[LG]《When Agents go Astray: Course-Correcting SWE Agents with PRMs》S Gandhi, J Tsay, J Ganhotra, K Kate... [IBM Research & CMU] (2025)
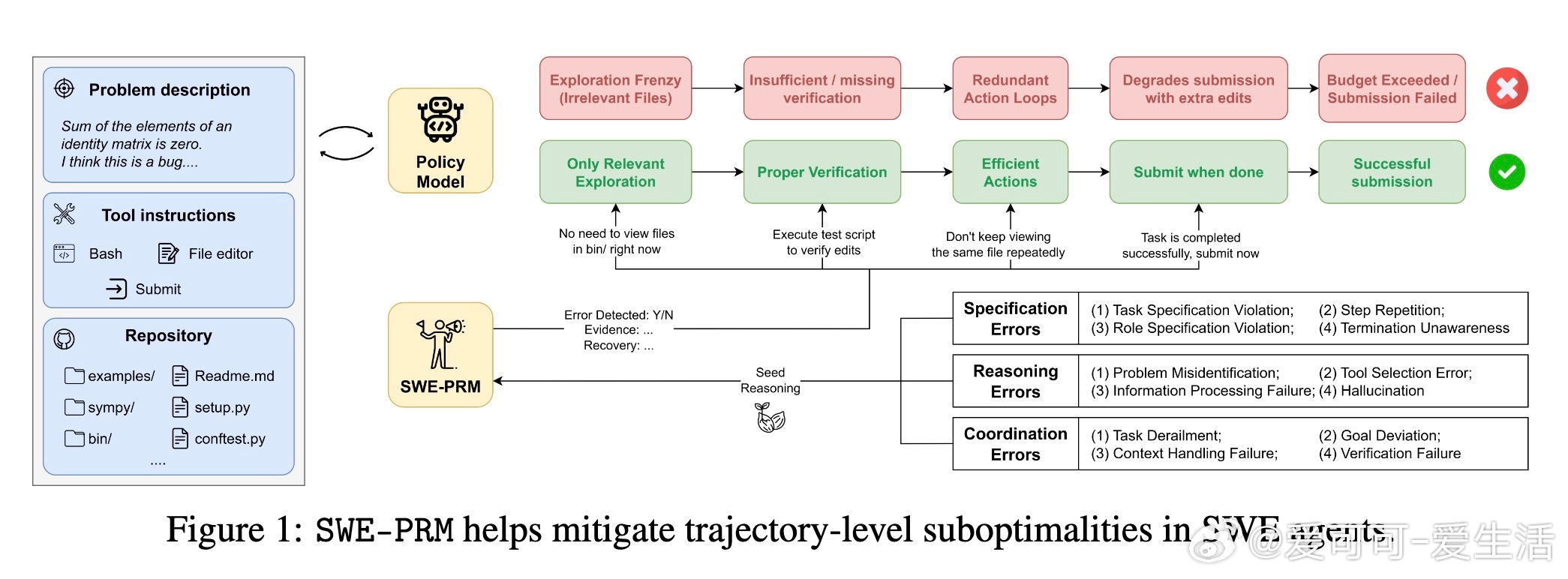
软件工程多步骤任务中,LLM代理常因轨迹低效(如循环、冗余探索、未及时终止)导致资源浪费和成功率下降。论文《Act Like You’re Paying for This: Course-Correcting Code Agents with PRMs》提出SWE-PRM,一种推理时实时介入的Process Reward Model,通过轻量且可解释的自然语言反馈,基于错误分类体系动态纠正代理执行轨迹,显著提升软件工程代理的表现和效率。
• SWE-PRM利用三大错误分类:规格错误(任务违规、重复步骤、终止判断失误)、推理错误(问题误判、工具选用错误、幻觉生成、信息处理失败)、协调错误(任务偏离、目标偏差、上下文遗忘、验证缺失),每类均配套具体纠正策略。
• PRM定期接收最近执行轨迹和任务描述,生成细致的自然语言反馈,引导代理调整下一步行为,且无需更改底层策略模型架构。
