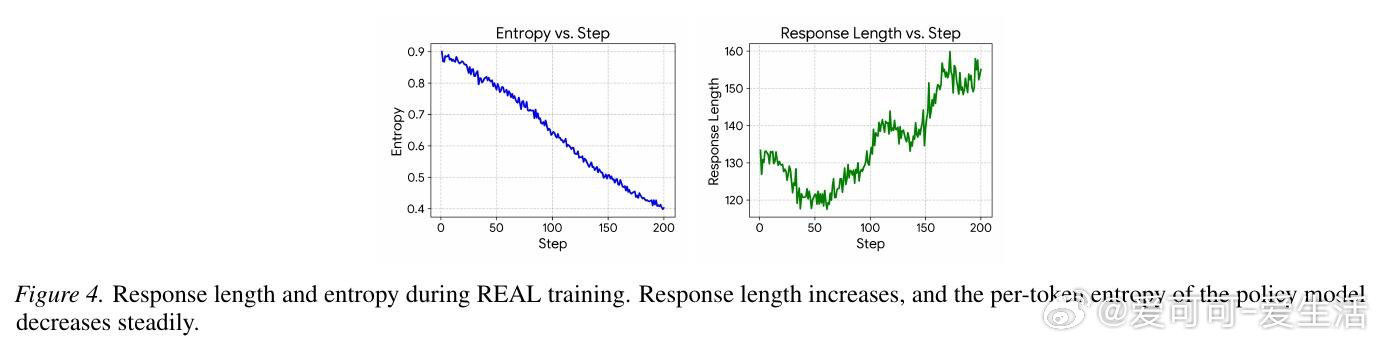
[LG]《REAL: Regression-Aware Reinforcement Learning for LLM-as-a-Judge》Y Zhang, T Chen, M Zhou, O Leong… [University of California, Los Angeles & The University of Texas at Austin] (2026)
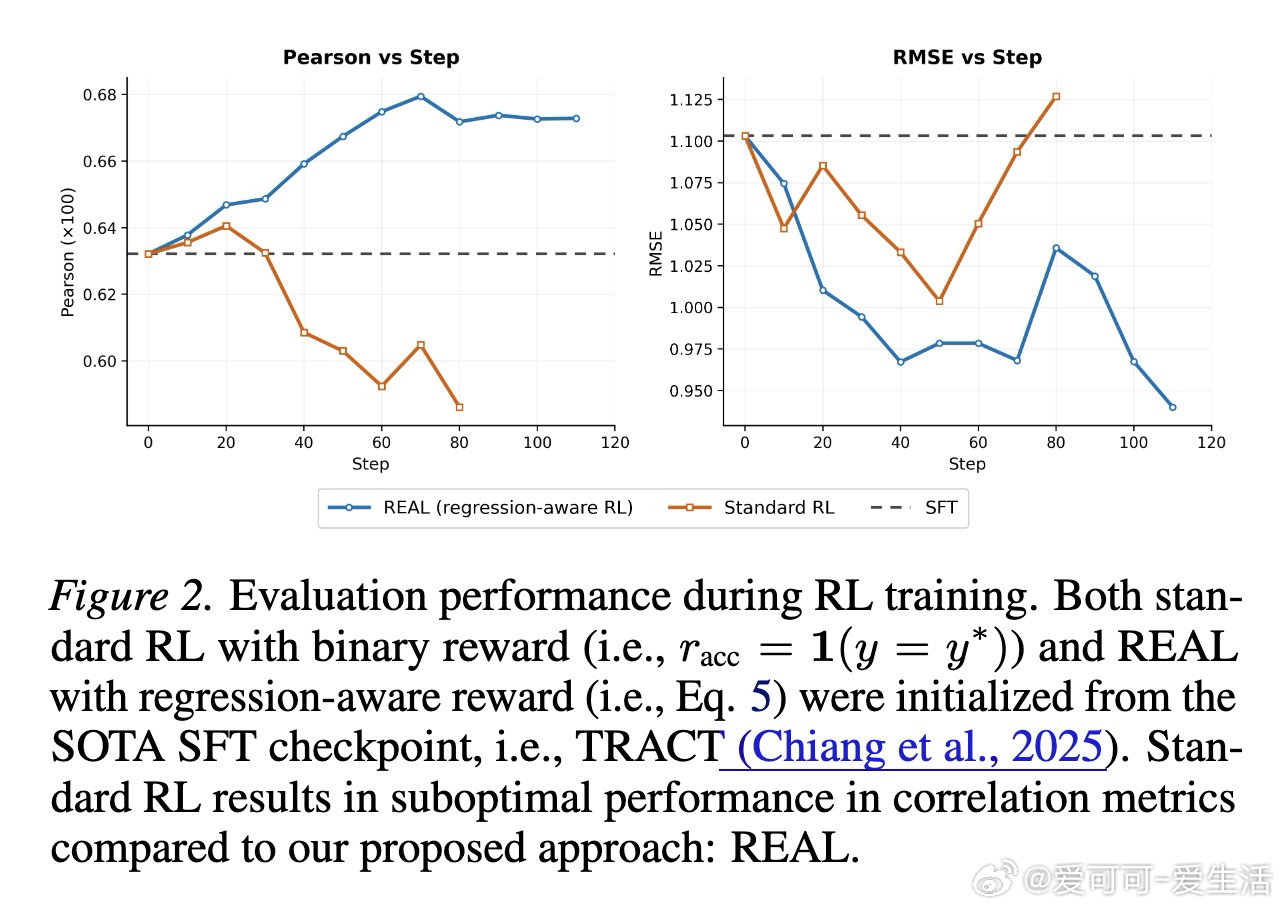
