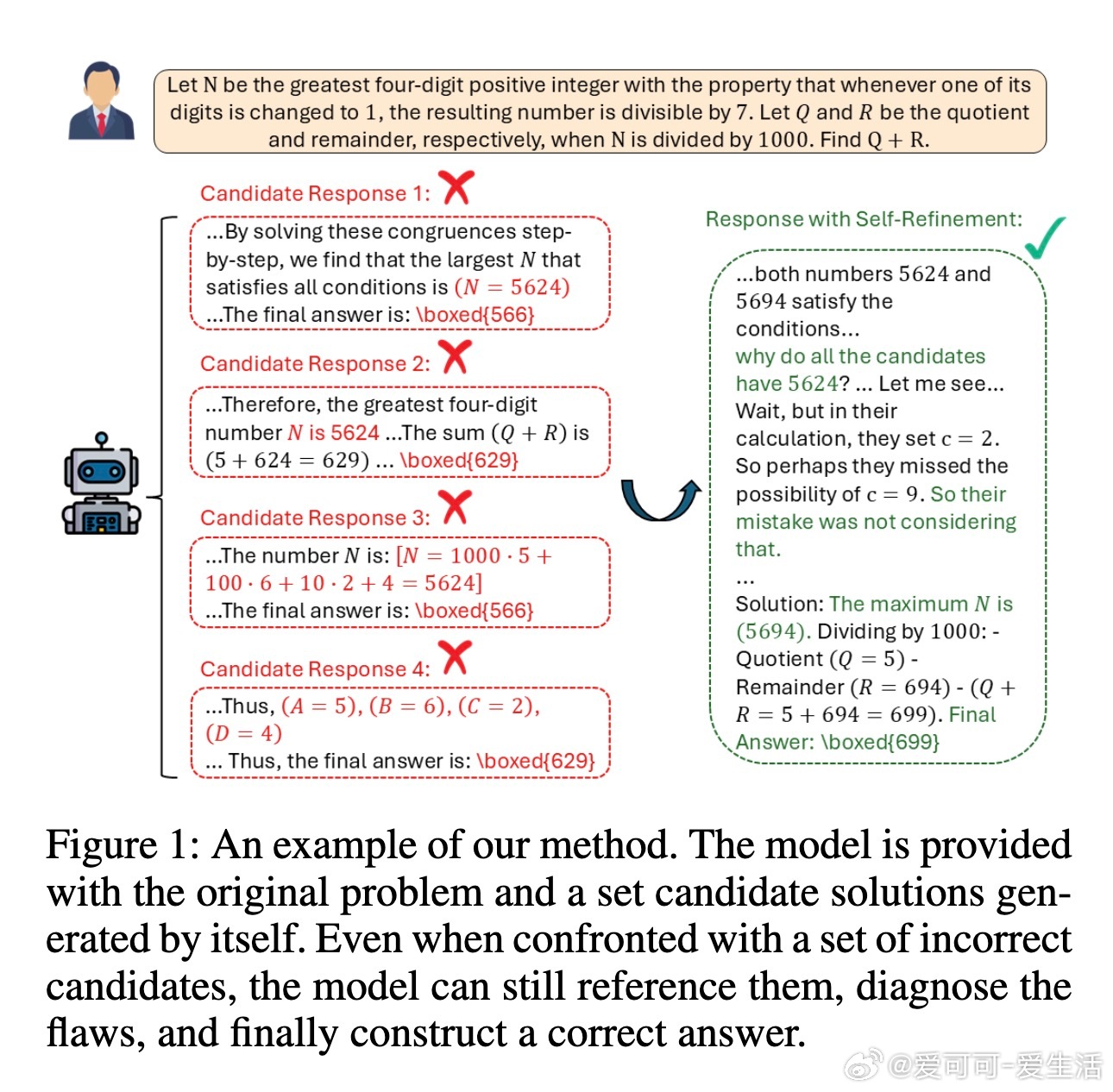
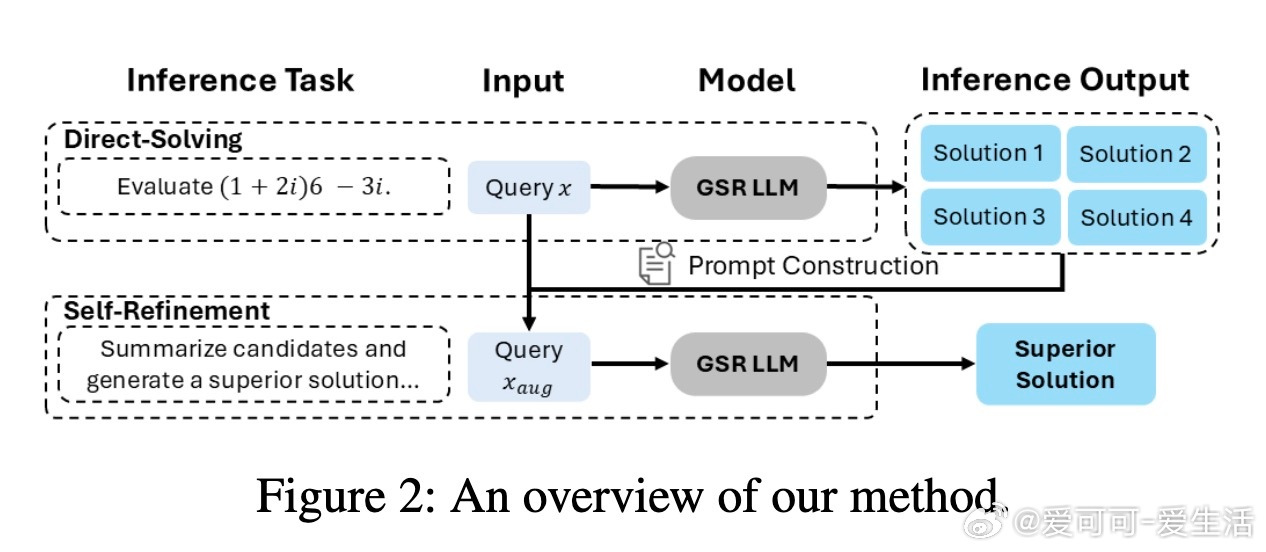
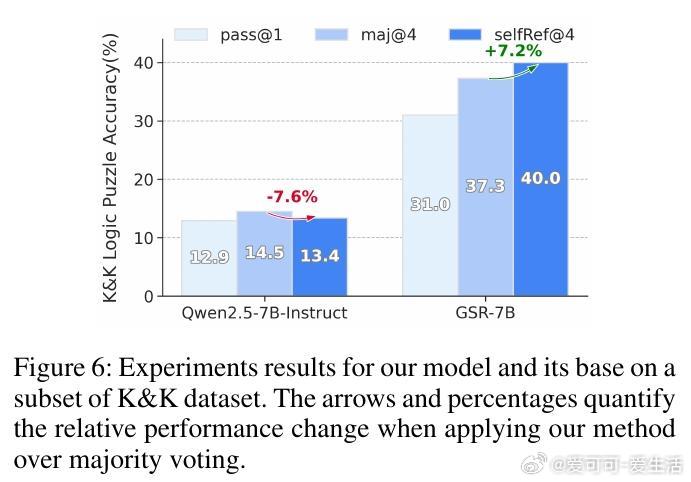
Generative Self-Refinement (GSR)为提升大型语言模型(LLMs)在复杂多步推理任务中的表现,提出了一种创新的并行测试时扩展技术。其核心思想是:模型先并行生成多组候选答案,再通过自我反思与综合,基于问题与候选答案的提示,生成更优解。
