国产大模型集体上演“搬家”潮!AI开发者原来写的代码如何迁移?
2026年的春天,中国AI圈最热闹的事,不是哪家又发布了新模型,而是国内主流大模型的“集体大迁徙”:多款头部大模型先后完成训练闭环,核心任务纷纷转向国产算力底座,说明国产算力有能力接住顶流模型。
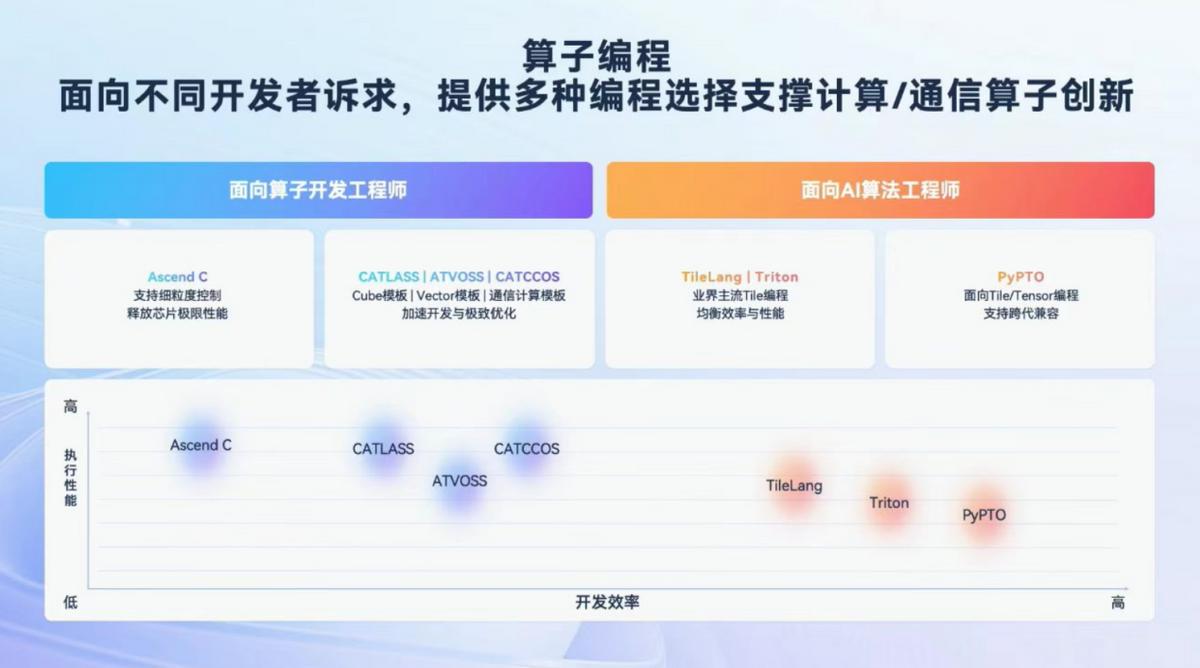
然而硬件上去了,AI开发者却犯了愁:原来在Triton上写得好好的算子,搬过来还能不能直接跑?要不要从头学一套新语言?性能会不会掉?心里全是大问号。
鲲鹏昇腾开发者大会上,昇腾给出了答案:全面兼容各类AI编程范式和编程语言,Triton、TileLang、FlagTree、Triton-TLE、DLCompiler等算子开发语言都能接住。
就拿Triton来说,昇腾的做法是直接进社区拿到原生认证:开发者原有代码直接运行,不用学新语法,不用重构管线。更实在的是,昇腾目前已支持SGLang、vLLM等600多个开源生态算子,覆盖昇腾全系列,开箱即用,大幅减少重复造轮子。而且,算子性能在不同代际芯片间保持高水平,一次开发,长期受益。这套方案已支撑万亿多模态模型训练和万亿LLM推理。
同时,针对开发者多元开发需求,昇腾TileLang提供了多级编程模式,既有开发者模式(Developer模式)帮你快速开发,也支持专家模式(Expert模式)深度调优,在数据搬运、计算与指令同步上赋予开发者更高的调优自由度。目前,DeepSeek V4的所有算子已经全面支持TileLang。
简单说:不换习惯、不换代码、不担心生态;想快有快速通道,想细有深度入口。国产算力不光接住了头部模型,也接住了开发者的工作习惯。不是开发者去想办法适配平台,而是让平台去适应开发者。
此次大会上,昇腾用全面兼容的编程生态,给开发者带来了一剂定心丸。随着昇腾生态不断发展,还将进一步降低开发门槛、提升开发效率,让更多开发者轻松上手。