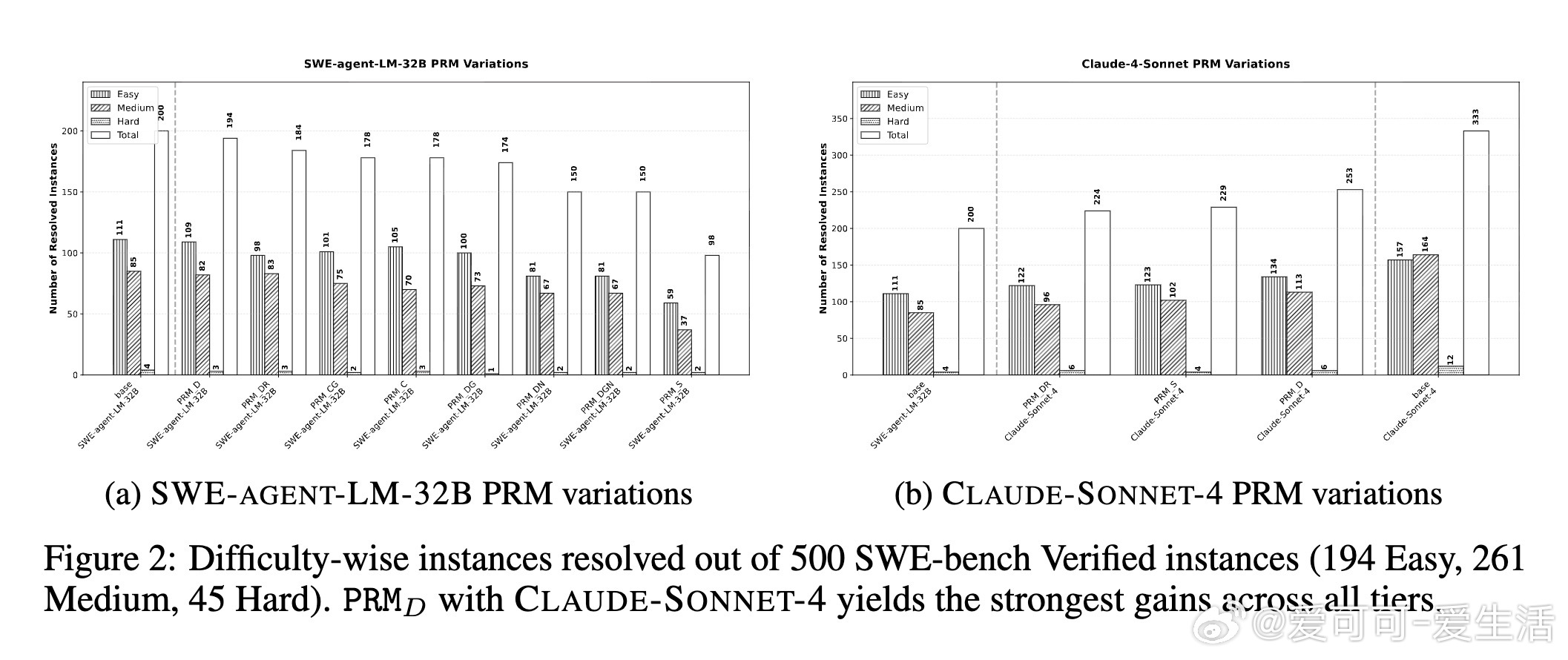
• 在SWE-bench Verified基准测试中,闭源PRM(如Claude-Sonnet-4)比开源PRM显著提升解析率(最高+10.6个百分点至50.6%),尤其在中难度任务中效果突出,同时缩短平均步骤数,提升执行效率。
• 不同反馈策略对比显示:基于分类的详细反馈(PRM-D)最优,既提升成功率又减少步骤;无指导推理(PRM-S)虽提升成功率但轨迹变长;带动作建议(PRM-DR)虽缩短轨迹但成功率下降,表明过度约束可能抑制灵活性。
• 成本方面,闭源PRM增加推理开销约至24-28美元/100实例,折合每增加一个成功案例花费约23美元,权衡精度与成本表现合理,适合复杂长周期任务优化。
心得:
1. 实时、基于分类的反馈能有效阻断错误轨迹积累,避免执行效率恶化,优于传统事后诊断。
2. 纠正策略设计需精准且灵活,过度指令可能牺牲成功率,合理平衡自由度与指导性至关重要。
3. 轻量级、模块化的PRM架构兼容多种模型,具备跨任务、跨领域推广潜力,指向未来通用多步骤推理代理的优化方向。
详情🔗arxiv.org/abs/2509.02360
人工智能软件工程大语言模型过程奖励模型自动纠错多步骤推理