• 现有多数投票与Best-of-N方法依赖候选质量,无法突破候选答案的质量上限,且无法利用所有错误答案中的有效信息。GSR通过统一模型自我筛查并整合候选,解决此瓶颈。
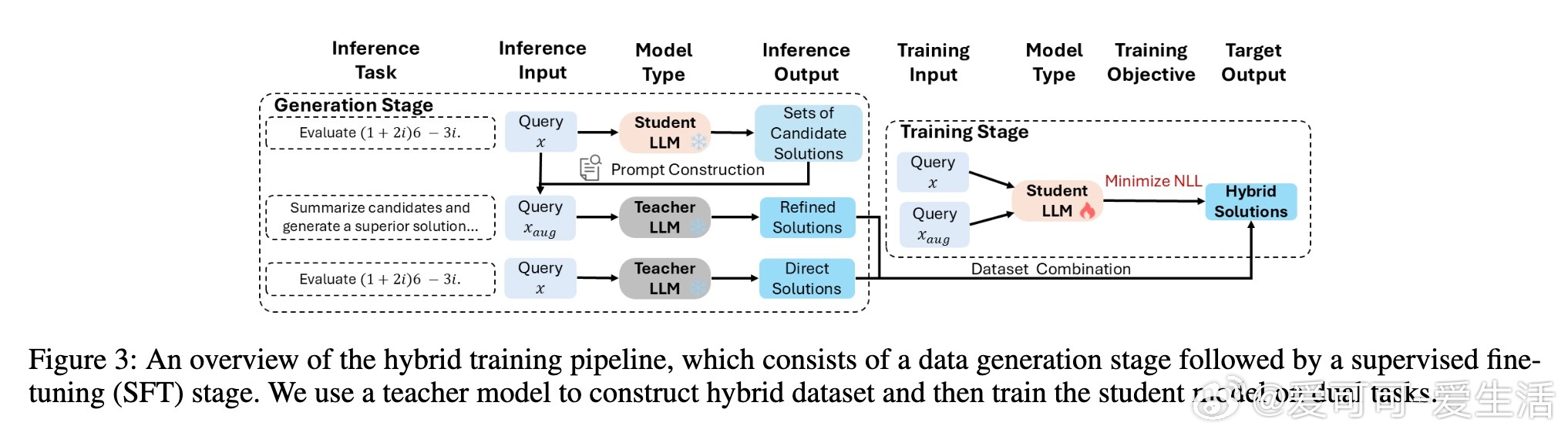
• 设计了混合训练流程,结合直接解题与自我反思两大目标,增强模型生成高质量候选及有效自我优化的双重能力,显著提升推理水平。
• 在五个数学推理基准测试中,GSR表现超越主流基线,包括多数投票、外部评估模型Best-of-N与融合模型,尤其在候选均错误时仍能部分正确解答,表现出强鲁棒性。