在LLM-as-a-Judge领域,用大模型自动打分时,如何让训练过程真正理解"4分比1分更接近5分"是一个悬而未决的难题。过去的强化学习方法依赖0/1二元奖励,将数值评分视为离散类别,根本无视分数间的序数距离;而回归感知的监督微调方法虽能感知这一结构,却被锁死在静态数据集中,无法探索模型自己生成的推理路径。
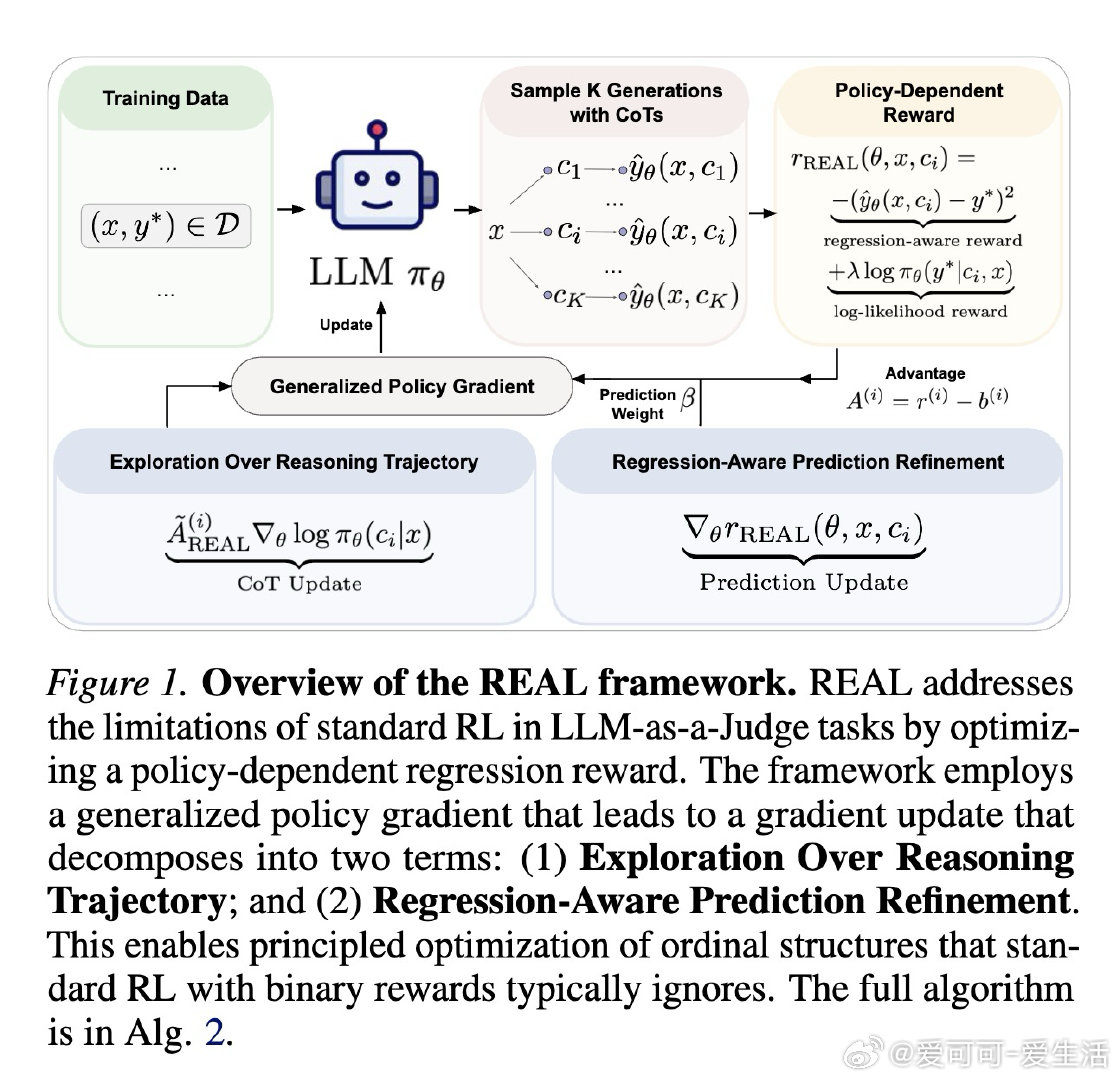
本文的核心洞见是:把"奖励函数"重新看作策略参数的显式函数,而非固定的外部信号。这一认知跳跃使标准策略梯度失效,但借助广义策略梯度,问题自然分解为两个互补项——一项用回归奖励引导思维链探索,一项直接对最终预测值做回归监督。两条更新路径各司其职,共同优化一个统一目标。
