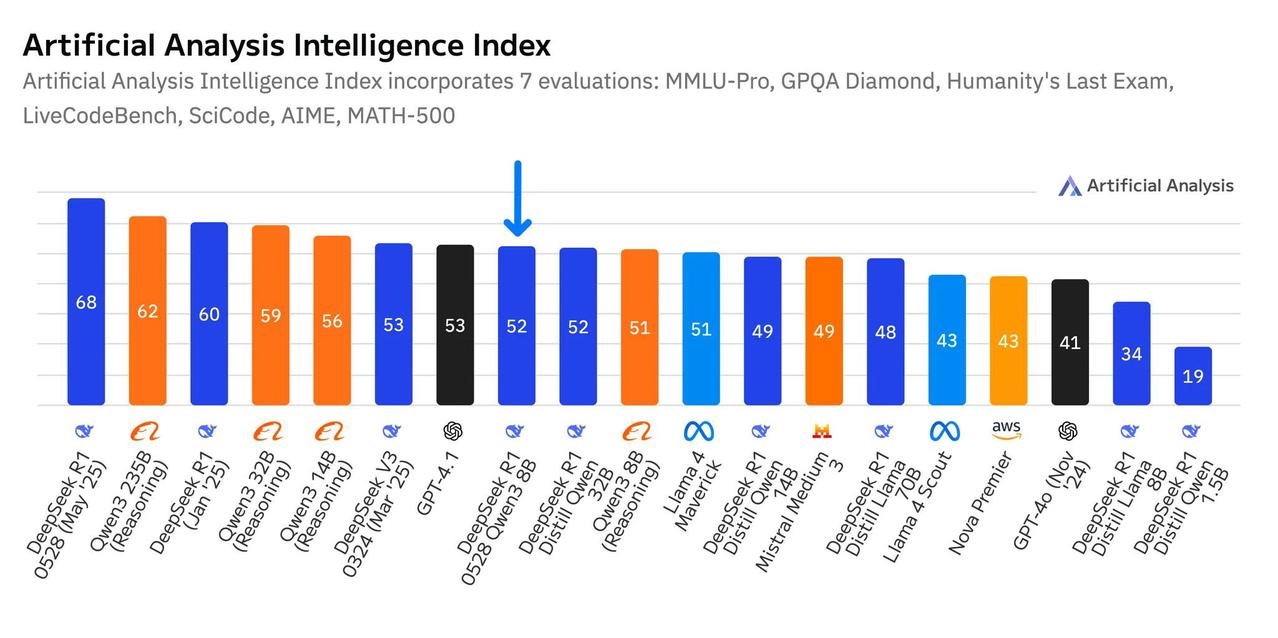
DeepSeek 的新 R1-0528-Qwen3-8B 是迄今为止最智能的 8B 参数模型,但领先优势并不大:阿里巴巴自己的 Qwen3 8B 仅落后一分 随着上周 R1-0528 的发布,DeepSeek 发布了精简版 8B 模型,旨在将其旗舰 R1 模型的高级推理能力融入更小、更易于访问的模型中,以便在设备上部署。R1-0528-Qwen3-8B 使用来自完整版 R1-0528 的推理思路链示例进行训练。 DeepSeek R1-0528-Qwen3-8B 在人工智能分析指数上获得了 52 分。 🧠与 Qwen3 8B 智能程度相当:DeepSeek 的新提取模型与阿里巴巴基于同一基础模型的后训练版本 Qwen3 8B(推理)的智能程度相当——它在人工智能分析智能指数中的得分高出一分,但这不太可能转化为实际使用中的显著提升。与阿里巴巴针对 Qwen3 系列的混合方法不同,DeepSeek 的模型不支持在推理时间上控制模型是否推理。 📈 DeepSeek R1(1 月)提炼模型的巨大飞跃:此次提炼实现了与 Qwen2.5 32B 的原始 R1 提炼版本相当的智能 - 这意味着在短短 5 个月内,现在有一个 8B 模型的表现与 1 月份 Qwen2.5 32B 提炼版本一样好。 ⚙️相较于完整版 DeepSeek R1 的效率优势:该模型仅为 DeepSeek R1 总大小的约 1.2%(8B vs. 671B)——尽管仅从 DeepSeek R1 的激活参数来看,对比结果并不那么明显,R1-0528-Qwen3-8B 为每个 token 激活了 R1 完整版参数的 21.6%(8B vs. 37B)。虽然它在原始智能方面落后于规模更大的 R1,但更小的规模使其推理速度显著加快(激活参数数量更少),并且所需内存也显著减少(总参数数量更少)。 部署和可用性: ➤ DeepSeek R1-0528-Qwen3-8B 目前由@novita_labs托管,价格为每 100 万输入/输出代币 0.06 美元/0.09 美元 ➤用户可以在单个 GPU(例如 1 x H100)或消费级硬件上部署此模型,因为它只需要约 16GB 的原生 BF16 精度内存来存储模型权重(加上用于 KV 缓存和其他开销的内存)知识分享 每天跟我涨知识 编程严选网 人工智能







![挖槽!印度人信用低,这次是踢到钉了了![笑着哭][笑着哭]深圳华强北的外贸商](http://image.uczzd.cn/13786042474008918163.jpg?id=0)