• 自我反思能力具备模型规模无关性,可在不同大小模型间迁移,且训练数据生成与模型不完全匹配时仍有效,体现出技能的通用性与独立于模型内部参数的特性。
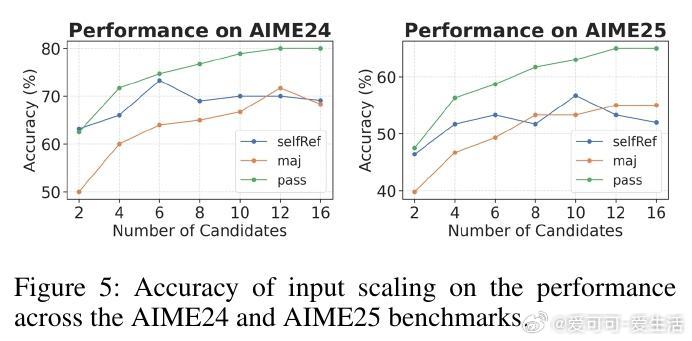
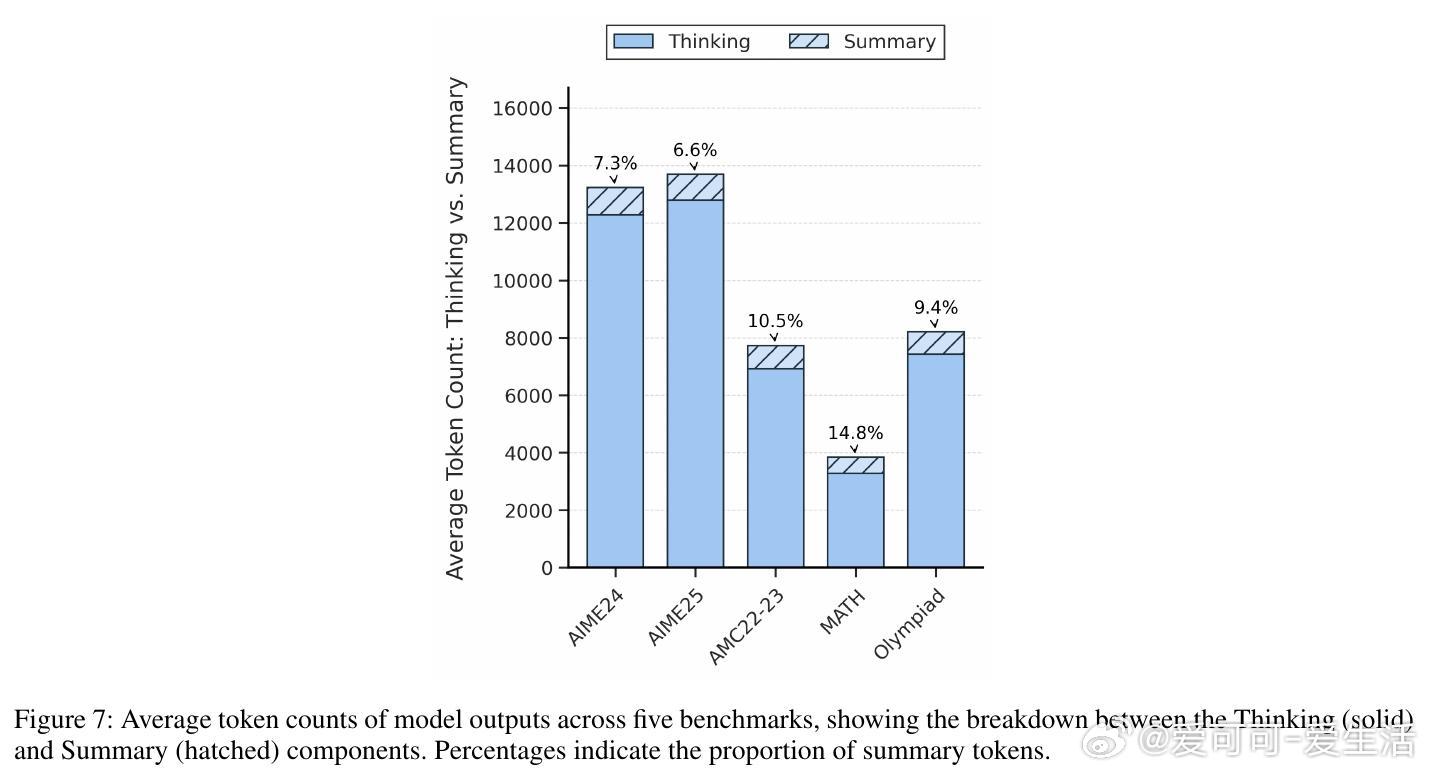
• 输入规模扩展实验表明,当候选数提升时,性能提升趋缓甚至轻微下降,提示合理控制输入复杂度对保持效果关键。
• 跨领域测试(逻辑谜题)验证了该技能的泛化能力,表明训练获得的自我反思能力适用于分布外推理任务。
心得:
1. 单一模型同时具备生成与自我优化能力,突破了传统选择性策略的局限,使推理性能获得质的飞跃。
2. 结合两种互补训练目标,既提升候选质量也强化整合能力,是实现复杂推理任务有效解法的关键。
3. 自我反思作为独立技能,能够跨模型迁移和任务泛化,预示未来更高效、通用的推理架构设计方向。
详情🔗arxiv.org/abs/2509.00084
大型语言模型推理优化自我反思测试时扩展数学推理