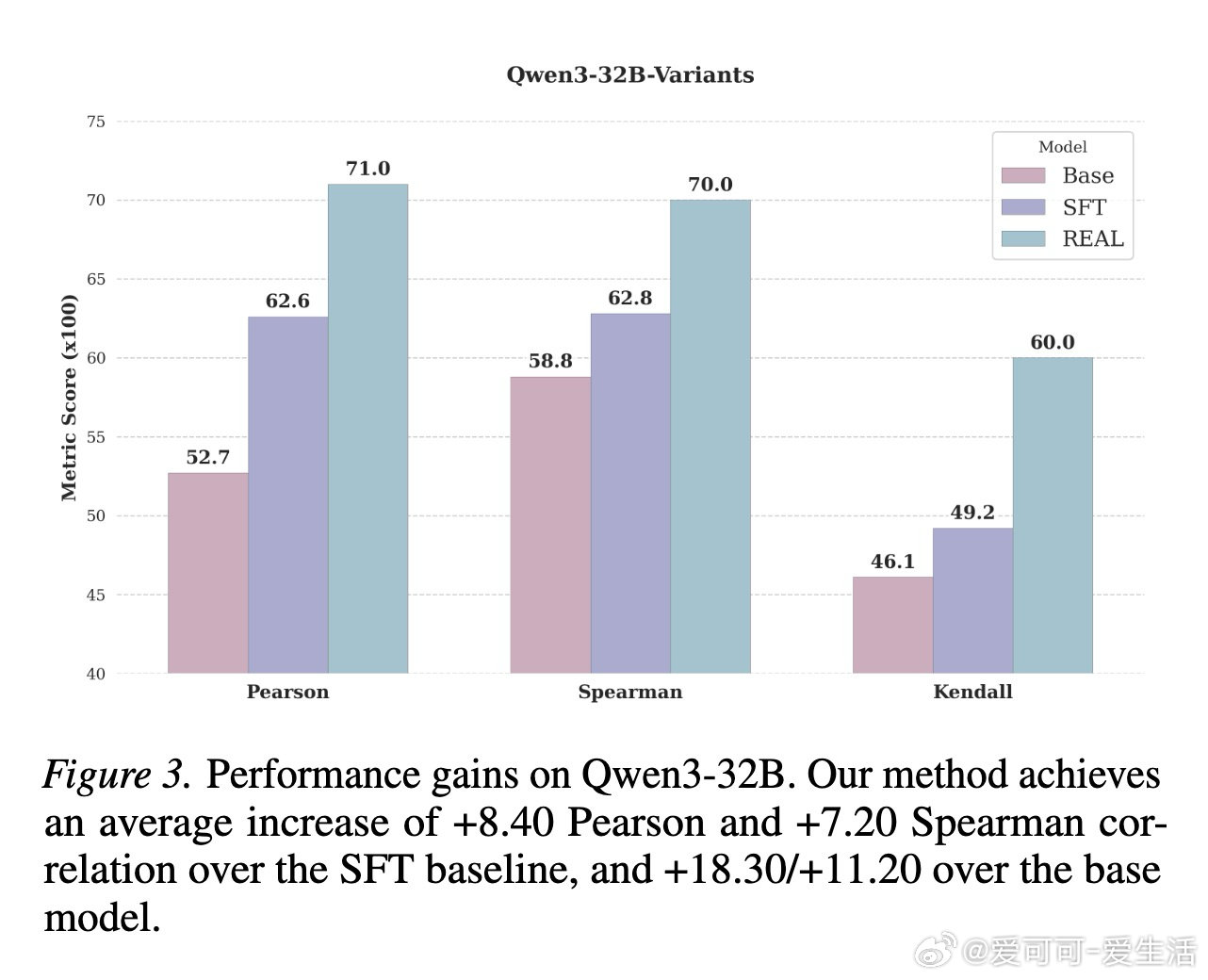
这项工作真正留下的遗产是:证明了最小化均方误差等价于最优化Pearson相关性,从而为数值型评估任务的强化学习提供了理论支撑。它为后来者打开的新门是:将连续回归目标嵌入RL训练主循环,使跨域泛化能力显著超越监督微调范式。但尚未跨过的门槛是:框架仍局限于逐点评分,尚未触及成对偏好比较,且思维链中的系统性偏差会随训练自我强化。
arxiv.org/abs/2603.17145
机器学习 人工智能 论文 AI创造营